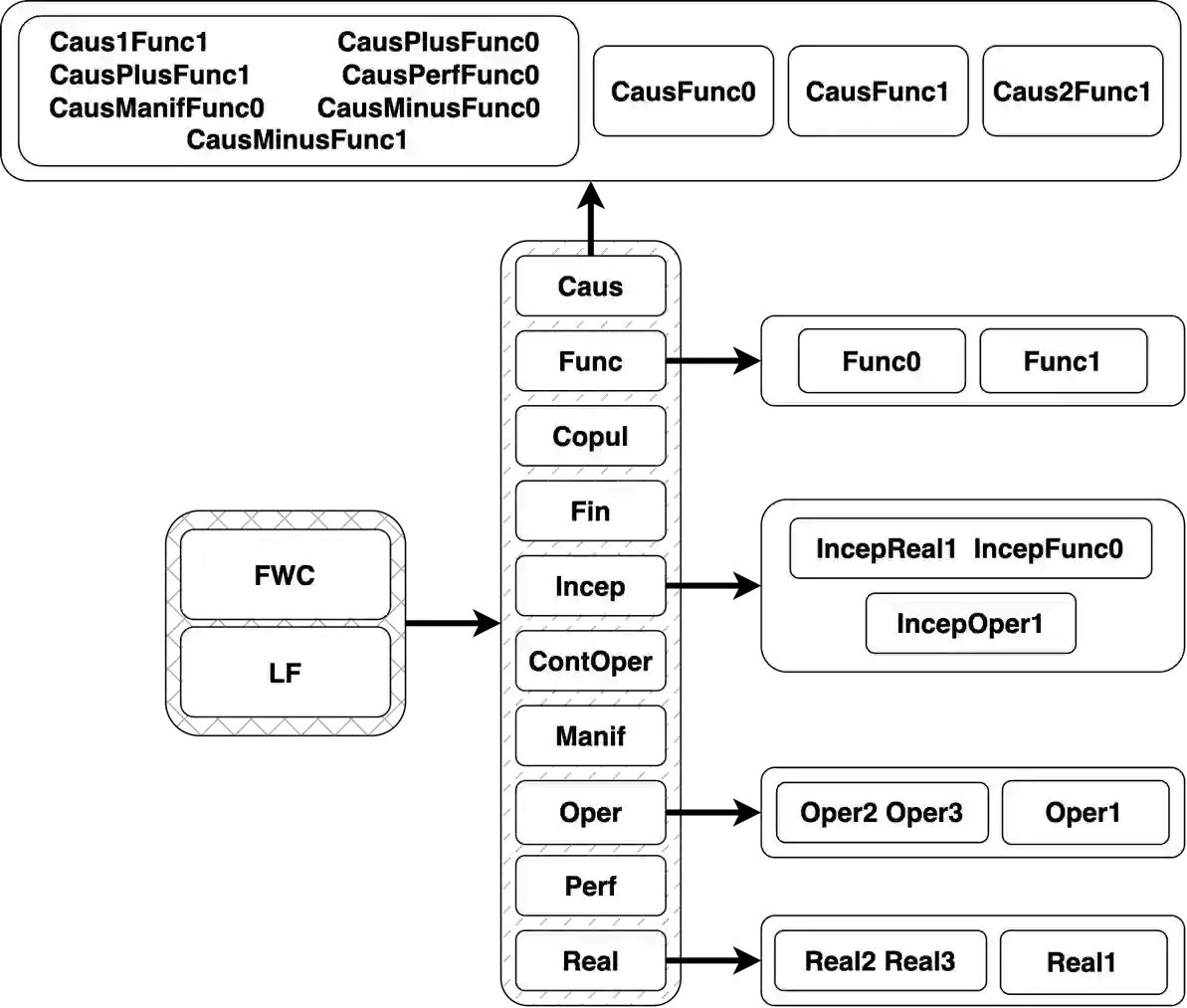
In natural language processing (NLP), lexical function is a concept to unambiguously represent semantic and syntactic features of words and phrases in text first crafted in the Meaning-Text Theory. Hierarchical classification of lexical functions involves organizing these features into a tree-like hierarchy of categories or labels. This is a challenging task as it requires a good understanding of the context and the relationships among words and phrases in text. It also needs large amounts of labeled data to train language models effectively. In this paper, we present a dataset of most frequent Spanish verb-noun collocations and sentences where they occur, each collocation is assigned to one of 37 lexical functions defined as classes for a hierarchical classification task. Each class represents a relation between the noun and the verb in a collocation involving their semantic and syntactic features. We combine the classes in a tree-based structure, and introduce classification objectives for each level of the structure. The dataset was created by dependency tree parsing and matching of the phrases in Spanish news. We provide baselines and data splits for each objective.
翻译:在自然语言处理中,词汇函数是一个用于无歧义表征文本中词语与短语语义及句法特征的概念,最早在“意义-文本理论”中被提出。词汇函数的层级分类涉及将这些特征组织成树状的类别或标签层级结构。这是一项具有挑战性的任务,因为它要求深入理解文本中词语与短语之间的上下文关系,同时需要大量标注数据来有效训练语言模型。本文构建了一个包含高频西班牙语动名搭配及其所在句子的数据集,每个搭配被分配至37种词汇函数之一,这些函数被定义为层级分类任务的类别。每个类别代表搭配中名词与动词在语义和句法特征上的一种关系。我们将这些类别整合为树状结构,并针对该结构的每一层级设定了分类目标。该数据集通过西班牙语新闻的依存句法解析与短语匹配生成,同时提供了每个分类目标的基线结果与数据划分方案。