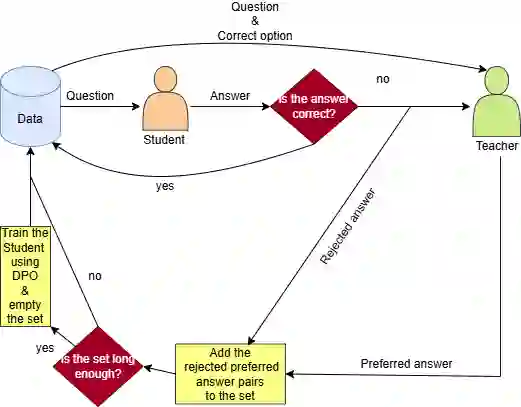
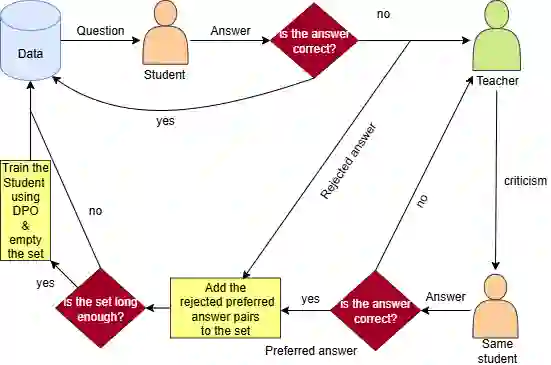
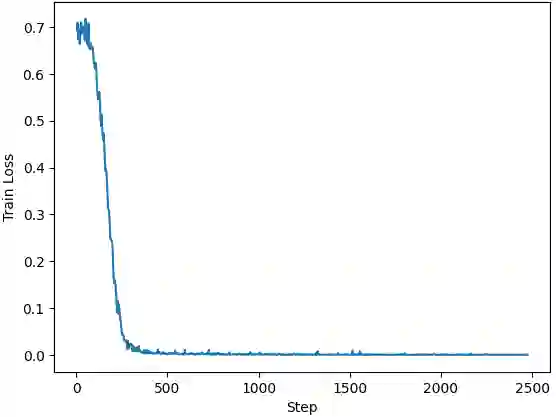
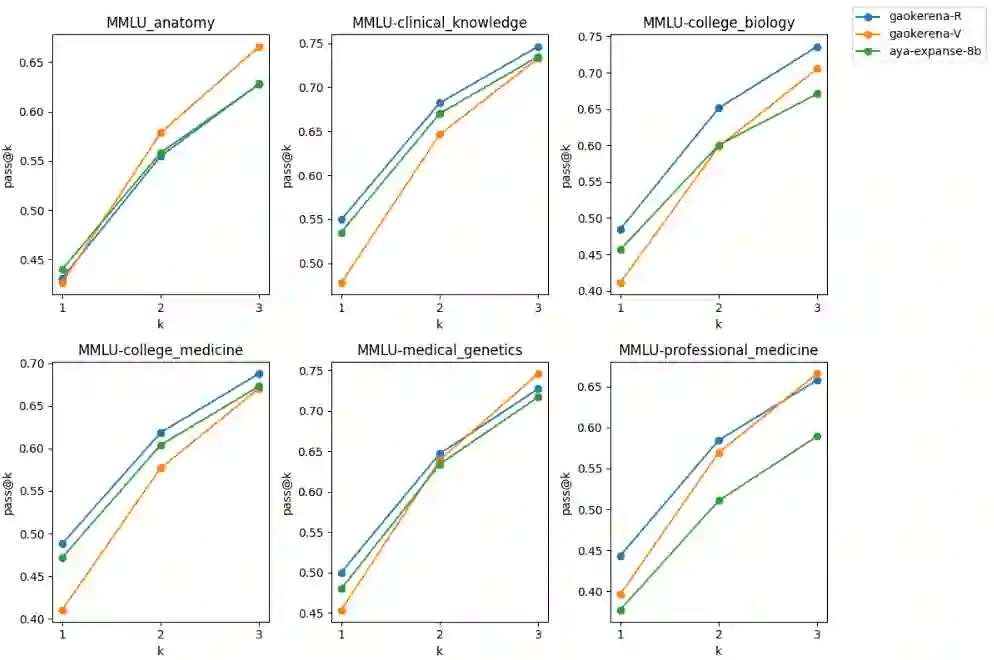
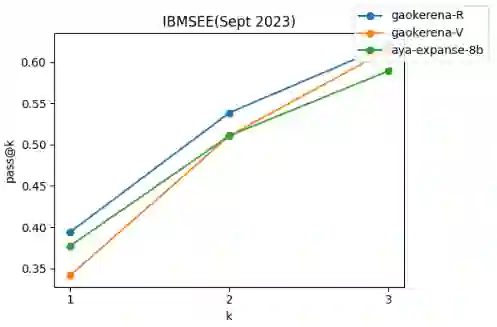
Enhancing reasoning capabilities in small language models is critical for specialized applications such as medical question answering, particularly in underrepresented languages like Persian. In this study, we employ Reinforcement Learning with AI Feedback (RLAIF) and Direct preference optimization (DPO) to improve the reasoning skills of a general-purpose Persian language model. To achieve this, we translated a multiple-choice medical question-answering dataset into Persian and used RLAIF to generate rejected-preferred answer pairs, which are essential for DPO training. By prompting both teacher and student models to produce Chain-of-Thought (CoT) reasoning responses, we compiled a dataset containing correct and incorrect reasoning trajectories. This dataset, comprising 2 million tokens in preferred answers and 2.5 million tokens in rejected ones, was used to train a baseline model, significantly enhancing its medical reasoning capabilities in Persian. Remarkably, the resulting model outperformed its predecessor, gaokerena-V, which was trained on approximately 57 million tokens, despite leveraging a much smaller dataset. These results highlight the efficiency and effectiveness of reasoning-focused training approaches in developing domain-specific language models with limited data availability.
翻译:在医学问答等专业应用中,提升小型语言模型的推理能力至关重要,尤其是在波斯语等代表性不足的语言中。本研究采用基于人工智能反馈的强化学习(RLAIF)与直接偏好优化(DPO)方法,以增强通用波斯语语言模型的推理技能。为实现这一目标,我们将一个多项选择医学问答数据集翻译为波斯语,并利用RLAIF生成拒绝-偏好答案对,这是DPO训练的关键数据。通过引导教师模型和学生模型生成思维链(CoT)推理响应,我们构建了一个包含正确与错误推理轨迹的数据集。该数据集包含200万标记的偏好答案与250万标记的拒绝答案,用于训练基线模型,显著提升了其在波斯语医学推理方面的能力。值得注意的是,尽管所用数据集规模远小于其前代模型gaokerena-V(训练数据约5700万标记),所得模型的表现仍超越了后者。这些结果凸显了以推理为核心的训练方法在数据有限条件下开发领域专用语言模型的高效性与有效性。