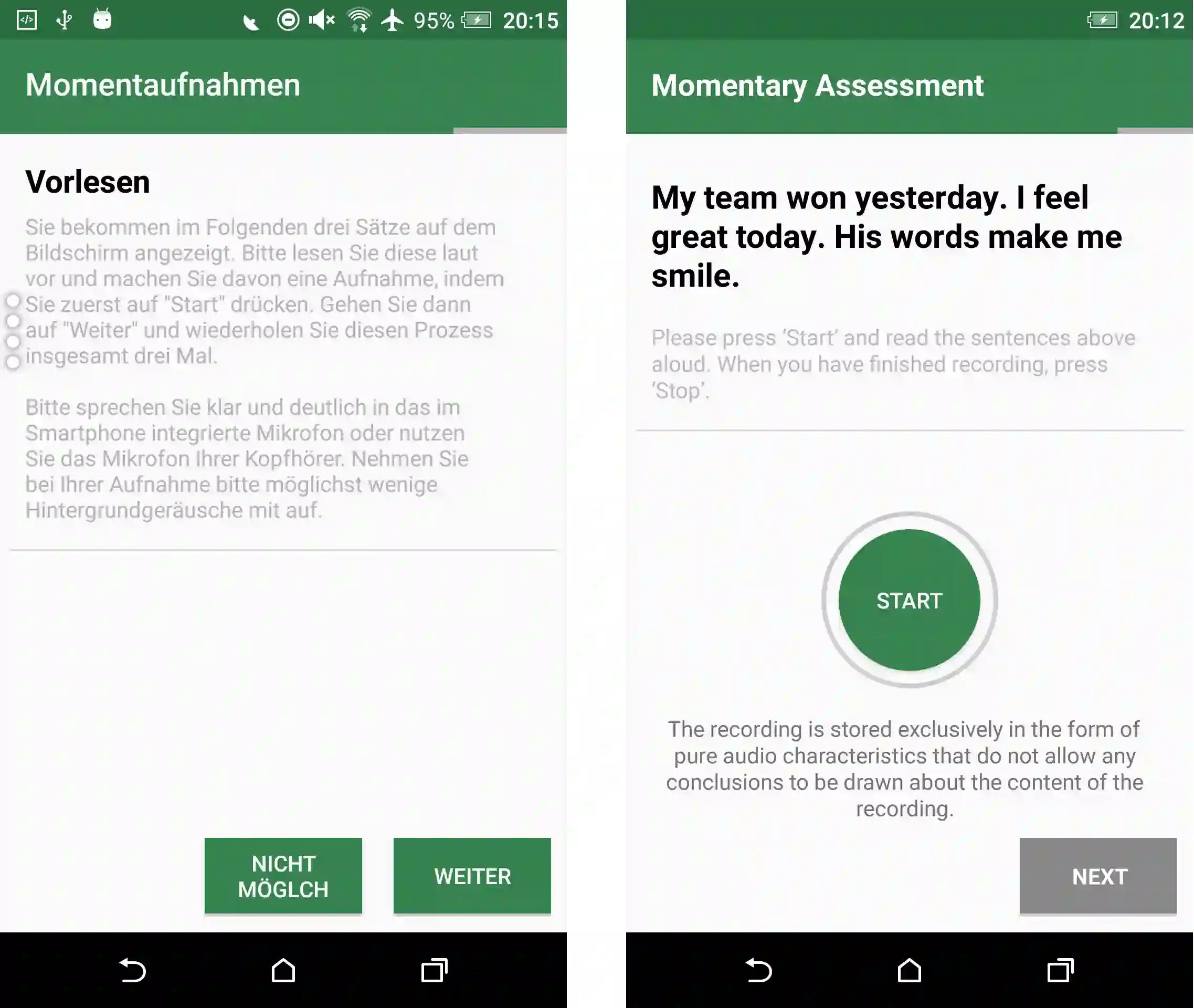
Collecting everyday speech data for prosodic analysis is challenging due to the confounding of prosody and semantics, privacy constraints, and participant compliance. We introduce and empirically evaluate a content-controlled, privacy-first smartphone protocol that uses scripted read-aloud sentences to standardize lexical content (including prompt valence) while capturing natural variation in prosodic delivery. The protocol performs on-device prosodic feature extraction, deletes raw audio immediately, and transmits only derived features for analysis. We deployed the protocol in a large study (N = 560; 9,877 recordings), evaluated compliance and data quality, and conducted diagnostic prediction tasks on the extracted features, predicting speaker sex and concurrently reported momentary affective states (valence, arousal). We discuss implications and directions for advancing and deploying the protocol.
翻译:为韵律分析收集日常语音数据面临诸多挑战,包括韵律与语义的混淆、隐私限制以及参与者依从性问题。本文提出并实证评估了一种内容可控、隐私优先的智能手机协议。该协议使用脚本化的朗读句子来标准化词汇内容(包括提示效价),同时捕捉韵律表达的自然变化。协议在设备端执行韵律特征提取,立即删除原始音频,仅传输衍生特征用于分析。我们在一项大规模研究(N = 560;9,877条录音)中部署了该协议,评估了依从性和数据质量,并对提取的特征进行了诊断性预测任务,包括预测说话者性别以及同时报告的瞬时情感状态(效价、唤醒度)。最后,我们讨论了该协议的改进方向、部署意义及应用前景。