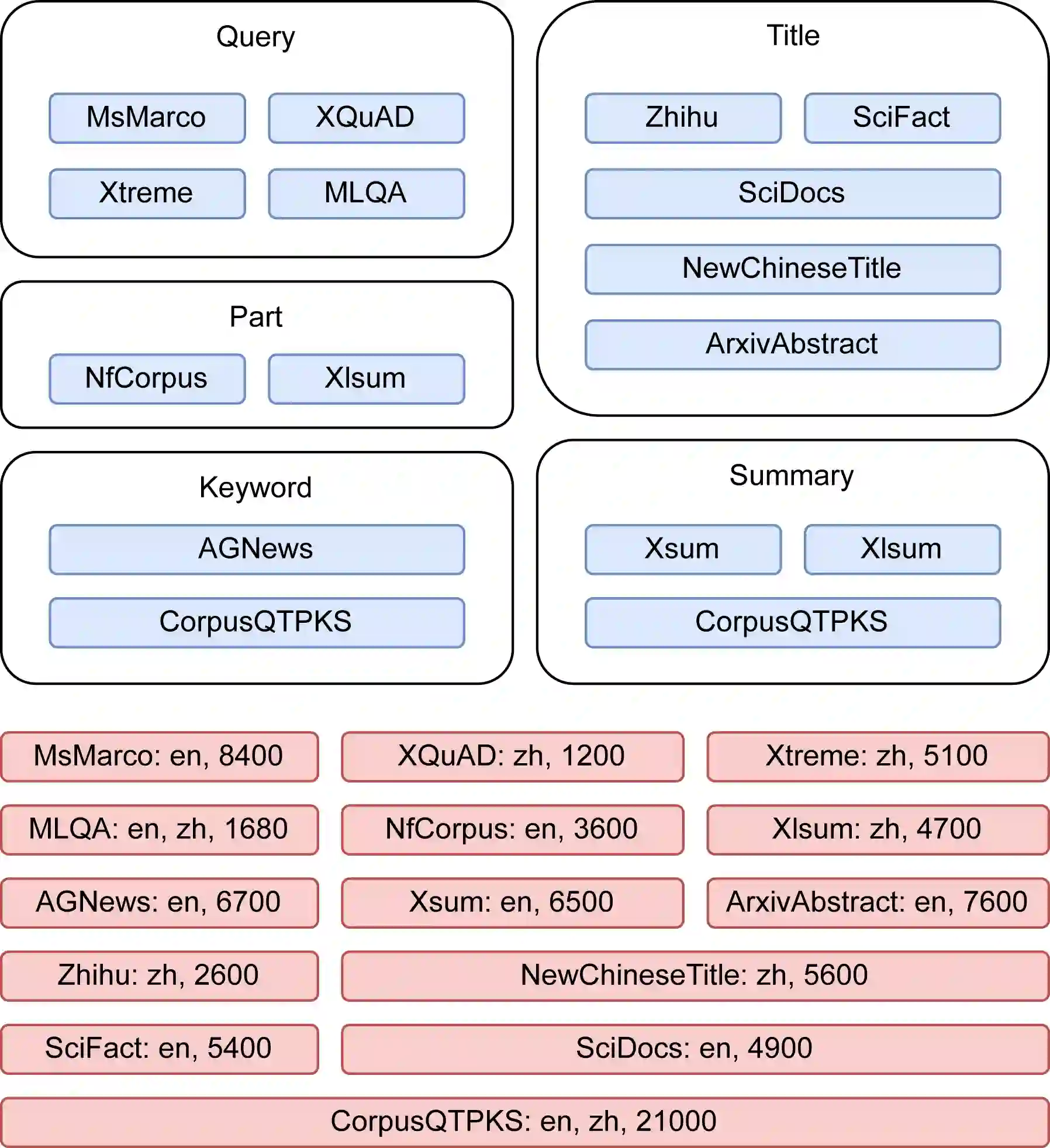
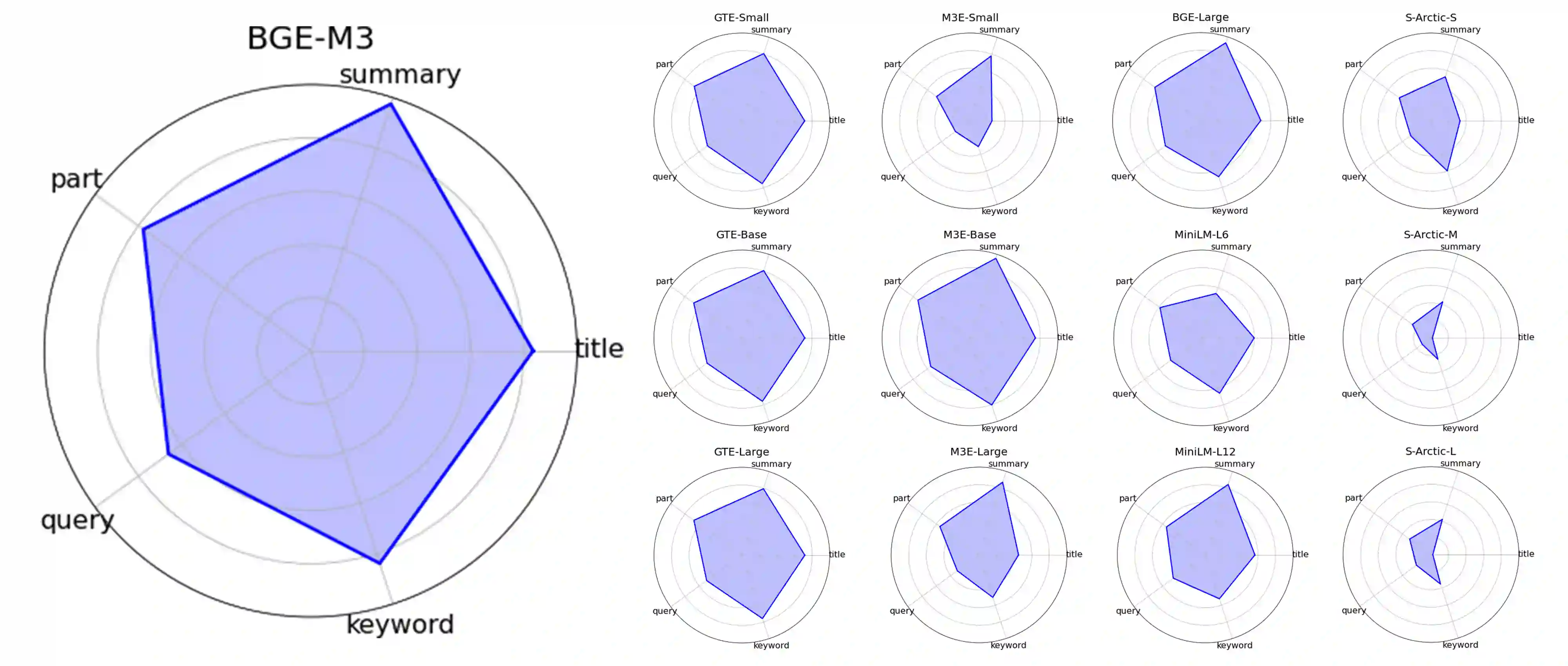
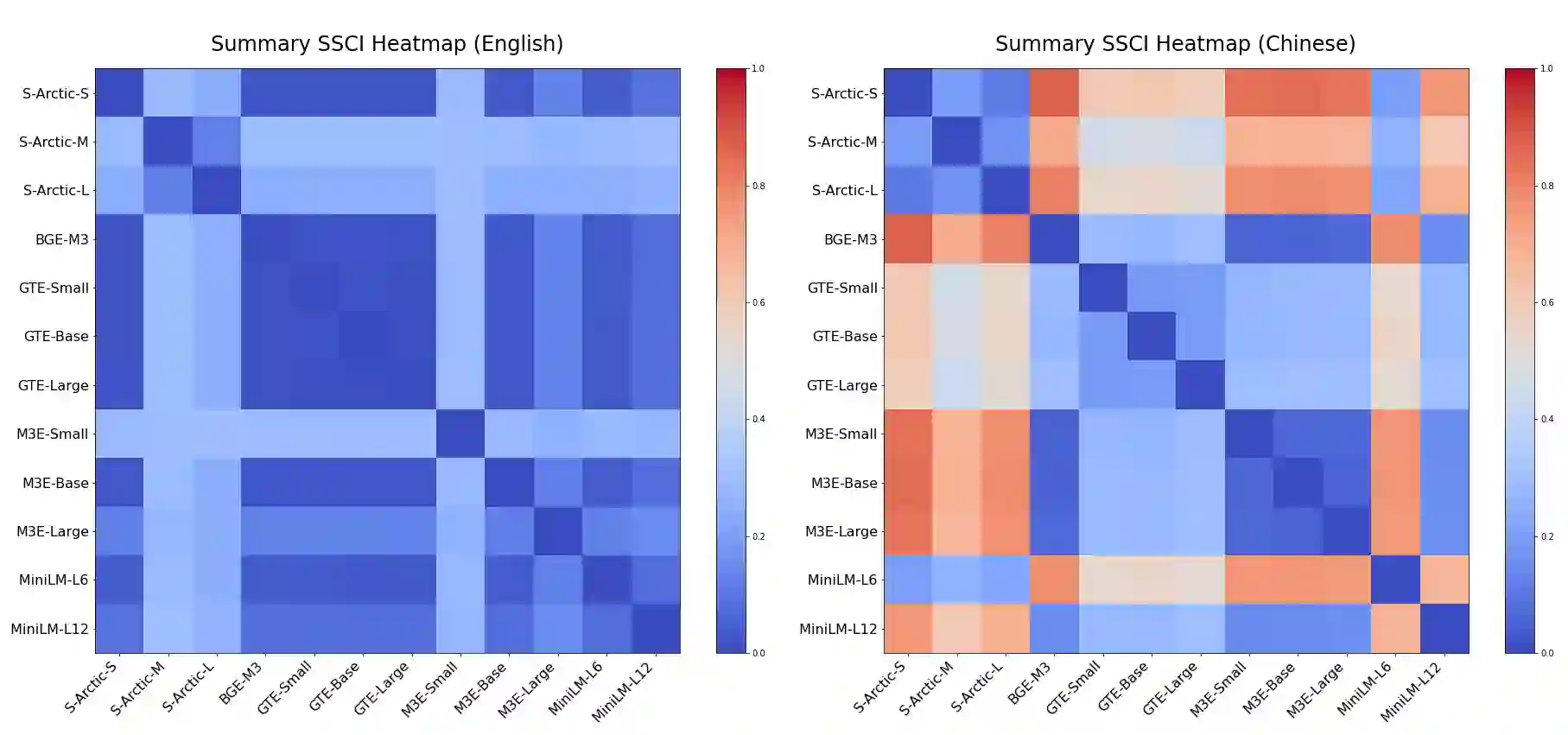
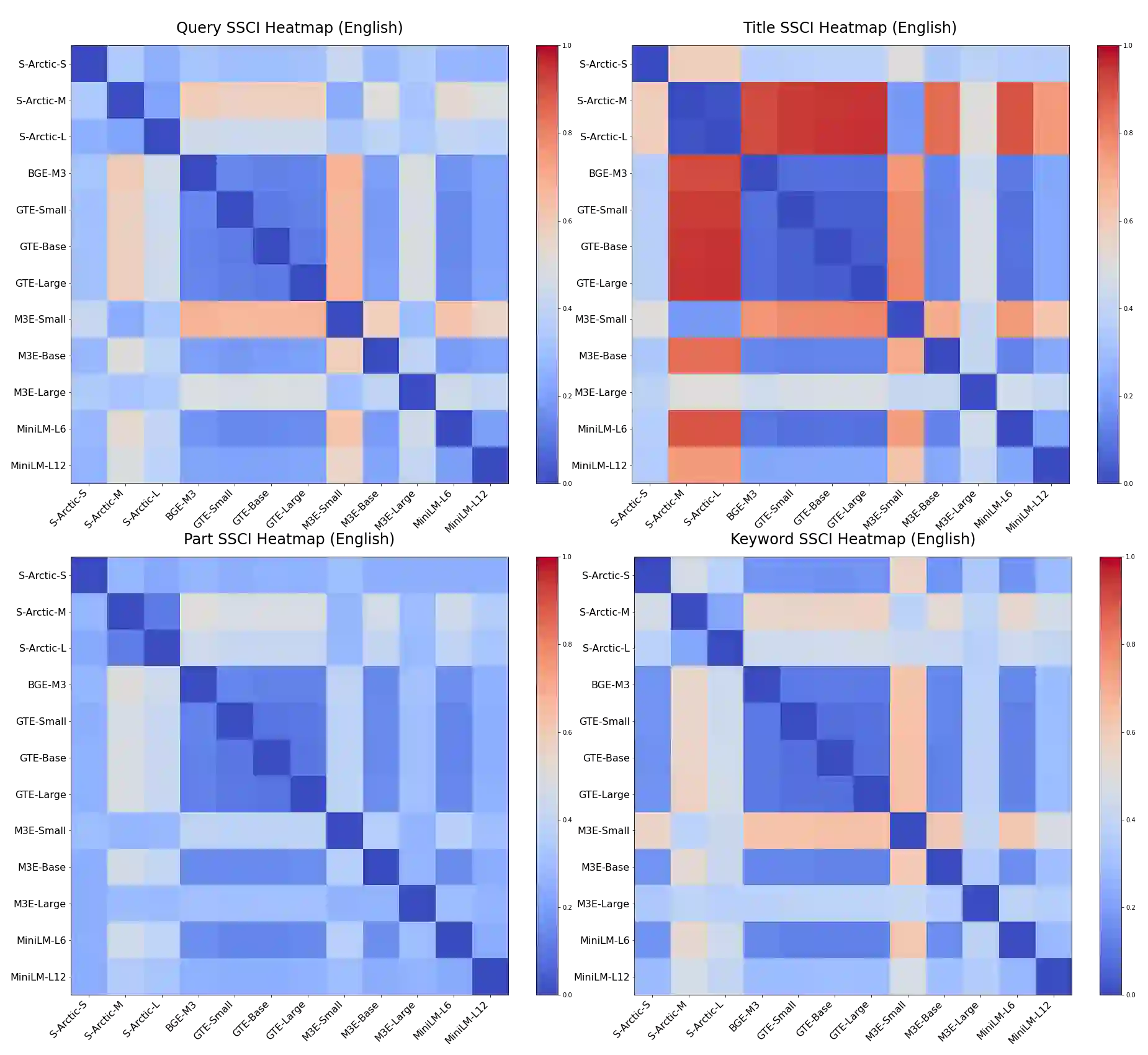
In Retrieval-Augmented Generation (RAG) tasks using Large Language Models (LLMs), the quality of retrieved information is critical to the final output. This paper introduces the IRSC benchmark for evaluating the performance of embedding models in multilingual RAG tasks. The benchmark encompasses five retrieval tasks: query retrieval, title retrieval, part-of-paragraph retrieval, keyword retrieval, and summary retrieval. Our research addresses the current lack of comprehensive testing and effective comparison methods for embedding models in RAG scenarios. We introduced new metrics: the Similarity of Semantic Comprehension Index (SSCI) and the Retrieval Capability Contest Index (RCCI), and evaluated models such as Snowflake-Arctic, BGE, GTE, and M3E. Our contributions include: 1) the IRSC benchmark, 2) the SSCI and RCCI metrics, and 3) insights into the cross-lingual limitations of embedding models. The IRSC benchmark aims to enhance the understanding and development of accurate retrieval systems in RAG tasks. All code and datasets are available at: https://github.com/Jasaxion/IRSC_Benchmark
翻译:在使用大型语言模型(LLM)的检索增强生成(RAG)任务中,检索信息的质量对最终输出至关重要。本文提出IRSC基准,用于评估嵌入模型在多语言RAG任务中的性能。该基准涵盖五种检索任务:查询检索、标题检索、段落局部检索、关键词检索和摘要检索。我们的研究针对当前RAG场景中嵌入模型缺乏全面测试与有效比较方法的问题,提出了新的评估指标:语义理解相似度指数(SSCI)与检索能力竞赛指数(RCCI),并对Snowflake-Arctic、BGE、GTE、M3E等模型进行了评估。本研究的贡献包括:1)IRSC基准;2)SSCI与RCCI指标;3)对嵌入模型跨语言局限性的深入分析。IRSC基准旨在促进对RAG任务中精准检索系统的理解与发展。所有代码与数据集已开源:https://github.com/Jasaxion/IRSC_Benchmark