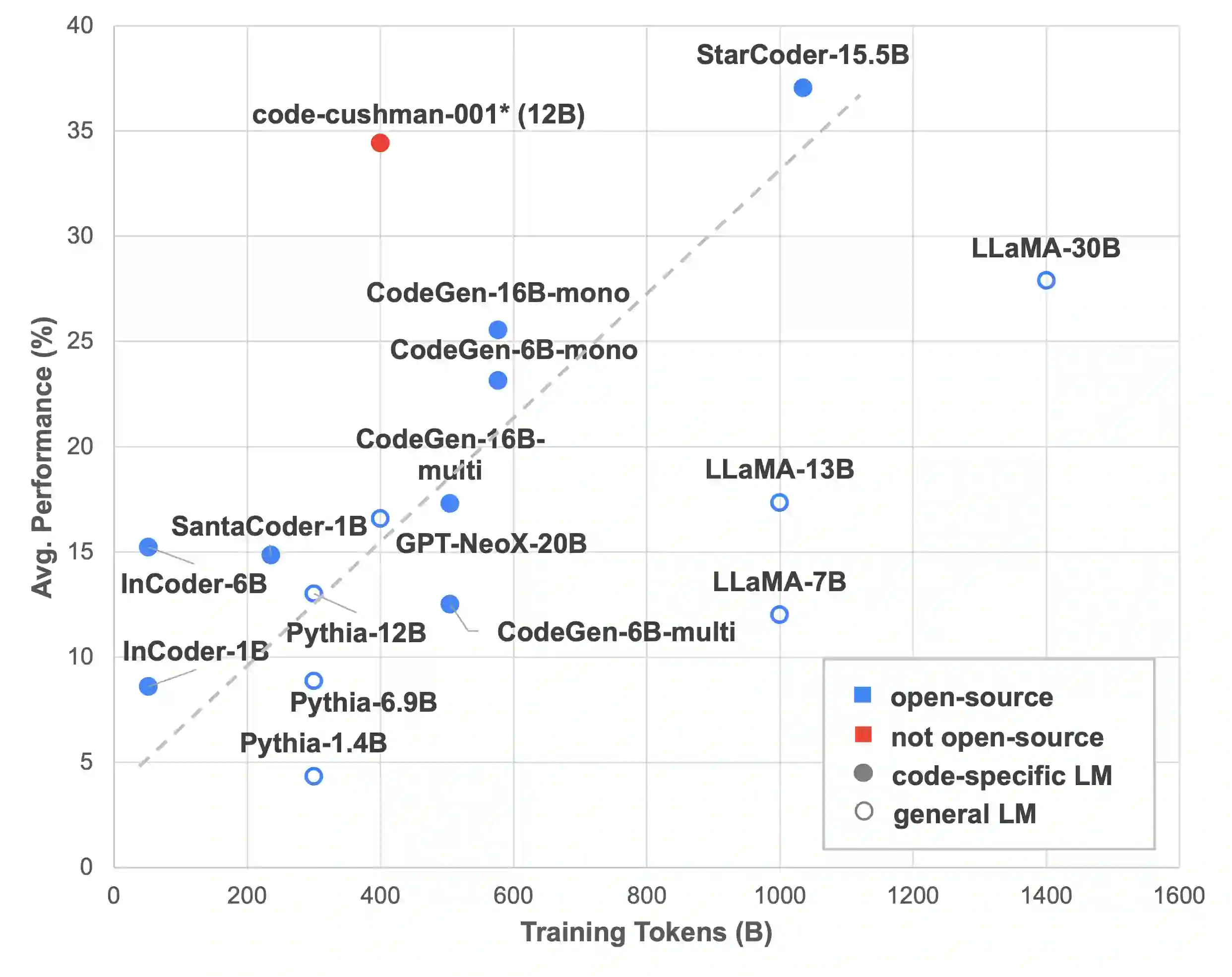
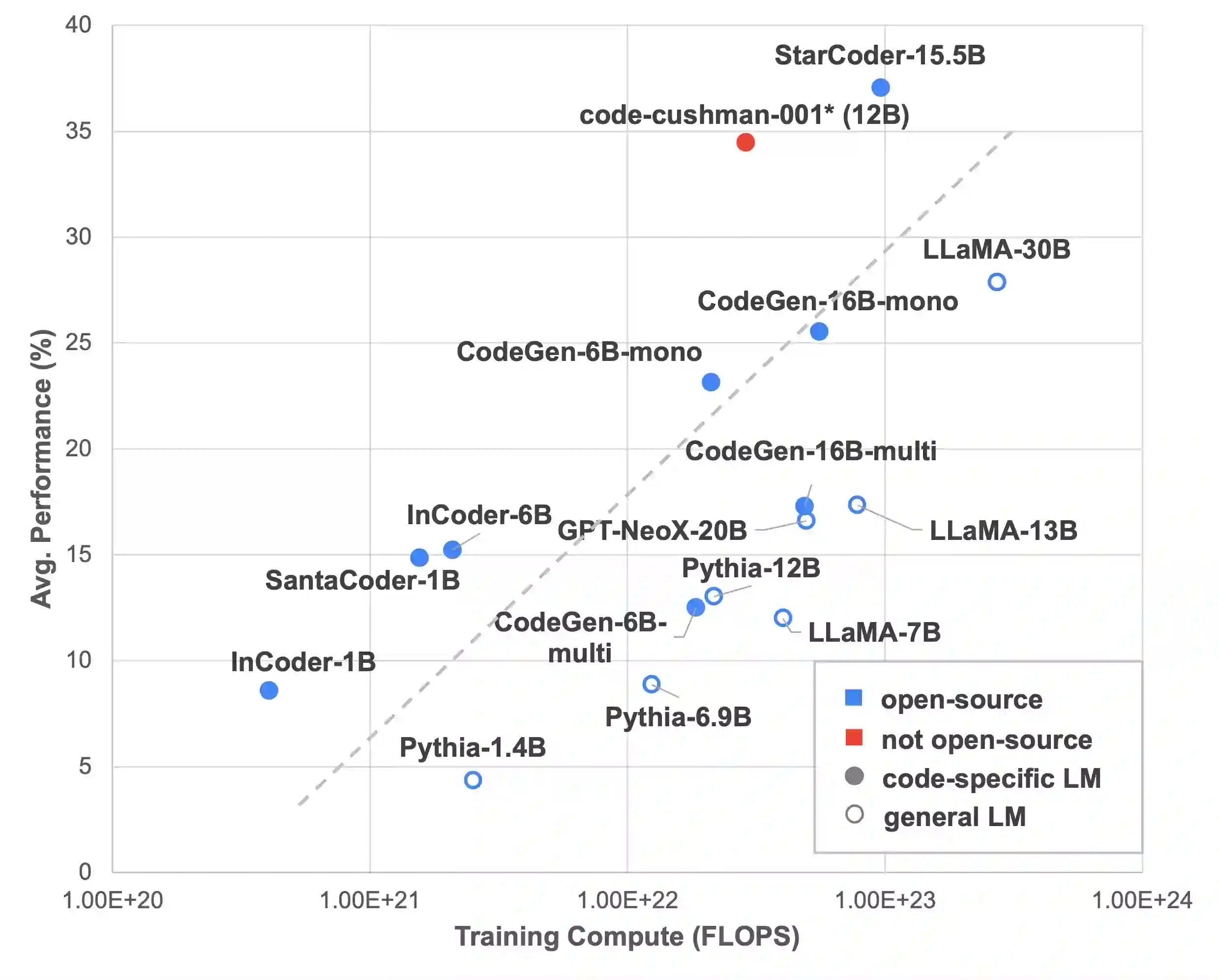
Recently, large language models (LLMs), especially those that are pretrained on code, have demonstrated strong capabilities in generating programs from natural language inputs in a few-shot or even zero-shot manner. Despite promising results, there is a notable lack of a comprehensive evaluation of these models language-to-code generation capabilities. Existing studies often focus on specific tasks, model architectures, or learning paradigms, leading to a fragmented understanding of the overall landscape. In this work, we present L2CEval, a systematic evaluation of the language-to-code generation capabilities of LLMs on 7 tasks across the domain spectrum of semantic parsing, math reasoning and Python programming, analyzing the factors that potentially affect their performance, such as model size, pretraining data, instruction tuning, and different prompting methods. In addition to assessing model performance, we measure confidence calibration for the models and conduct human evaluations of the output programs. This enables us to identify and analyze the typical failure modes across various tasks and models. L2CEval offers a comprehensive understanding of the capabilities and limitations of LLMs in language-to-code generation. We also release the evaluation framework and all model outputs, hoping to lay the groundwork for further future research in this domain.
翻译:近期,大型语言模型(LLMs),尤其是那些在代码上预训练的模型,已展现出在少样本甚至零样本场景下,从自然语言输入生成程序的强大能力。尽管取得了令人瞩目的成果,但目前对这些模型在语言到代码生成方面的能力仍缺乏全面评估。现有研究往往聚焦于特定任务、模型架构或学习范式,导致对整体格局的理解较为零散。本文提出了L2CEval,这是一项针对LLMs在语义解析、数学推理与Python编程这7个任务上的语言到代码生成能力的系统性评估,并分析了可能影响其表现的因素,如模型规模、预训练数据、指令微调及不同的提示方法。除评估模型性能外,我们还对模型进行了置信度校准测量,并对生成的程序进行了人工评估。这使我们能够识别并分析不同任务与模型中的典型失败模式。L2CEval提供了对LLMs在语言到代码生成中的能力与局限性的全面理解。我们同时发布了评估框架及所有模型输出,期望为该领域的后续研究奠定基础。