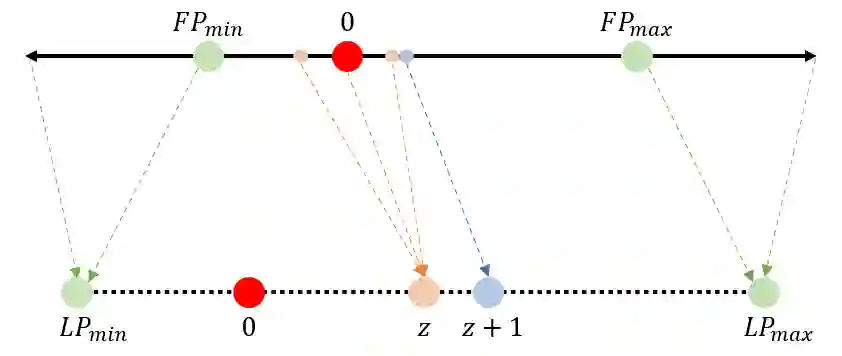
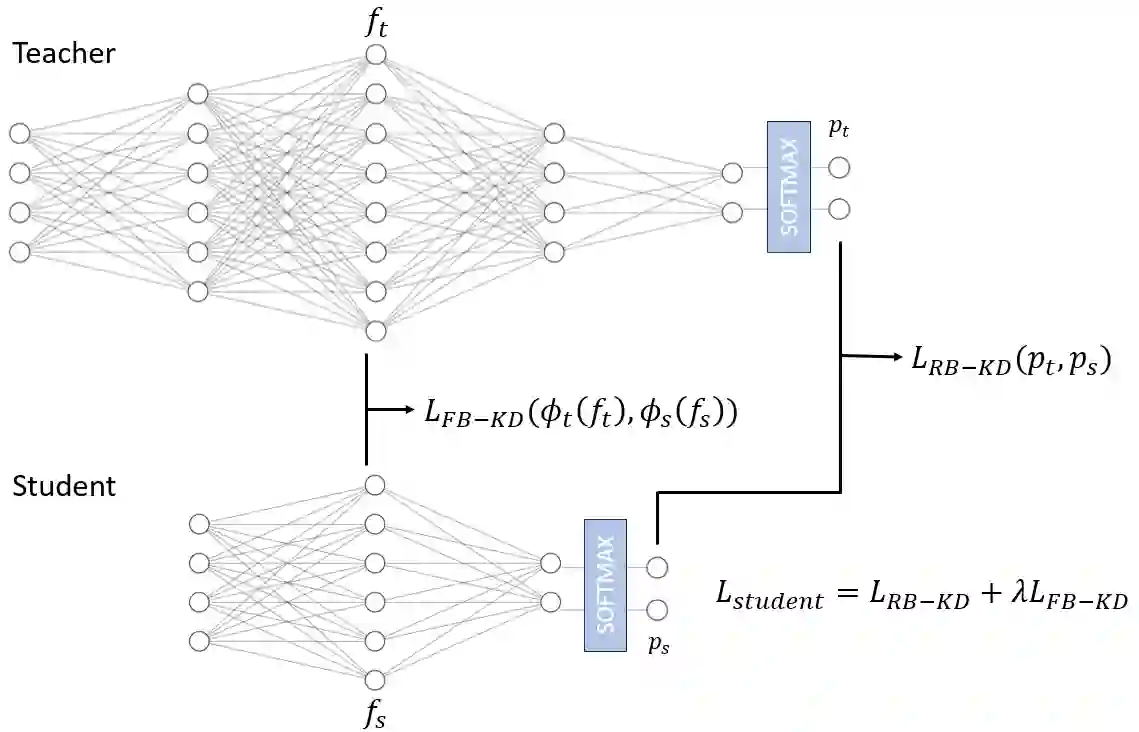
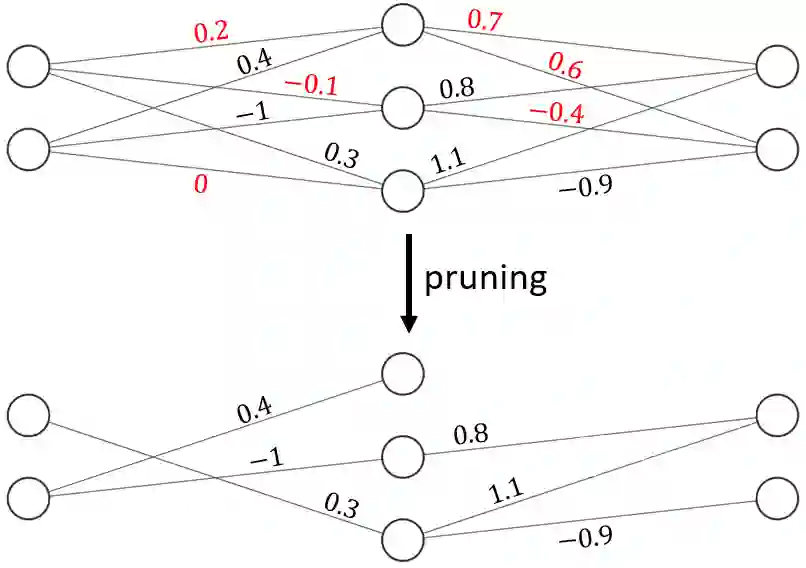
The development of deep learning algorithms has extensively empowered humanity's task automatization capacity. However, the huge improvement in the performance of these models is highly correlated with their increasing level of complexity, limiting their usefulness in human-oriented applications, which are usually deployed in resource-constrained devices. This led to the development of compression techniques that drastically reduce the computational and memory costs of deep learning models without significant performance degradation. This paper aims to systematize the current literature on this topic by presenting a comprehensive survey of model compression techniques in biometrics applications, namely quantization, knowledge distillation and pruning. We conduct a critical analysis of the comparative value of these techniques, focusing on their advantages and disadvantages and presenting suggestions for future work directions that can potentially improve the current methods. Additionally, we discuss and analyze the link between model bias and model compression, highlighting the need to direct compression research toward model fairness in future works.
翻译:深度学习算法的发展极大地提升了人类任务自动化的能力。然而,这些模型性能的显著提升与其日益增长的复杂性高度相关,这限制了它们在通常部署于资源受限设备的人机交互应用中的实用性。为此,研究者开发了压缩技术,在无明显性能下降的前提下大幅降低深度学习模型的计算和存储成本。本文旨在系统梳理当前相关文献,对生物特征识别应用中的模型压缩技术(即量化、知识蒸馏和剪枝)进行综述。我们批判性地分析了这些技术的比较价值,重点关注其优缺点,并提出了有望改进现有方法的未来研究方向。此外,我们讨论并分析了模型偏差与模型压缩之间的关联,强调了未来研究需将压缩技术导向模型公平性的必要性。