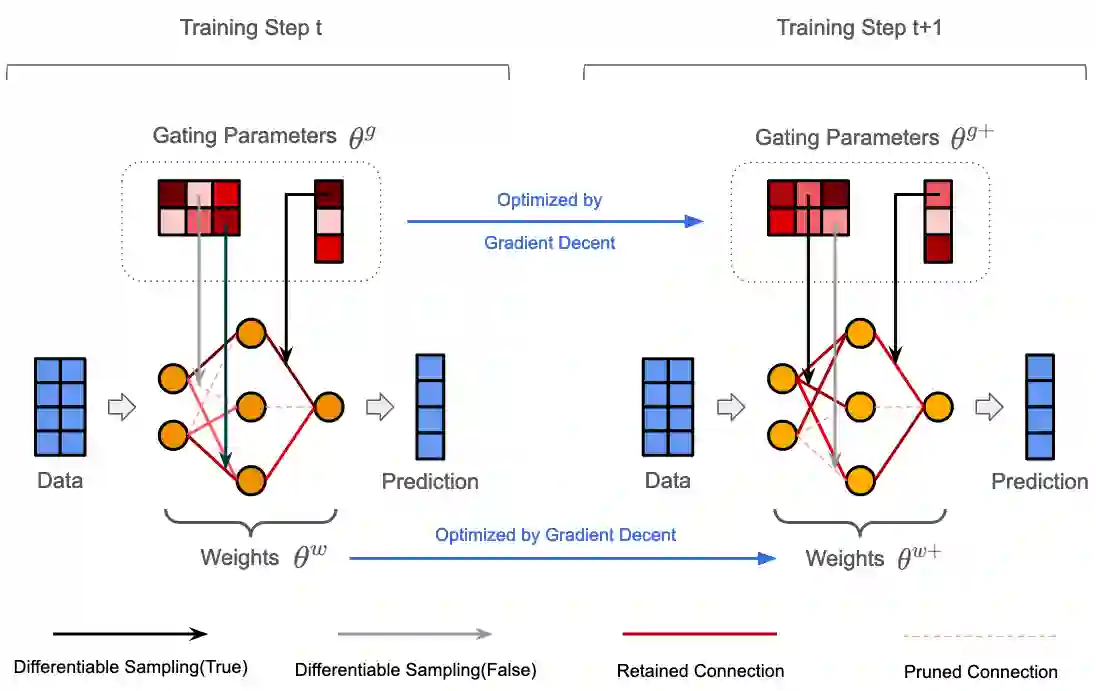
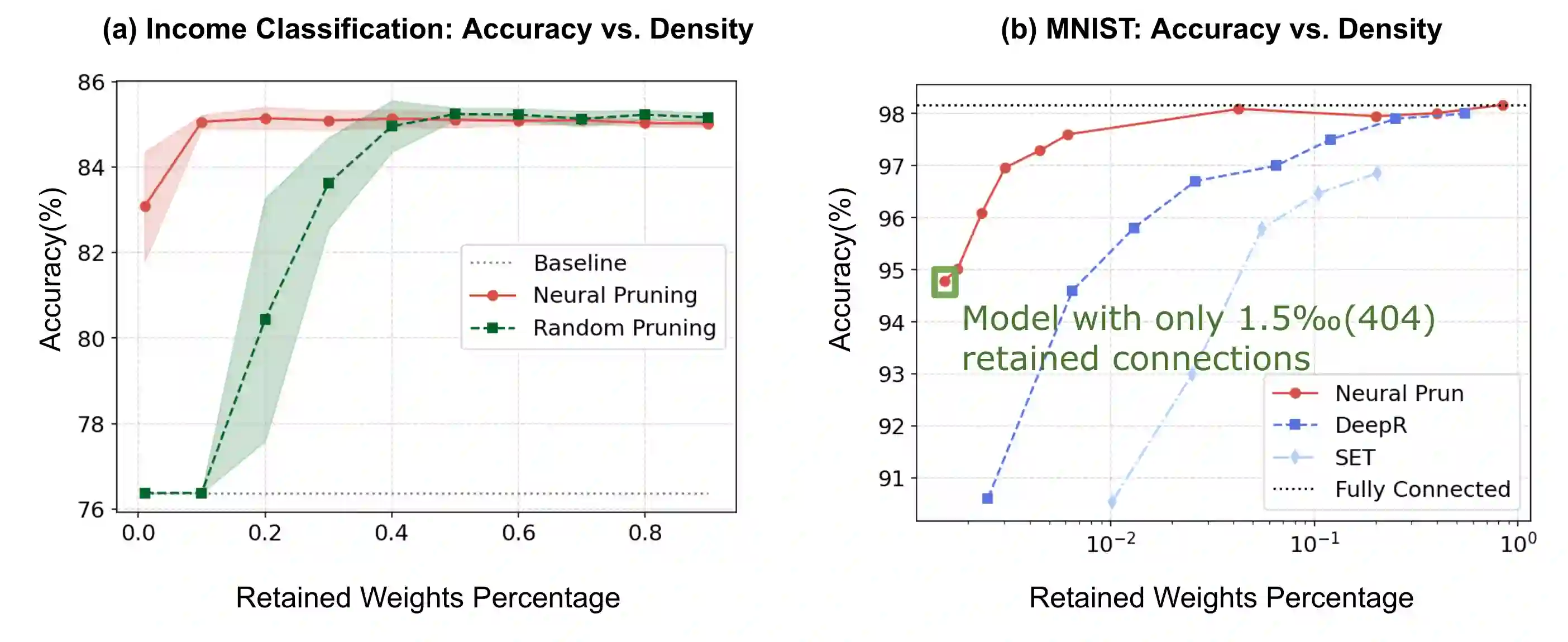
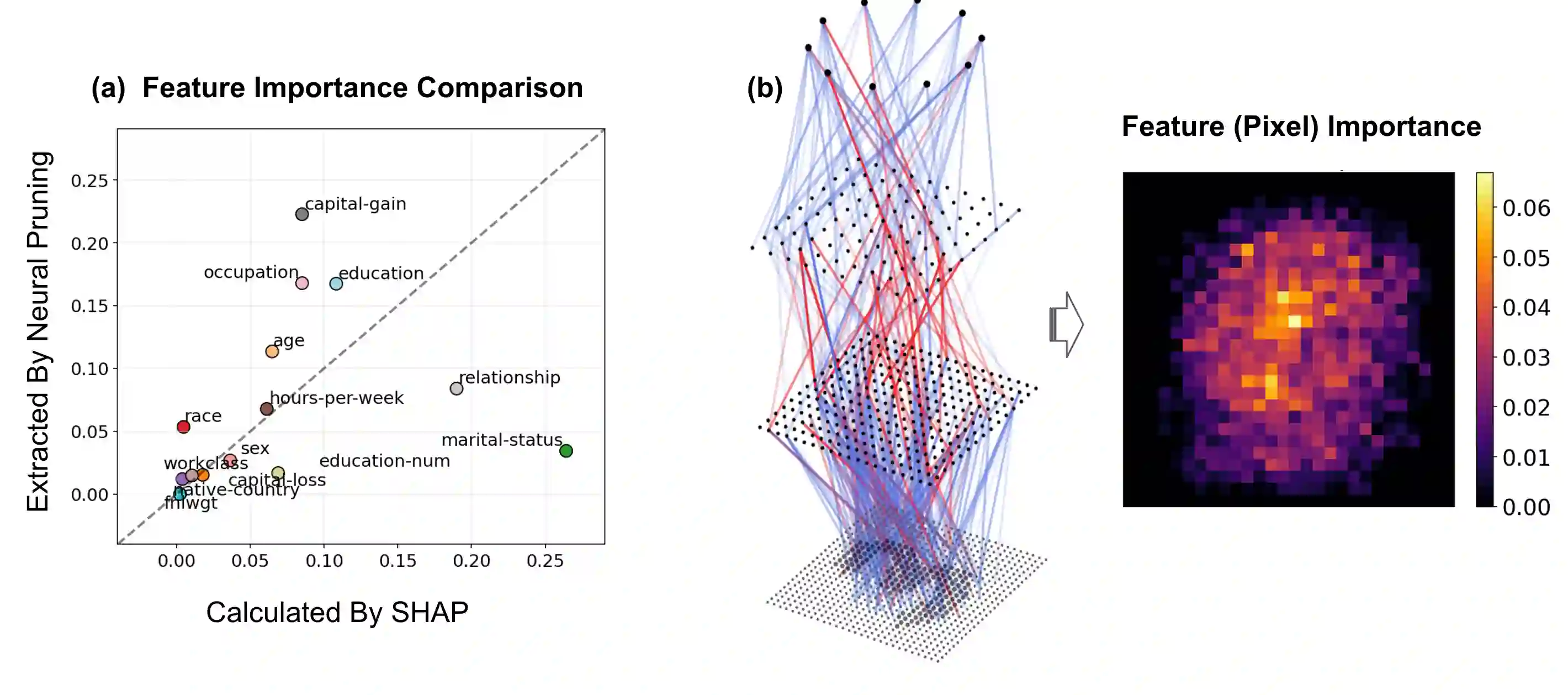
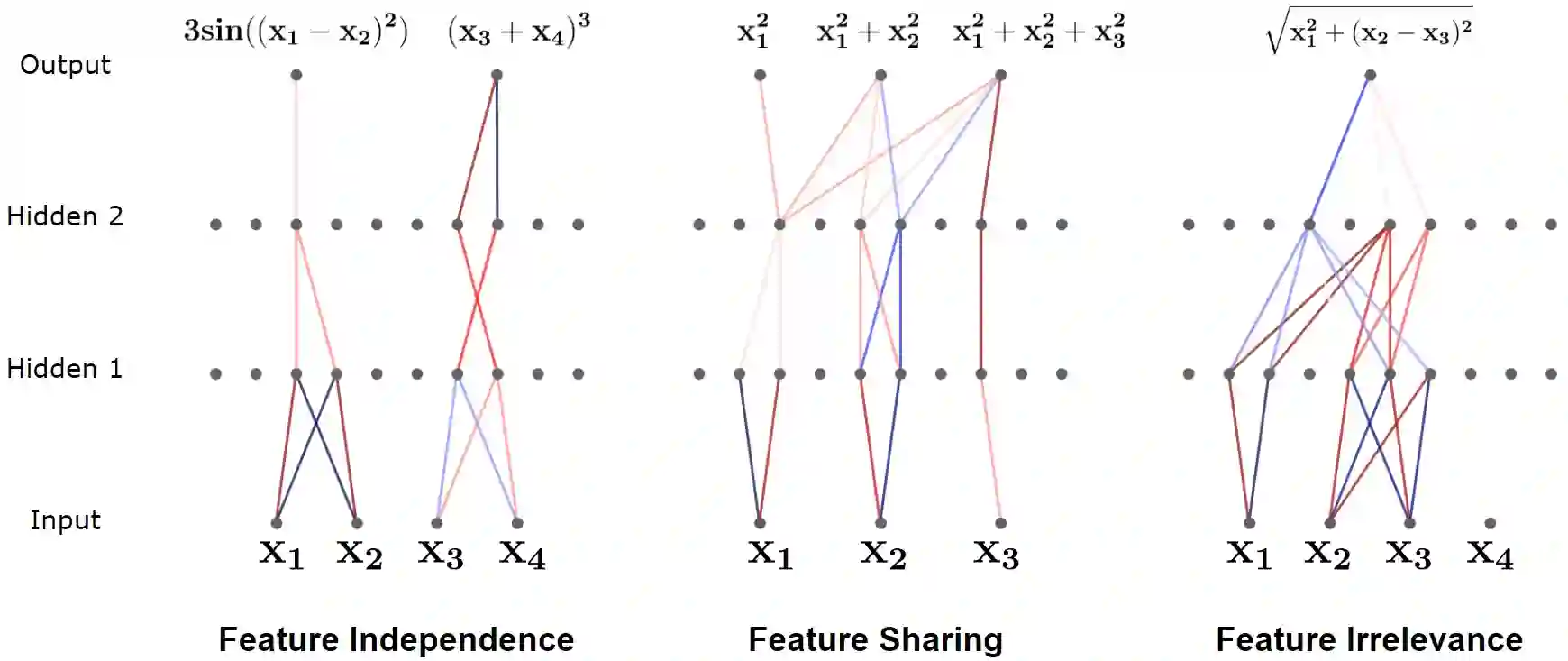
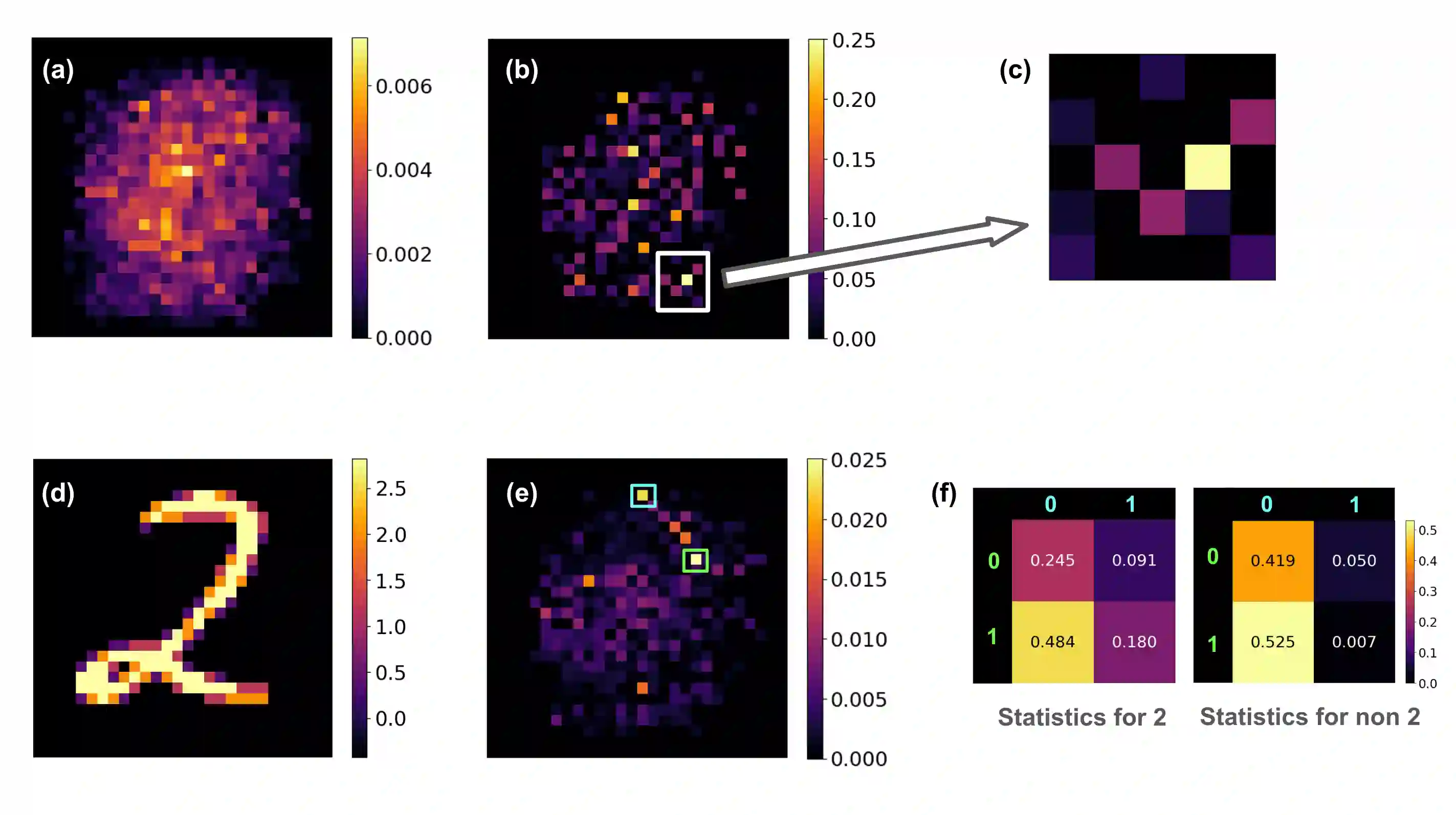
The rapid increase in the parameters of deep learning models has led to significant costs, challenging computational efficiency and model interpretability. In this paper, we introduce a novel and straightforward neural network pruning framework that incorporates the Gumbel-Softmax technique. This framework enables the simultaneous optimization of a network's weights and topology in an end-to-end process using stochastic gradient descent. Empirical results demonstrate its exceptional compression capability, maintaining high accuracy on the MNIST dataset with only 0.15\% of the original network parameters. Moreover, our framework enhances neural network interpretability, not only by allowing easy extraction of feature importance directly from the pruned network but also by enabling visualization of feature symmetry and the pathways of information propagation from features to outcomes. Although the pruning strategy is learned through deep learning, it is surprisingly intuitive and understandable, focusing on selecting key representative features and exploiting data patterns to achieve extreme sparse pruning. We believe our method opens a promising new avenue for deep learning pruning and the creation of interpretable machine learning systems.
翻译:深度学习模型参数量的快速增长导致了显著的计算成本,对计算效率和模型可解释性提出了挑战。本文提出了一种新颖且简洁的神经网络剪枝框架,该框架引入了Gumbel-Softmax技术。该框架能够通过随机梯度下降,以端到端的方式同时优化网络的权重和拓扑结构。实验结果表明,该框架具有卓越的压缩能力,在仅保留原始网络参数0.15%的情况下,仍能在MNIST数据集上保持高精度。此外,我们的框架增强了神经网络的可解释性,不仅能够直接从剪枝后的网络中轻松提取特征重要性,还能可视化特征对称性以及从特征到结果的信息传播路径。尽管剪枝策略是通过深度学习习得的,但它出人意料地直观且易于理解,侧重于选择关键代表性特征并利用数据模式以实现极端稀疏剪枝。我们相信,该方法为深度学习剪枝和构建可解释机器学习系统开辟了一条有前景的新途径。