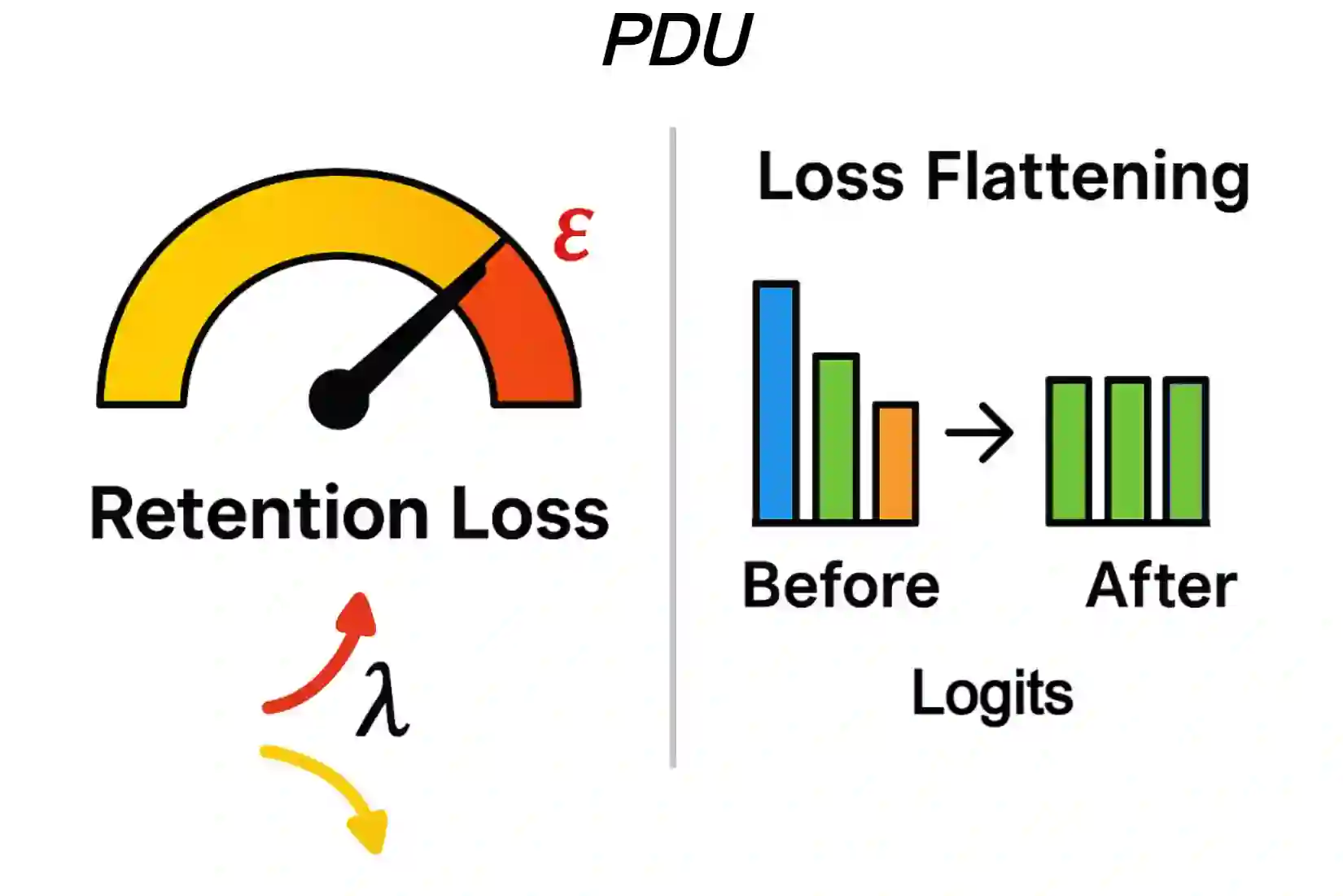
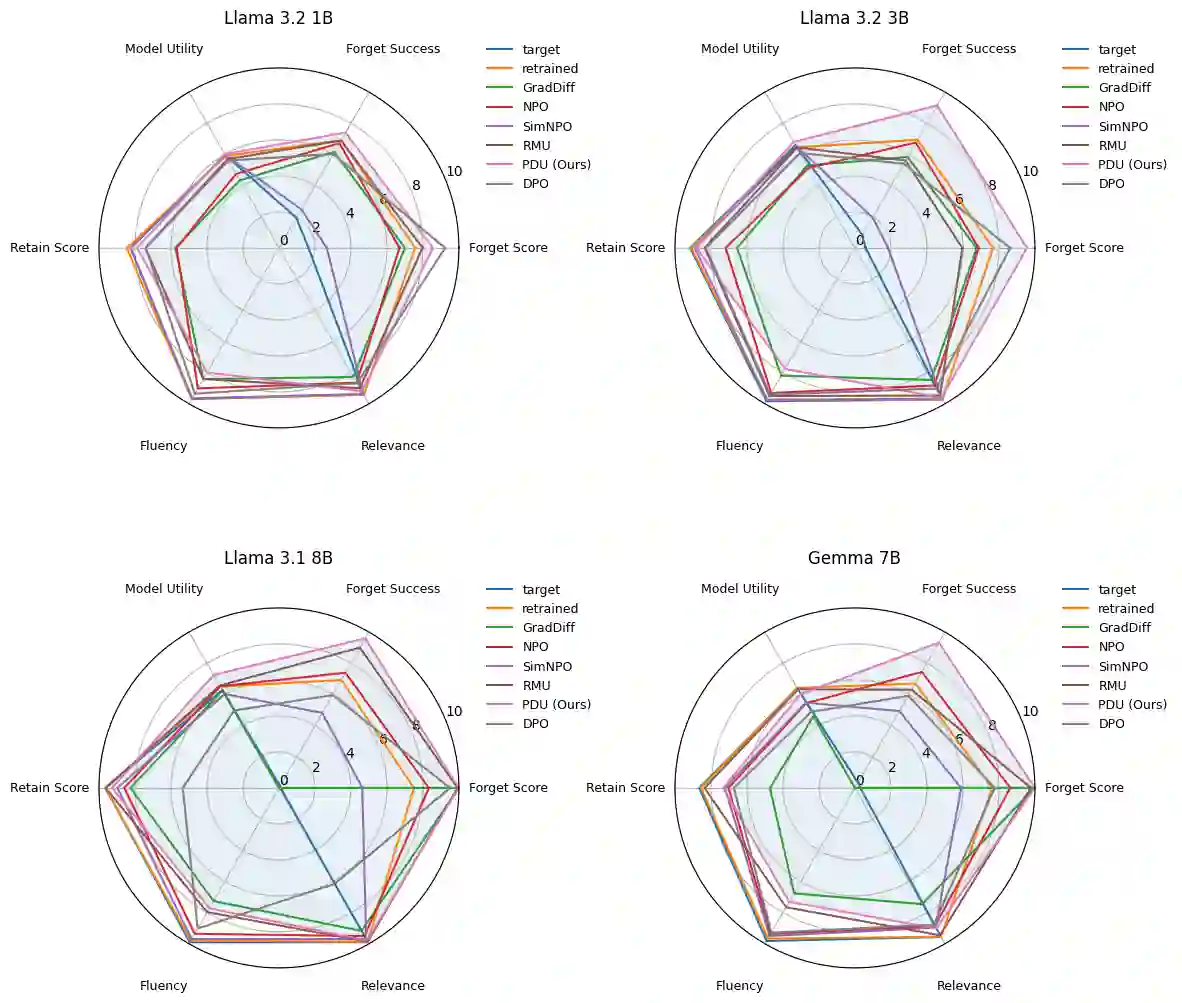
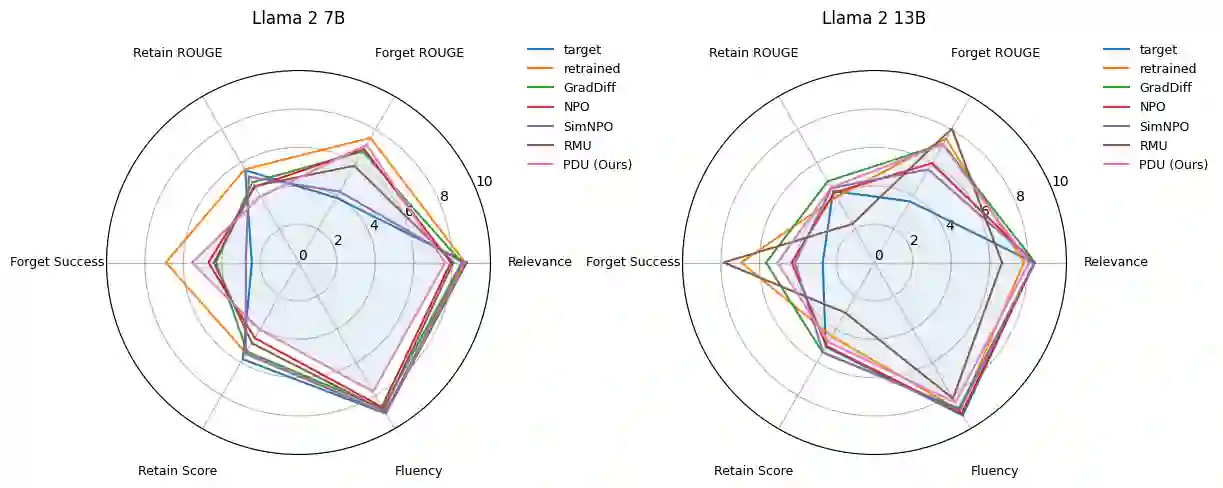
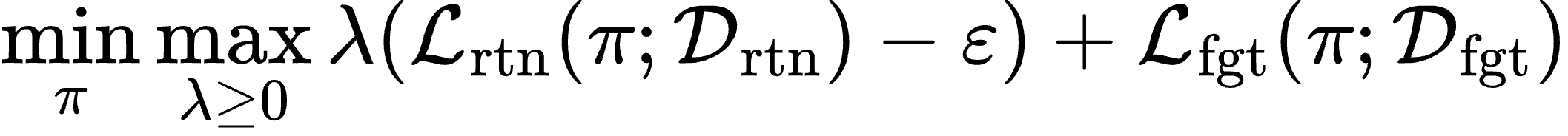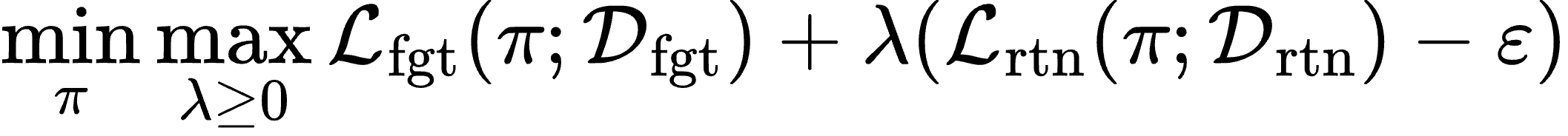Large Language Models (LLMs) deployed in real-world settings increasingly face the need to unlearn sensitive, outdated, or proprietary information. Existing unlearning methods typically formulate forgetting and retention as a regularized trade-off, combining both objectives into a single scalarized loss. This often leads to unstable optimization and degraded performance on retained data, especially under aggressive forgetting. We propose a new formulation of LLM unlearning as a constrained optimization problem: forgetting is enforced via a novel logit-margin flattening loss that explicitly drives the output distribution toward uniformity on a designated forget set, while retention is preserved through a hard constraint on a separate retain set. Compared to entropy-based objectives, our loss is softmax-free, numerically stable, and maintains non-vanishing gradients, enabling more efficient and robust optimization. We solve the constrained problem using a scalable primal-dual algorithm that exposes the trade-off between forgetting and retention through the dynamics of the dual variable, all without any extra computational overhead. Evaluations on the TOFU and MUSE benchmarks across diverse LLM architectures demonstrate that our approach consistently matches or exceeds state-of-the-art baselines, effectively removing targeted information while preserving downstream utility.
翻译:部署于实际场景中的大语言模型日益面临需要遗忘敏感、过时或专有信息的需求。现有遗忘方法通常将遗忘与保留表述为正则化权衡,将两个目标合并为单一标量化损失。这常导致优化不稳定及在保留数据上的性能下降,尤其在激进遗忘条件下更为明显。我们提出一种将大语言模型遗忘重构为约束优化问题的新范式:通过一种新颖的对数几率边际平坦化损失在指定遗忘集上显式驱动输出分布趋向均匀性以强制实现遗忘,同时通过独立保留集上的硬约束保持知识留存。相较于基于熵的目标函数,我们的损失函数无需softmax运算、数值稳定且保持非消失梯度,从而实现更高效稳健的优化。我们采用可扩展的原对偶算法求解该约束问题,该算法通过对偶变量的动态变化揭示遗忘与保留间的权衡关系,且无需额外计算开销。在TOFU和MUSE基准测试中对多种大语言模型架构的评估表明,本方法始终匹配或超越现有最优基线,在有效移除目标信息的同时保持下游任务效用。