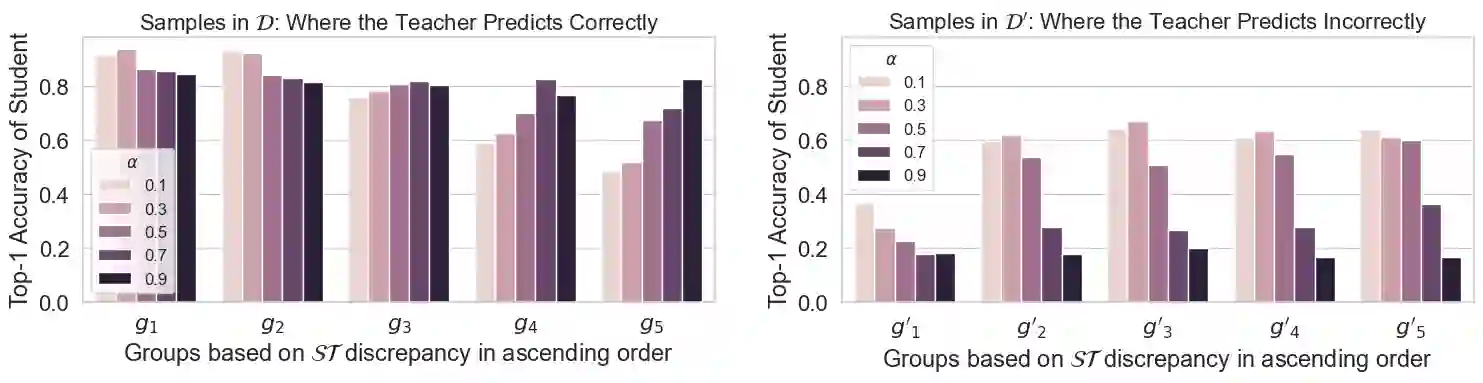
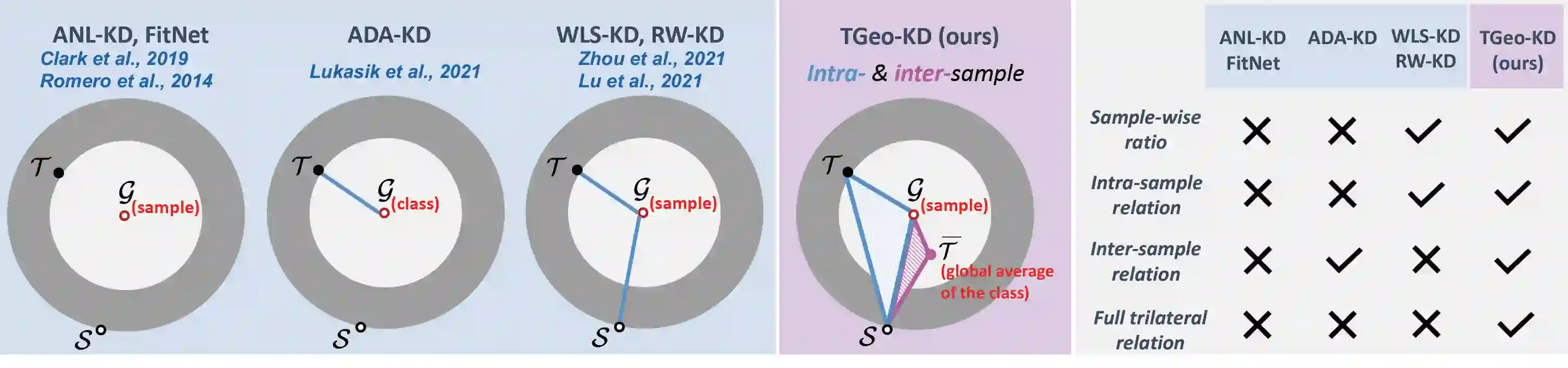
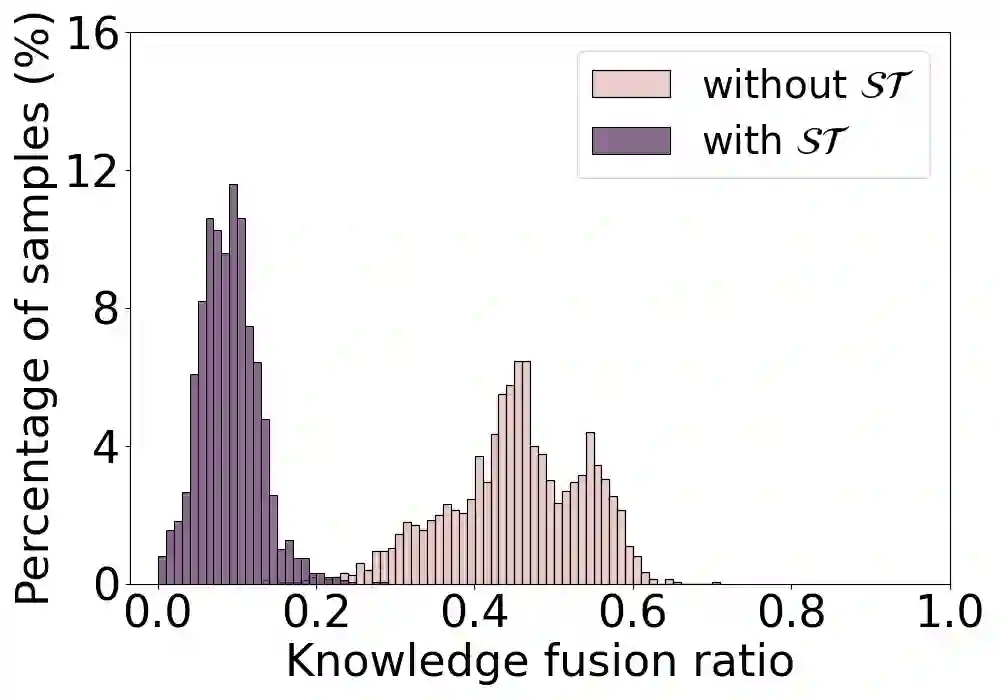
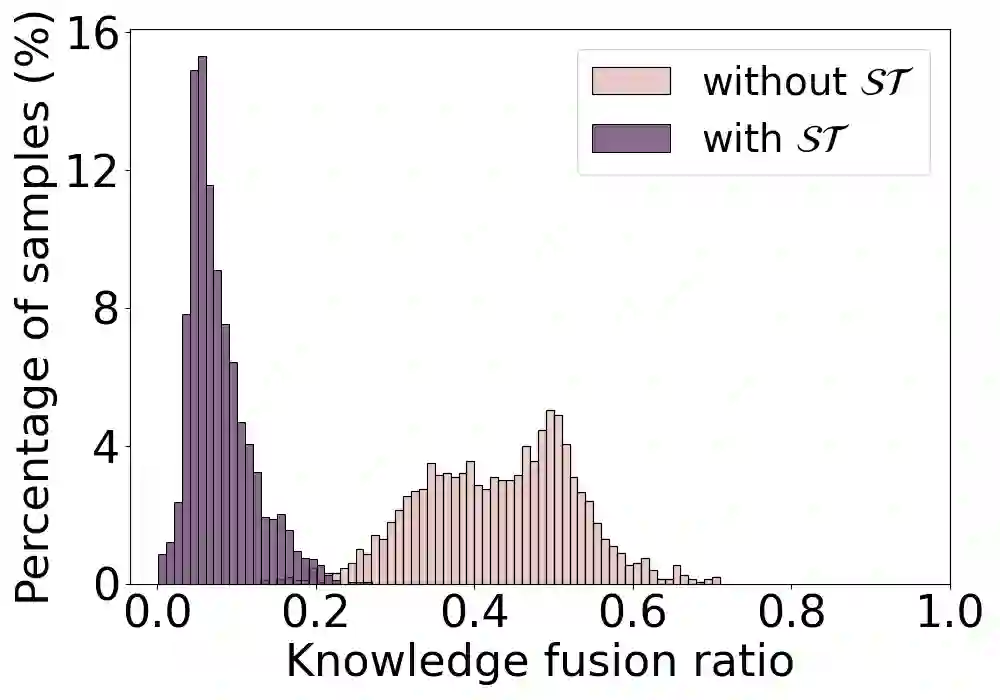
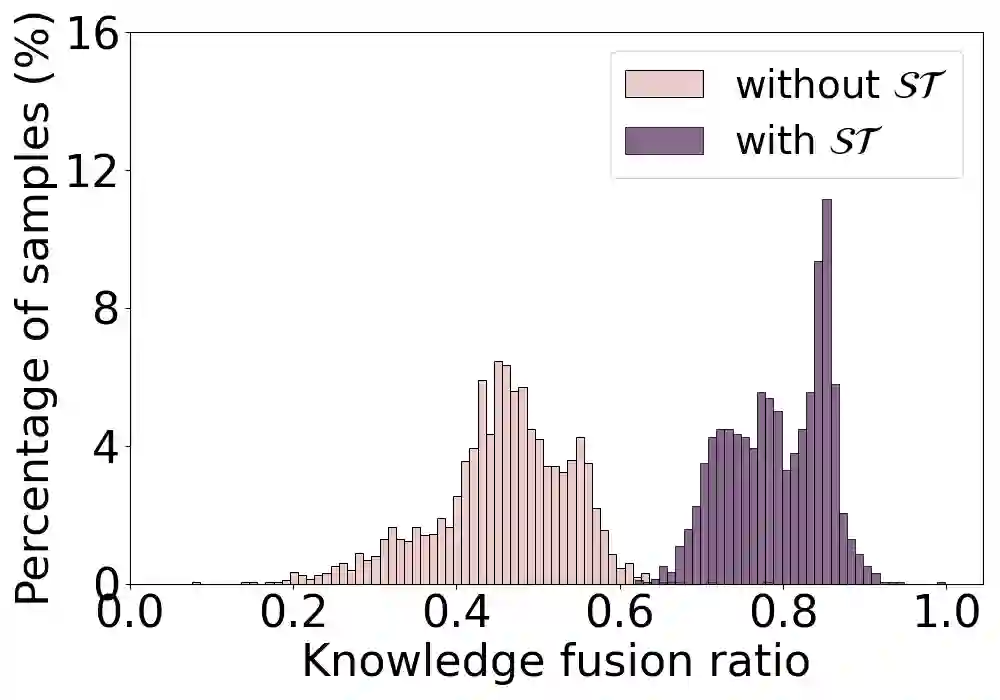
Knowledge distillation aims to train a compact student network using soft supervision from a larger teacher network and hard supervision from ground truths. However, determining an optimal knowledge fusion ratio that balances these supervisory signals remains challenging. Prior methods generally resort to a constant or heuristic-based fusion ratio, which often falls short of a proper balance. In this study, we introduce a novel adaptive method for learning a sample-wise knowledge fusion ratio, exploiting both the correctness of teacher and student, as well as how well the student mimics the teacher on each sample. Our method naturally leads to the intra-sample trilateral geometric relations among the student prediction ($S$), teacher prediction ($T$), and ground truth ($G$). To counterbalance the impact of outliers, we further extend to the inter-sample relations, incorporating the teacher's global average prediction $\bar{T}$ for samples within the same class. A simple neural network then learns the implicit mapping from the intra- and inter-sample relations to an adaptive, sample-wise knowledge fusion ratio in a bilevel-optimization manner. Our approach provides a simple, practical, and adaptable solution for knowledge distillation that can be employed across various architectures and model sizes. Extensive experiments demonstrate consistent improvements over other loss re-weighting methods on image classification, attack detection, and click-through rate prediction.
翻译:知识蒸馏旨在利用大型教师网络的软监督和真实标签的硬监督训练紧凑的学生网络。然而,如何确定平衡这些监督信号的最优知识融合比仍具挑战性。现有方法通常采用恒定或基于启发式的融合比,往往难以实现适当平衡。本研究提出一种新颖的自适应方法,通过学习逐样本的知识融合比,同时利用教师和学生的正确性以及学生模仿教师每个样本的程度。该方法自然形成了学生预测($S$)、教师预测($T$)和真实标签($G$)之间的样本内三边几何关系。为抵消异常值的影响,我们进一步扩展到样本间关系,融入同类别样本中教师全局平均预测$\bar{T}$。随后,一个简单的神经网络以双层优化的方式学习从样本内和样本间关系到自适应逐样本知识融合比的隐式映射。我们的方法为知识蒸馏提供了简单、实用且自适应的解决方案,可适用于各种架构和模型规模。大量实验表明,在图像分类、攻击检测和点击率预测任务上,该方法相比其他损失重加权方法实现了持续改进。