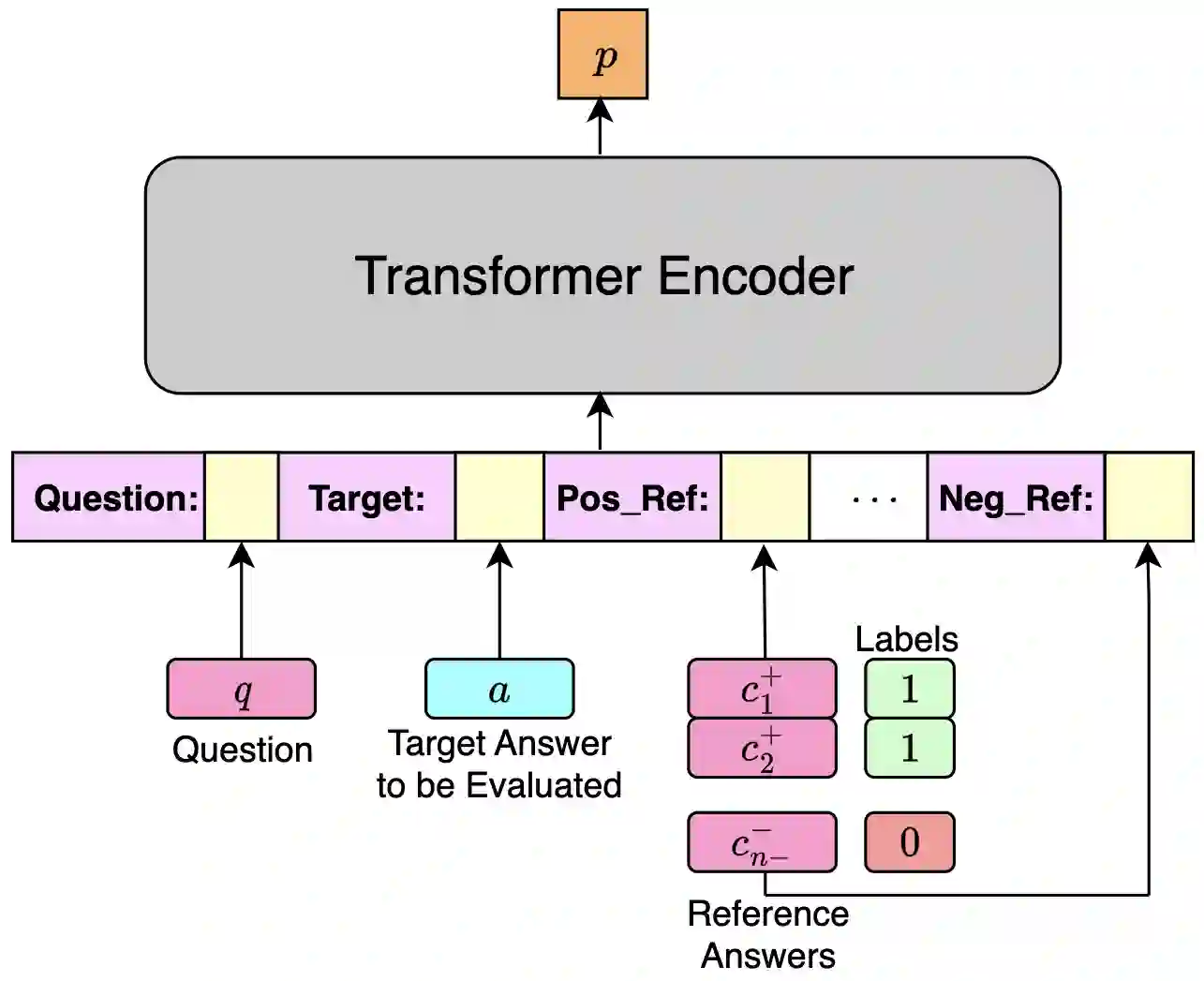
Evaluation of QA systems is very challenging and expensive, with the most reliable approach being human annotations of correctness of answers for questions. Recent works (AVA, BEM) have shown that transformer LM encoder based similarity metrics transfer well for QA evaluation, but they are limited by the usage of a single correct reference answer. We propose a new evaluation metric: SQuArE (Sentence-level QUestion AnsweRing Evaluation), using multiple reference answers (combining multiple correct and incorrect references) for sentence-form QA. We evaluate SQuArE on both sentence-level extractive (Answer Selection) and generative (GenQA) QA systems, across multiple academic and industrial datasets, and show that it outperforms previous baselines and obtains the highest correlation with human annotations.
翻译:问答系统的评估极具挑战性且成本高昂,最可靠的方法是通过人工标注判断问题答案的正确性。近期研究(AVA, BEM)表明,基于Transformer语言模型编码器的相似度度量在问答评估中表现良好,但其局限性在于仅依赖单一正确参考答案。本文提出一种新的评估指标:SQuArE(句子级问答评估),通过融合多个参考答案(结合多个正确与错误参考)对句子形式的问答系统进行评估。我们在多个学术与工业数据集上,对句子级抽取式(答案选择)和生成式(GenQA)问答系统进行了SQuArE评估,结果表明其性能优于现有基线方法,且与人工标注的相关性最高。