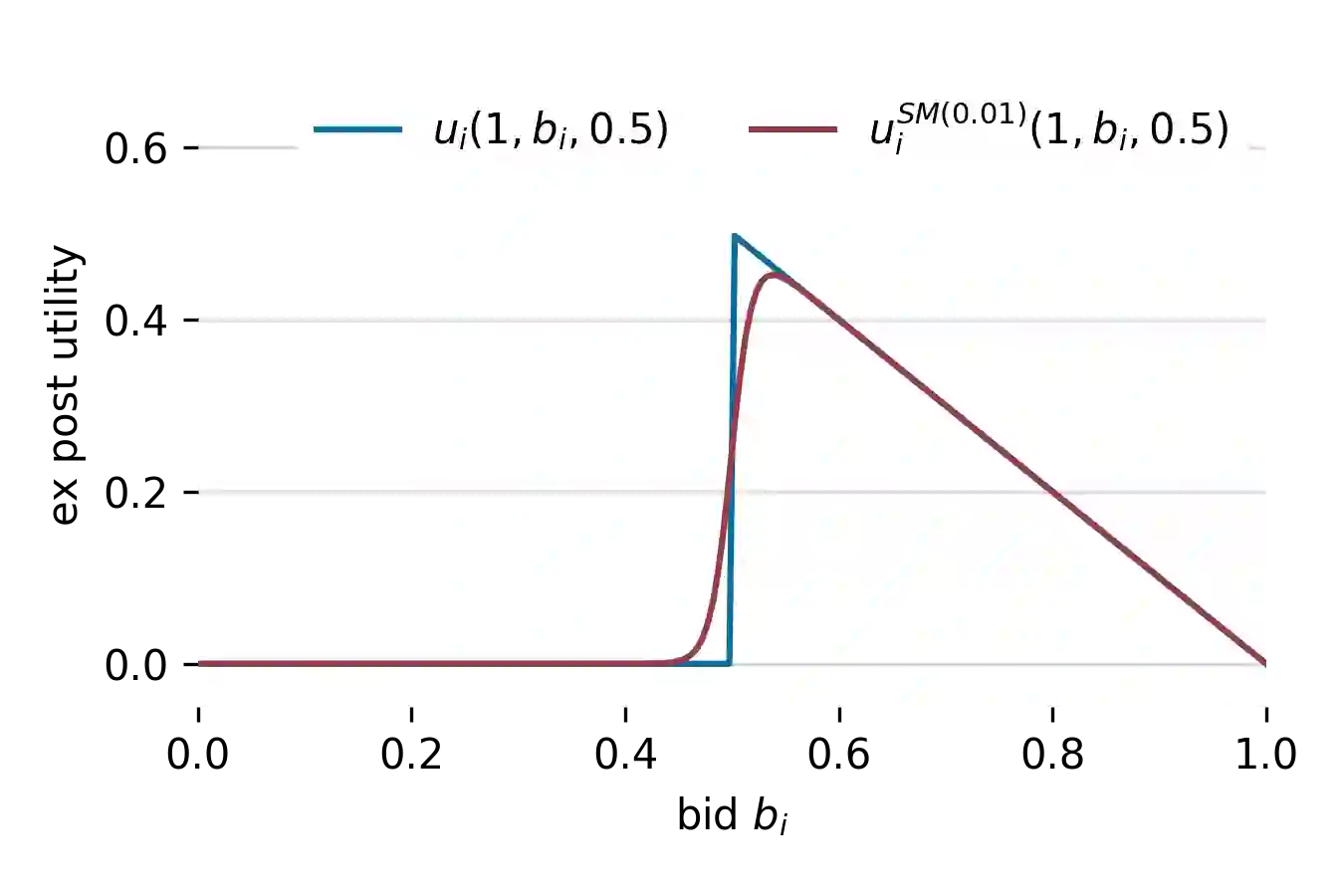
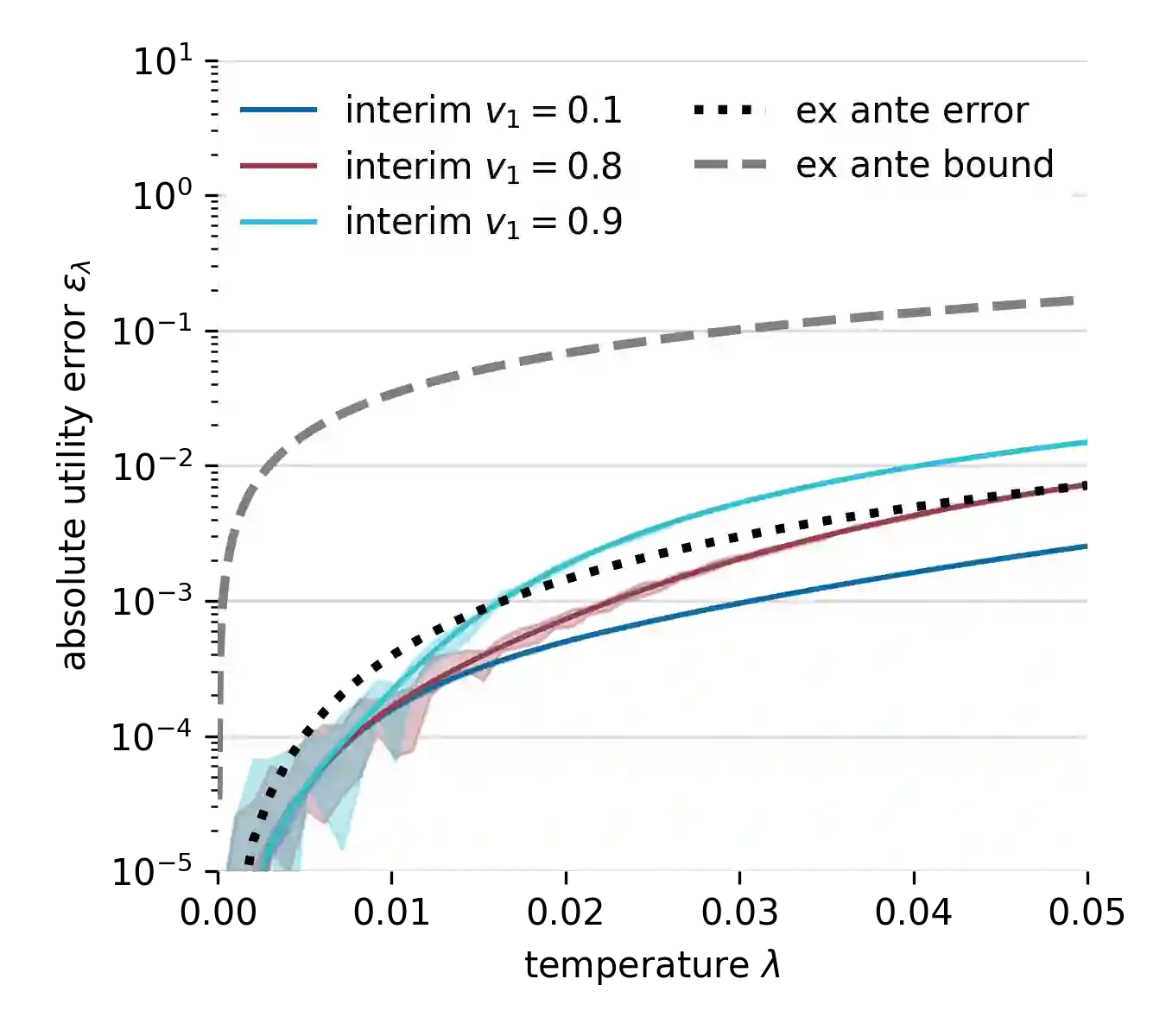
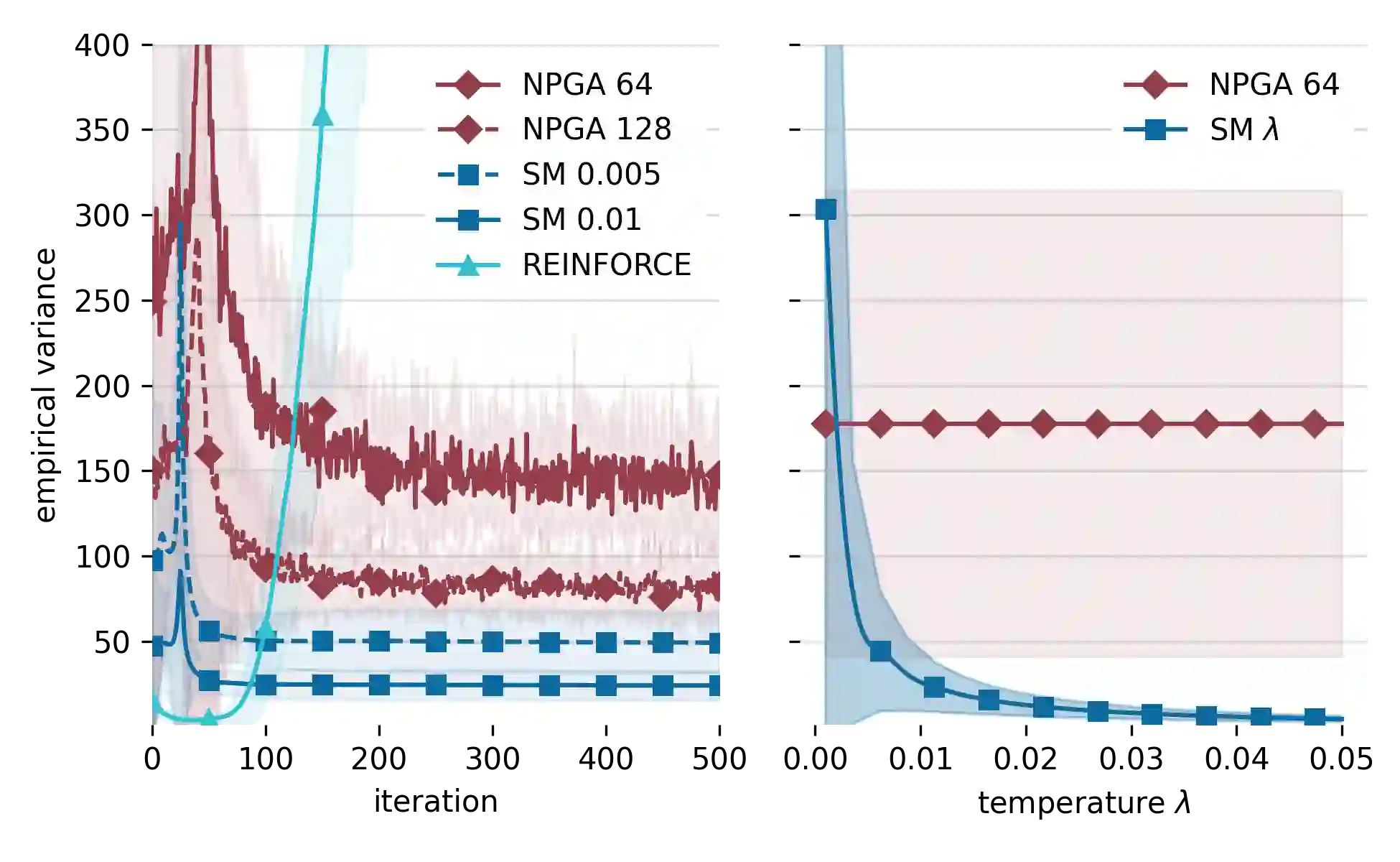
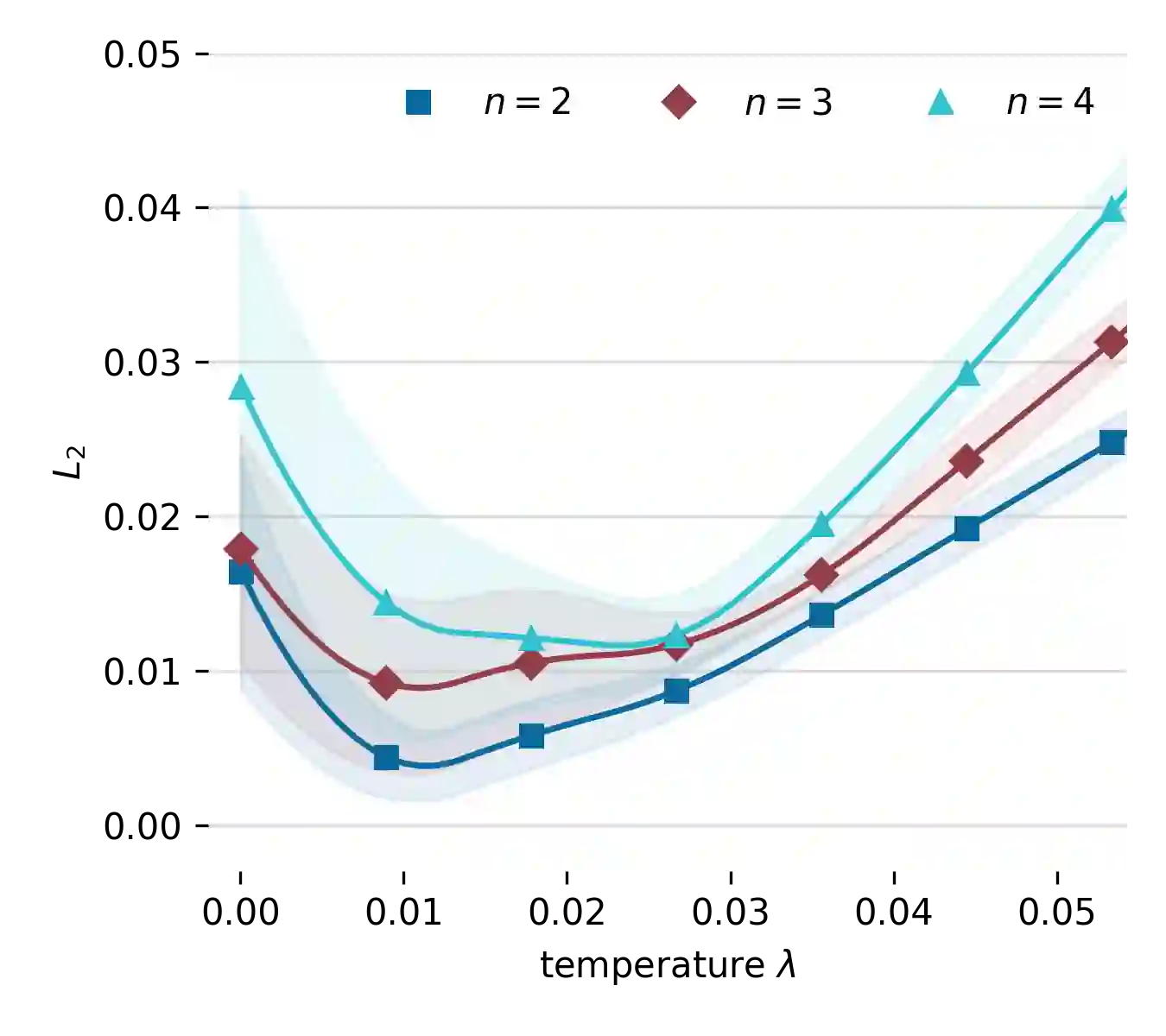
Understanding and analyzing markets is crucial, yet analytical equilibrium solutions remain largely infeasible. Recent breakthroughs in equilibrium computation rely on zeroth-order policy gradient estimation. These approaches commonly suffer from high variance and are computationally expensive. The use of fully differentiable simulators would enable more efficient gradient estimation. However, the discrete allocation of goods in economic simulations is a non-differentiable operation. This renders the first-order Monte Carlo gradient estimator inapplicable and the learning feedback systematically misleading. We propose a novel smoothing technique that creates a surrogate market game, in which first-order methods can be applied. We provide theoretical bounds on the resulting bias which justifies solving the smoothed game instead. These bounds also allow choosing the smoothing strength a priori such that the resulting estimate has low variance. Furthermore, we validate our approach via numerous empirical experiments. Our method theoretically and empirically outperforms zeroth-order methods in approximation quality and computational efficiency.
翻译:理解与分析市场至关重要,但解析均衡解在大多情况下仍不可行。近期均衡计算的突破主要依赖零阶策略梯度估计,这些方法通常存在高方差且计算成本高昂。全可微模拟器的应用本可实现更高效的梯度估计,然而经济模拟中商品的离散分配属于不可微操作,这导致一阶蒙特卡洛梯度估计器失效,且学习反馈会产生系统性偏差。我们提出一种新的平滑技术,通过构建代理市场博弈使得一阶方法得以应用。我们给出了由此产生偏差的理论边界,证明求解平滑博弈的合理性。这些边界还允许先验选择平滑强度,使得最终估计具有低方差。此外,我们通过大量实验验证了该方法。理论分析与实证结果表明,我们的方法在逼近质量和计算效率上均优于零阶方法。