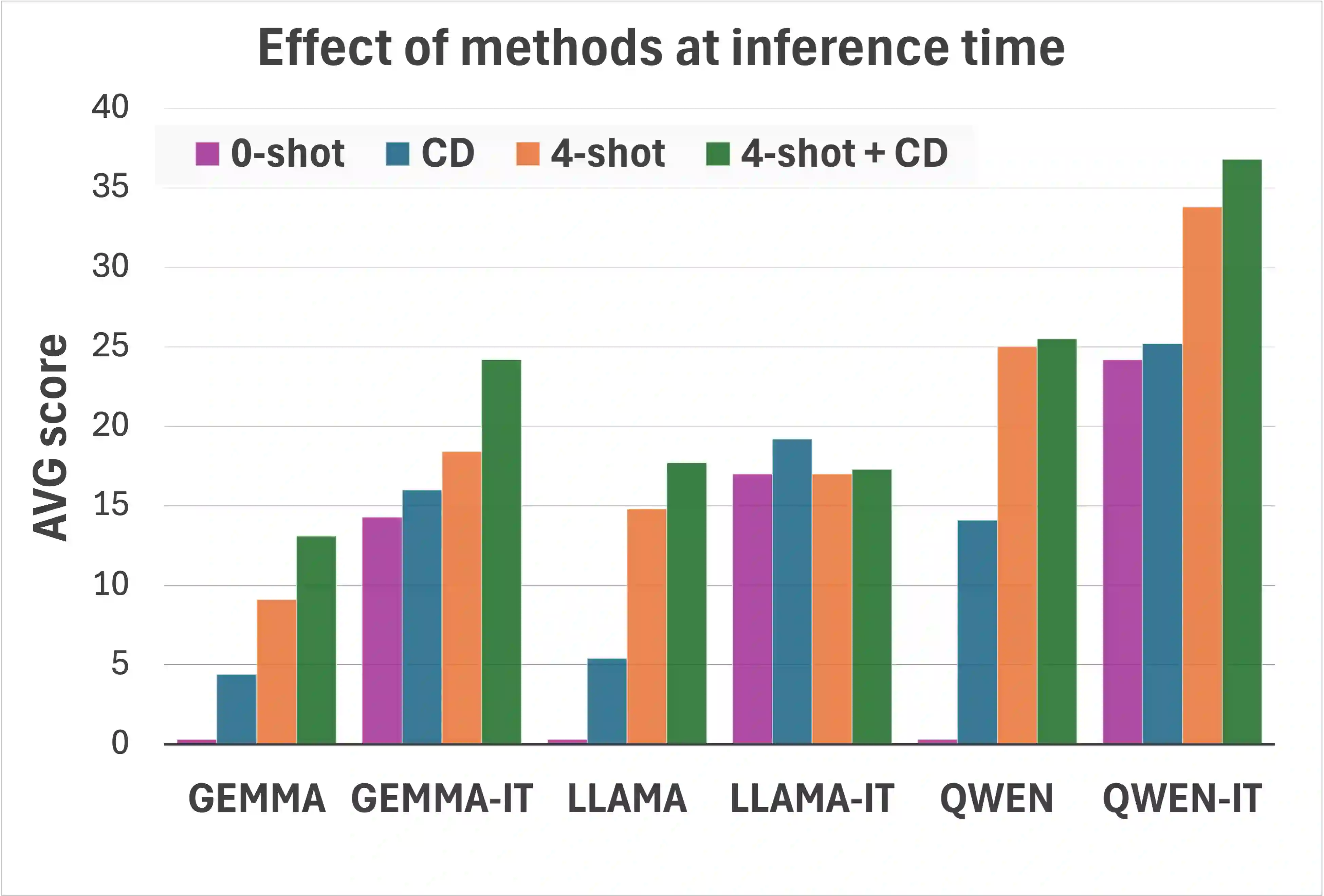
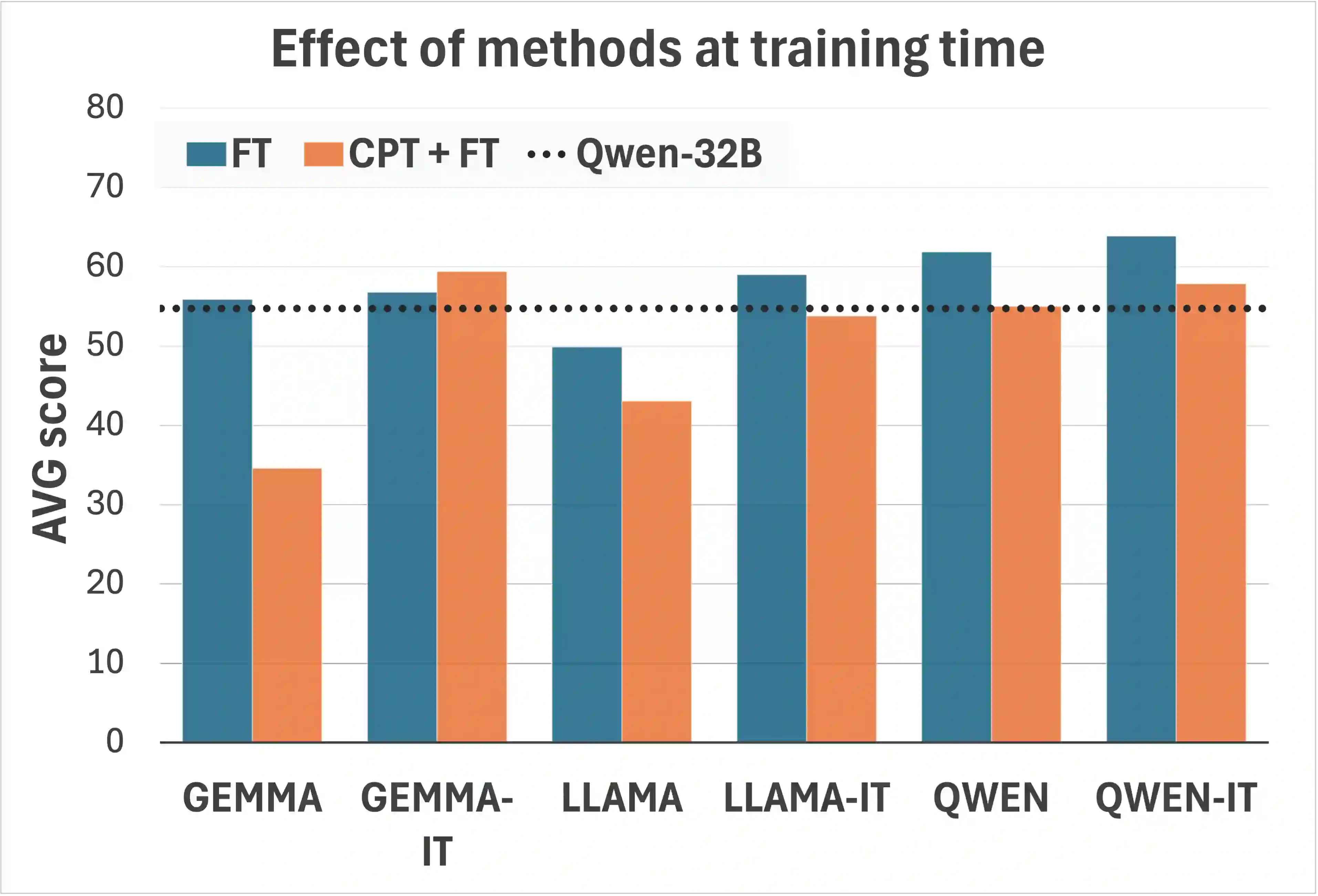
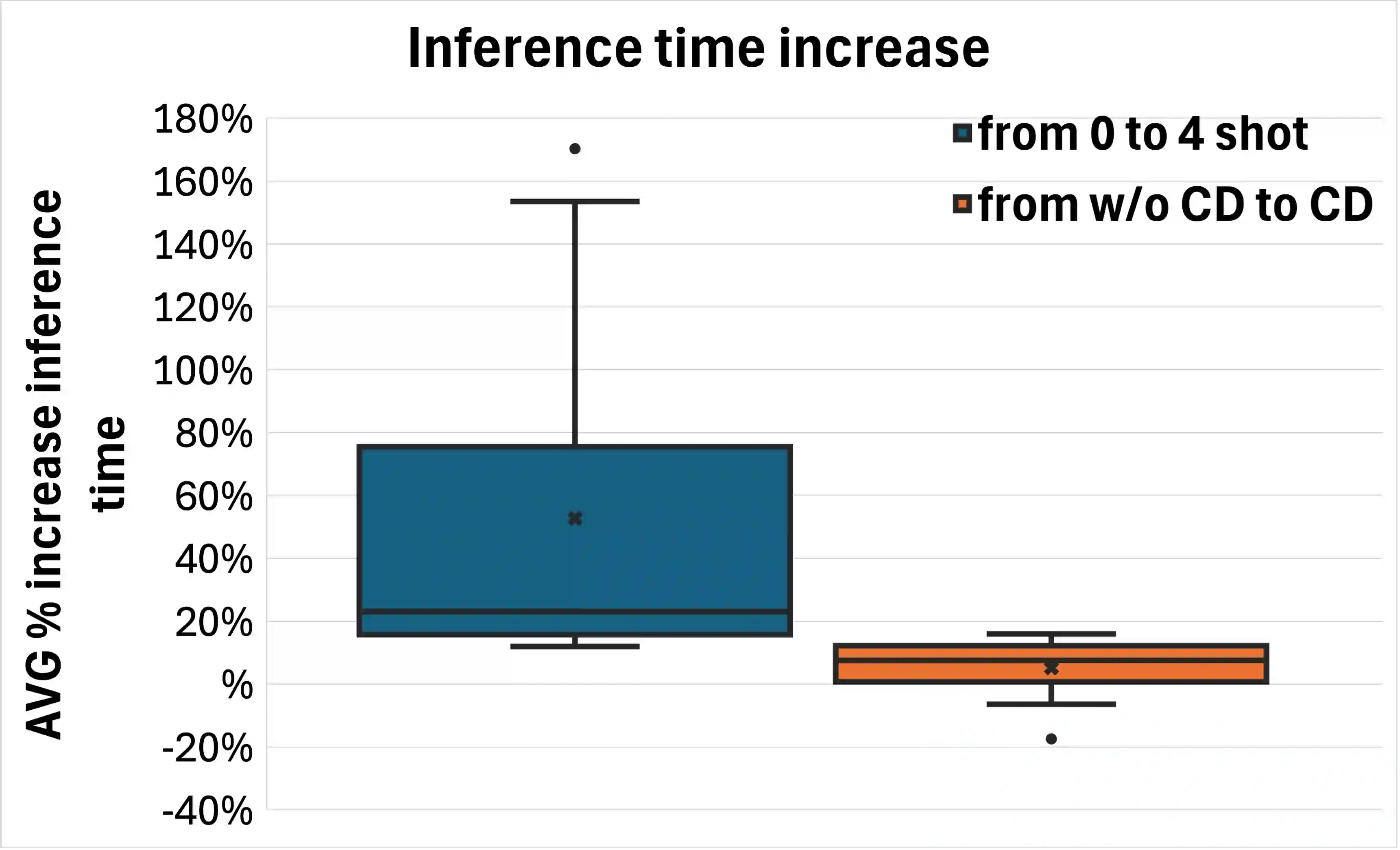
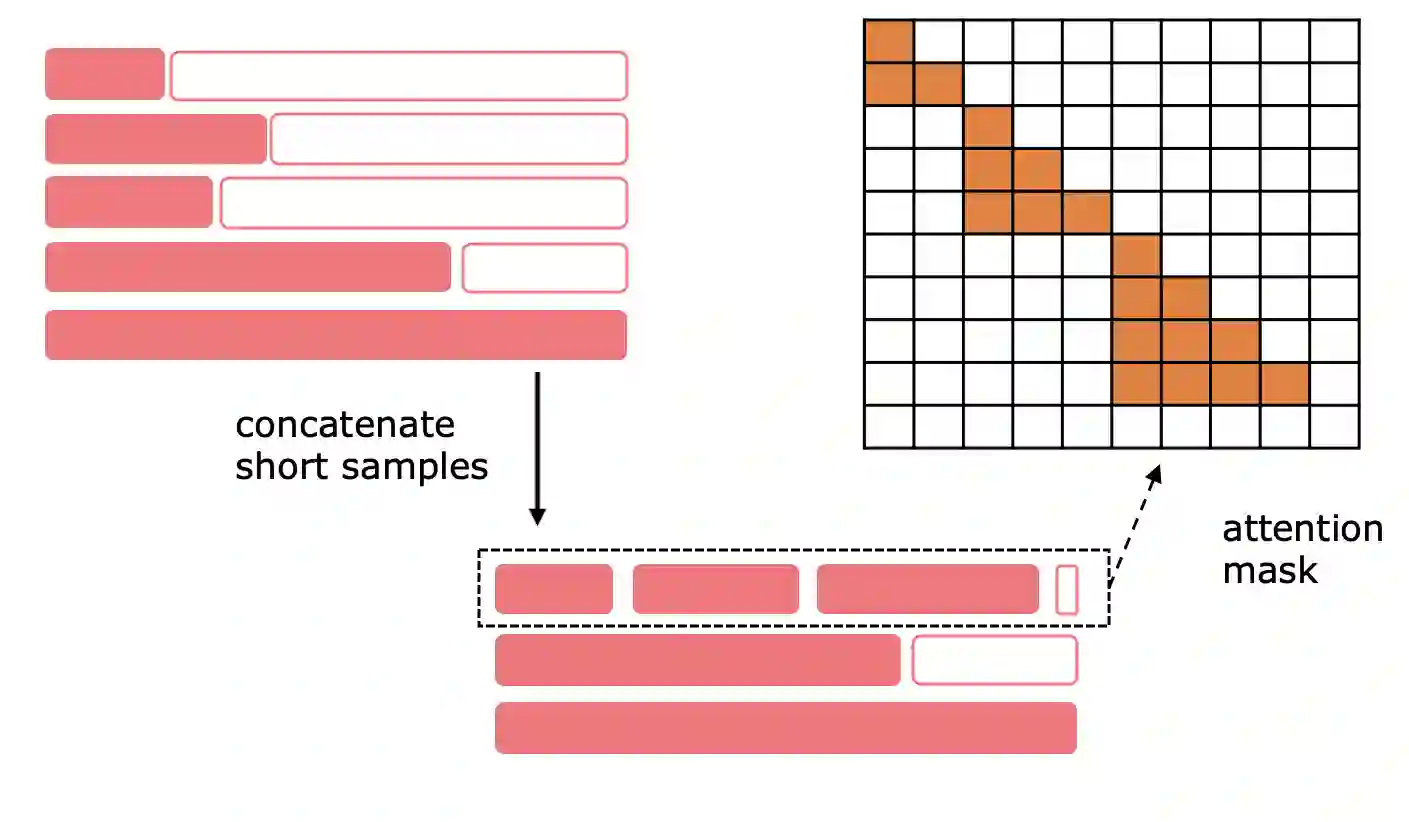
Large Language Models (LLMs) consistently excel in diverse medical Natural Language Processing (NLP) tasks, yet their substantial computational requirements often limit deployment in real-world healthcare settings. In this work, we investigate whether "small" LLMs (around one billion parameters) can effectively perform medical tasks while maintaining competitive accuracy. We evaluate models from three major families-Llama-3, Gemma-3, and Qwen3-across 20 clinical NLP tasks among Named Entity Recognition, Relation Extraction, Case Report Form Filling, Question Answering, and Argument Mining. We systematically compare a range of adaptation strategies, both at inference time (few-shot prompting, constraint decoding) and at training time (supervised fine-tuning, continual pretraining). Fine-tuning emerges as the most effective approach, while the combination of few-shot prompting and constraint decoding offers strong lower-resource alternatives. Our results show that small LLMs can match or even surpass larger baselines, with our best configuration based on Qwen3-1.7B achieving an average score +9.2 points higher than Qwen3-32B. We release a comprehensive collection of all the publicly available Italian medical datasets for NLP tasks, together with our top-performing models. Furthermore, we release an Italian dataset of 126M words from the Emergency Department of an Italian Hospital, and 175M words from various sources that we used for continual pre-training.
翻译:大型语言模型(LLM)在各类医学自然语言处理(NLP)任务中持续表现出色,但其庞大的计算需求往往限制了在实际医疗场景中的部署。本研究旨在探究"小型"LLM(约十亿参数规模)是否能在保持竞争力的准确率前提下有效执行医学任务。我们选取了Llama-3、Gemma-3和Qwen3三大模型家族的模型,在命名实体识别、关系抽取、病例报告表填充、问答系统及论证挖掘等20项临床NLP任务上进行了系统性评估。我们全面比较了推理阶段(少样本提示、约束解码)与训练阶段(监督微调、持续预训练)的多种适应策略。结果表明,微调是最有效的适应方法,而少样本提示与约束解码的结合则为资源受限场景提供了优质的替代方案。实验数据显示,小型LLM能够达到甚至超越更大规模基线模型的性能,其中基于Qwen3-1.7B的最佳配置平均得分比Qwen3-32B高出9.2个百分点。我们公开了所有可获取的意大利医学NLP任务数据集及我们的最优性能模型。此外,我们还发布了包含来自意大利医院急诊科的1.26亿词次数据集,以及用于持续预训练的1.75亿词次多源数据集。