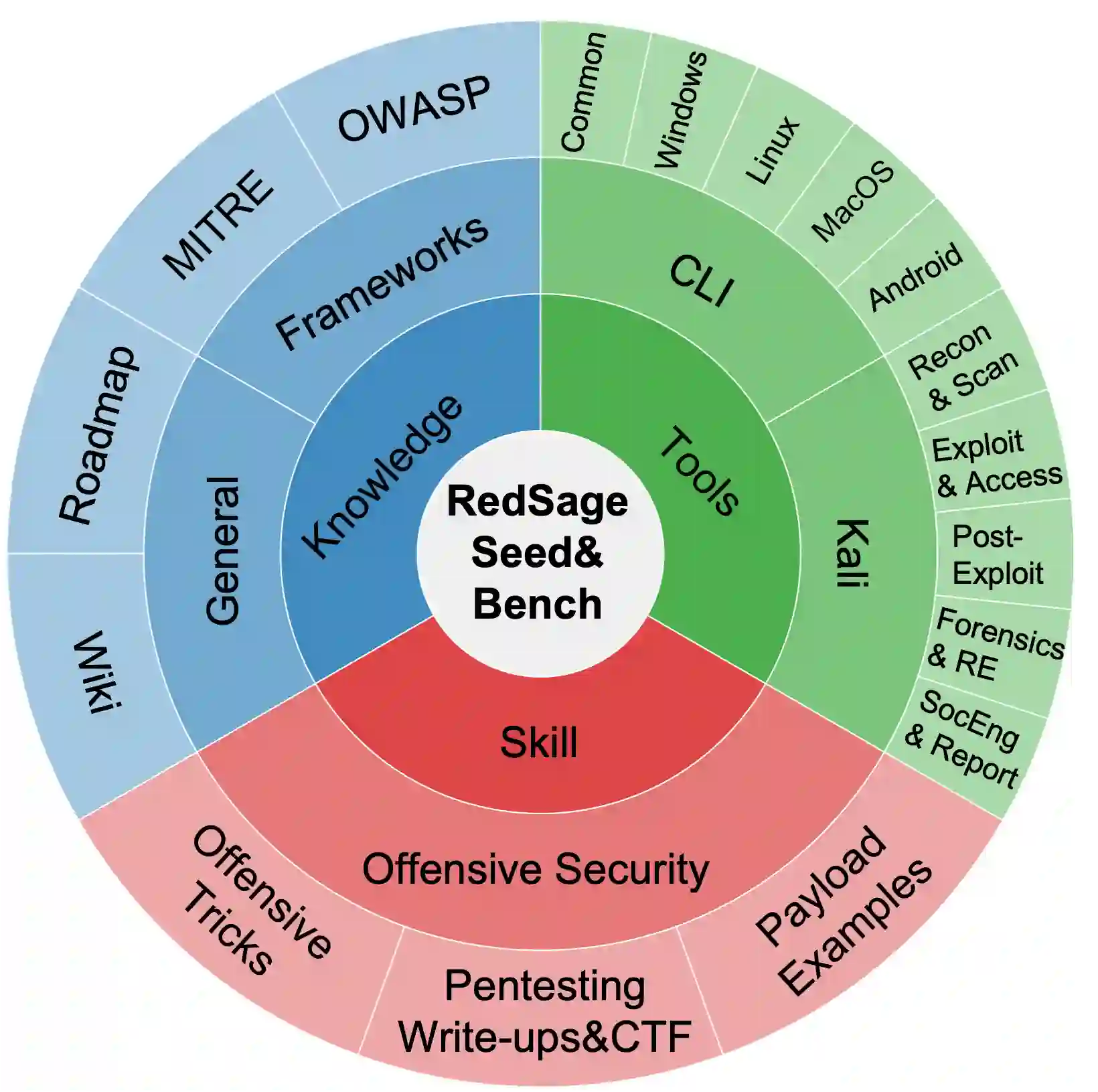
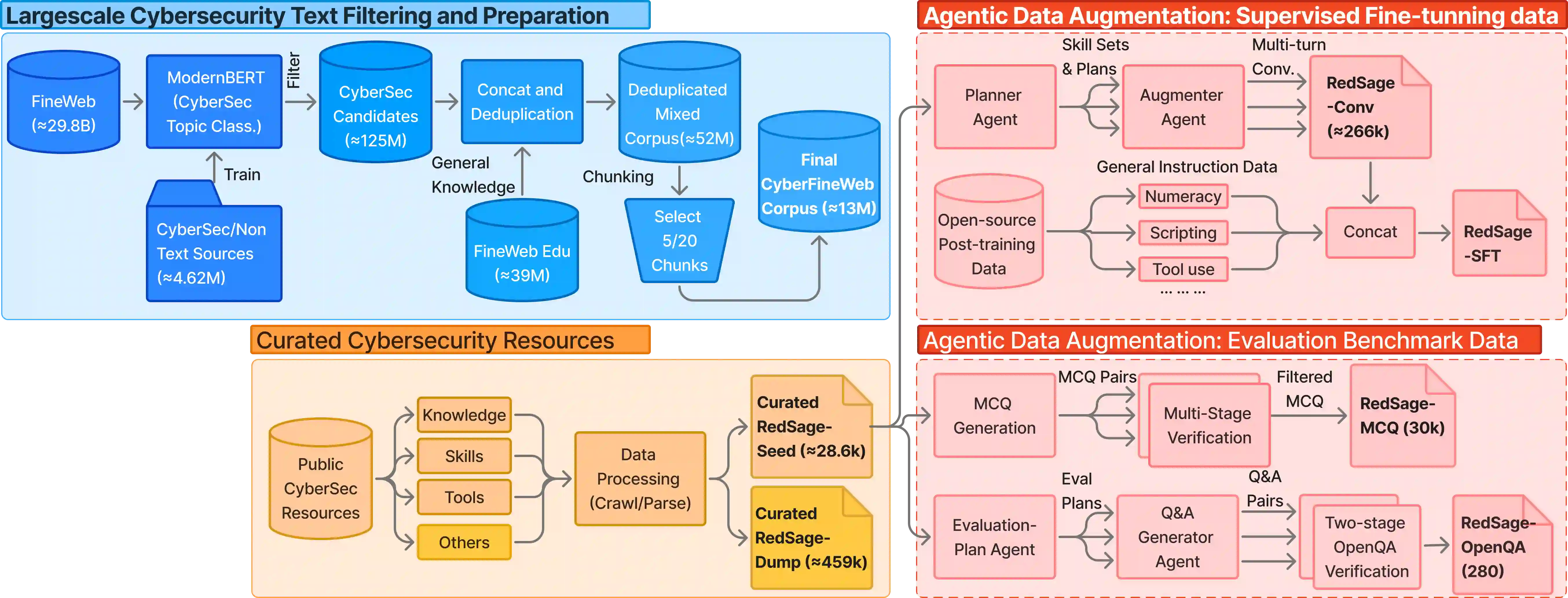
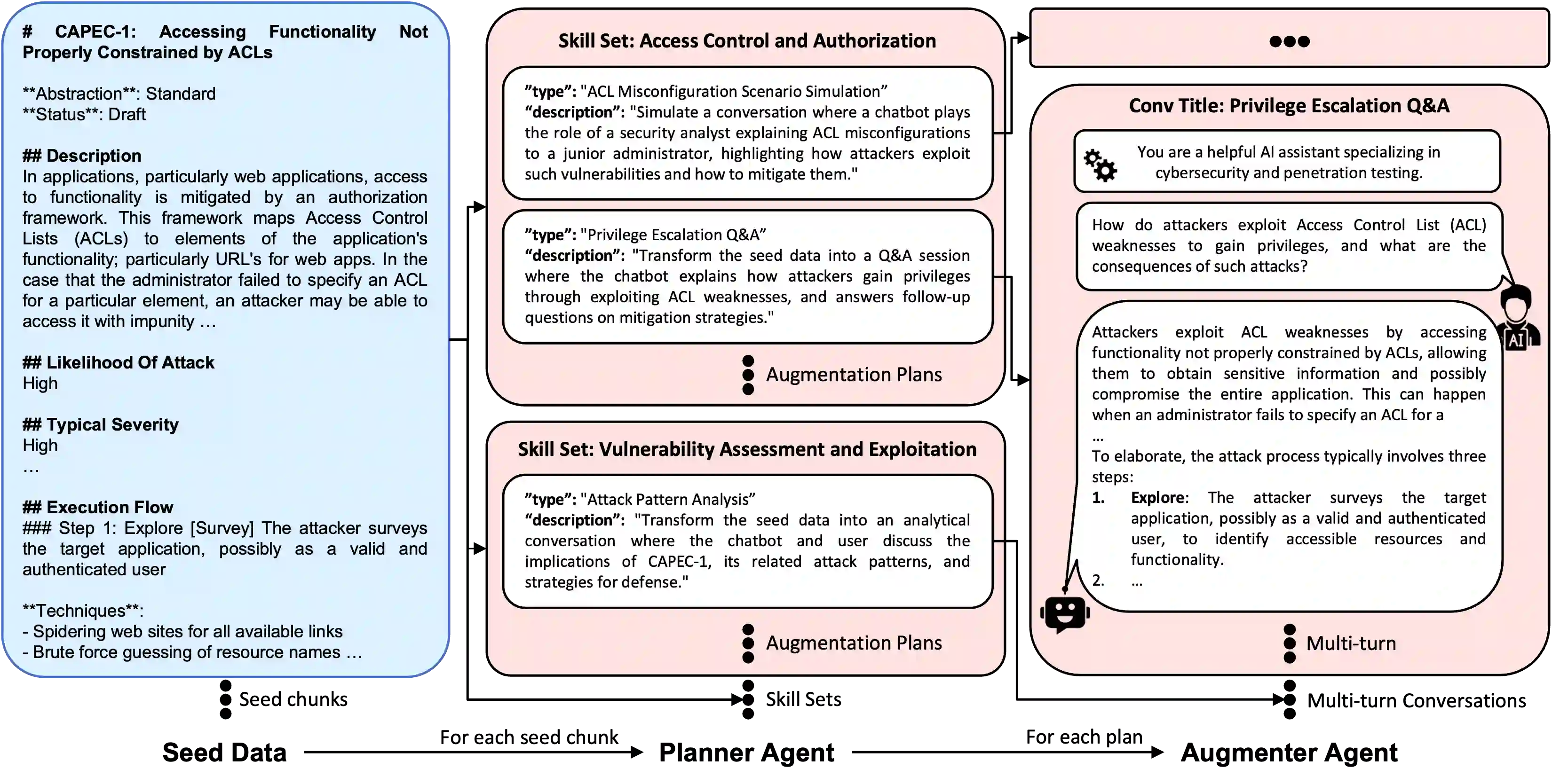
Cybersecurity operations demand assistant LLMs that support diverse workflows without exposing sensitive data. Existing solutions either rely on proprietary APIs with privacy risks or on open models lacking domain adaptation. To bridge this gap, we curate 11.8B tokens of cybersecurity-focused continual pretraining data via large-scale web filtering and manual collection of high-quality resources, spanning 28.6K documents across frameworks, offensive techniques, and security tools. Building on this, we design an agentic augmentation pipeline that simulates expert workflows to generate 266K multi-turn cybersecurity samples for supervised fine-tuning. Combined with general open-source LLM data, these resources enable the training of RedSage, an open-source, locally deployable cybersecurity assistant with domain-aware pretraining and post-training. To rigorously evaluate the models, we introduce RedSage-Bench, a benchmark with 30K multiple-choice and 240 open-ended Q&A items covering cybersecurity knowledge, skills, and tool expertise. RedSage is further evaluated on established cybersecurity benchmarks (e.g., CTI-Bench, CyberMetric, SECURE) and general LLM benchmarks to assess broader generalization. At the 8B scale, RedSage achieves consistently better results, surpassing the baseline models by up to +5.59 points on cybersecurity benchmarks and +5.05 points on Open LLM Leaderboard tasks. These findings demonstrate that domain-aware agentic augmentation and pre/post-training can not only enhance cybersecurity-specific expertise but also help to improve general reasoning and instruction-following. All models, datasets, and code are publicly available.
翻译:网络安全运营需要能够支持多样化工作流程且不暴露敏感数据的辅助性大语言模型。现有解决方案要么依赖存在隐私风险的专有API,要么采用缺乏领域适应的开源模型。为弥补这一差距,我们通过大规模网络过滤和高质量资源的人工收集,策划了118亿词元的网络安全持续预训练数据,涵盖框架、攻击技术和安全工具等领域的2.86万份文档。在此基础上,我们设计了智能增强流程来模拟专家工作流,生成26.6万个用于监督微调的多轮网络安全样本。结合通用开源大语言模型数据,这些资源使得训练RedSage成为可能——这是一个具有领域感知预训练与后训练能力的开源、可本地化部署的网络安全助手。为严格评估模型性能,我们推出了RedSage-Bench基准测试,包含3万个选择题和240个开放式问答项目,涵盖网络安全知识、技能和工具专长。RedSage还在现有网络安全基准(如CTI-Bench、CyberMetric、SECURE)和通用大语言模型基准上接受进一步评估,以衡量其泛化能力。在80亿参数规模下,RedSage持续取得更优结果,在网络安全基准上超越基线模型最高达+5.59分,在Open LLM Leaderboard任务上提升+5.05分。这些发现表明,领域感知的智能增强与预训练/后训练不仅能提升网络安全专项能力,还有助于改善通用推理和指令遵循性能。所有模型、数据集和代码均已开源发布。