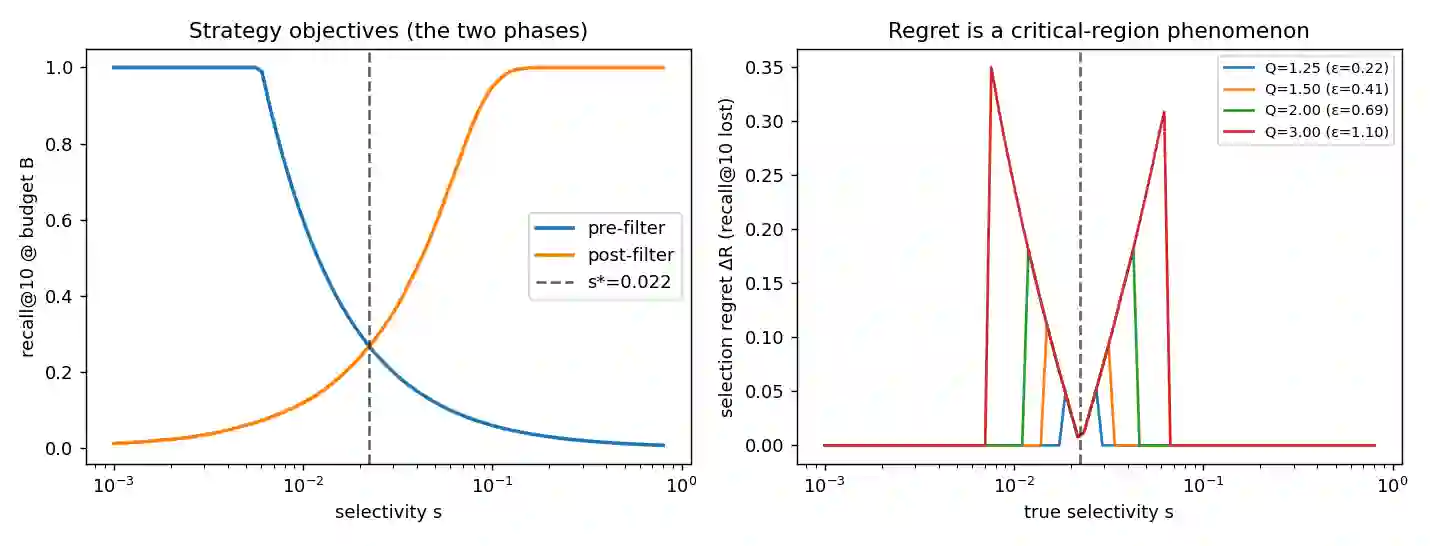
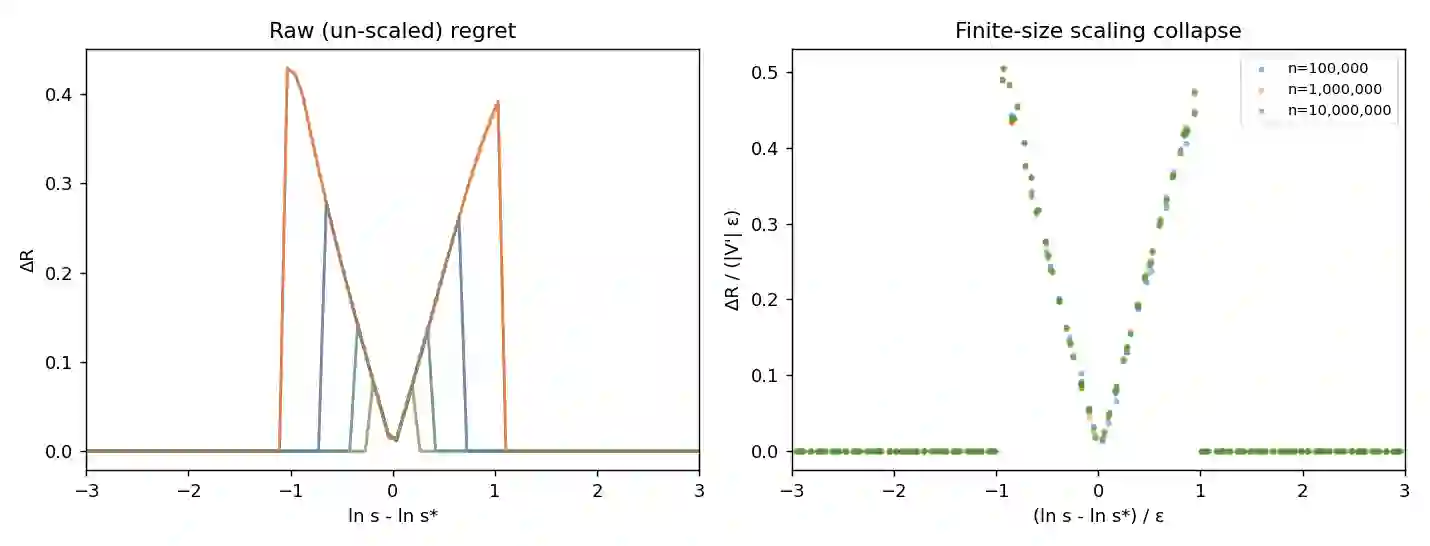
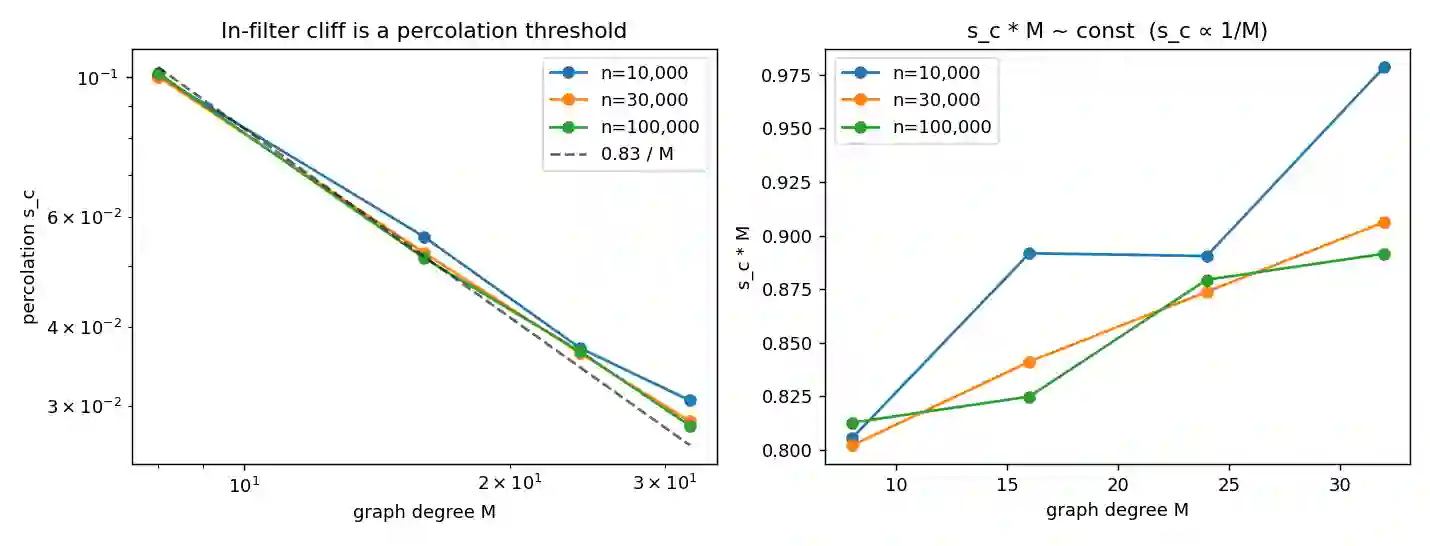
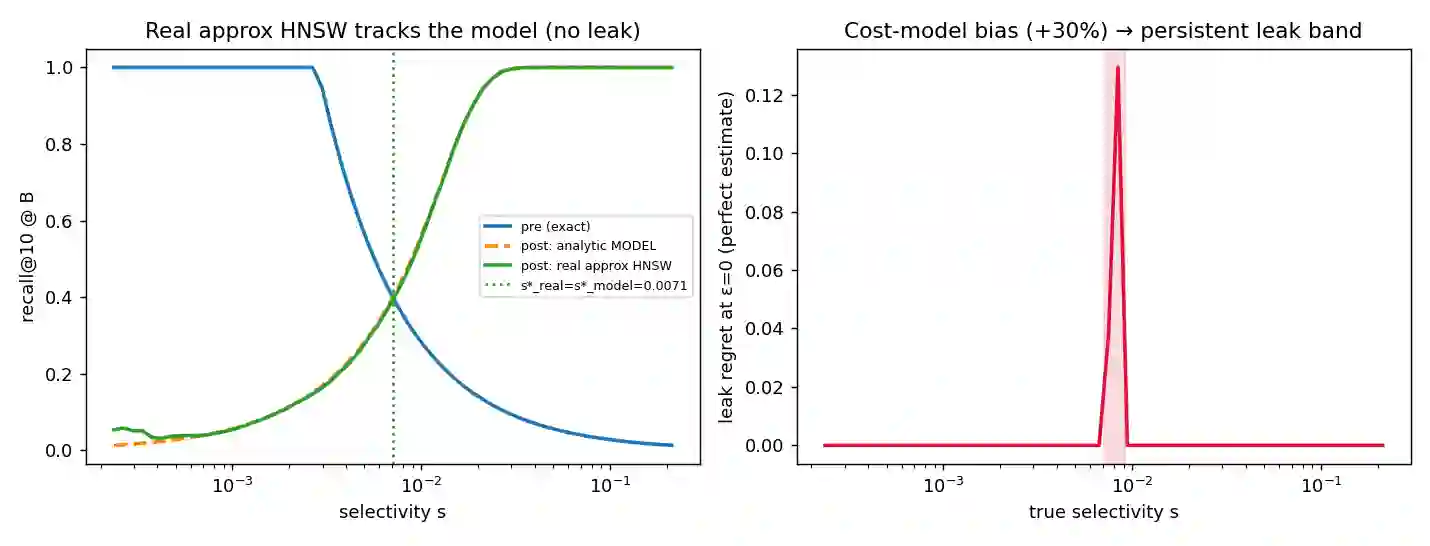
A filtered approximate-nearest-neighbor (ANN) query returns the k nearest vectors among those satisfying an attribute predicate P of selectivity s. The best execution strategy -- pre-filter, post-filter, or in-filter -- changes with s, so a system must estimate s and choose. We model this as an argmax over a landscape with phases (regions where each strategy wins) separated by boundaries, and show that selectivity-estimation error produces plan regret -- recall lost versus the oracle strategy -- only in the critical regions around those boundaries. The regret is a wedge of log-width equal to the multiplicative estimation error epsilon and height equal to the local cliff |V'(s*)| epsilon; the flip-margin 1/|V'(s*)| is the condition number of a sibling cardinality-estimation study reappearing as the local boundary theory. The two phase boundaries follow from independent mathematics: order statistics place the post-filter cliff at s ~ k/K, and site percolation places the in-filter cliff at s_c ~ 0.83/M for graph degree M (corpus-size independent). Criticality exists only under a constrained budget B < sqrt(k n). Under pre-registered decision rules we confirm, on synthetic sweeps and real SIFT1M, that regret concentrates ~290x at the boundary and that the regret curves obey a finite-size scaling collapse onto one universal wedge across two decades of corpus size. A real approximate index does not mis-locate the boundary, but a biased cost model opens a persistent miscalibration band that estimation-error robustness cannot fix. The contribution is a characterization, not a new index. Code and the full pre-registration are public.
翻译:滤波近似最近邻(ANN)查询返回满足属性谓词P(选择性为s)的k个最近向量。最优执行策略——预过滤、后过滤或内过滤——随s变化,因此系统必须估计s并做出选择。我们将此建模为在具有相(各策略获胜区域)的景观上的argmax问题,这些相由边界分隔,并证明选择性估计误差仅在边界附近的临界区域产生计划遗憾(相对于最优策略的召回损失)。该遗憾是一个楔形区域,其对数宽度等于乘法估计误差ε,高度等于局部悬崖|V'(s*)|ε;翻转边界1/|V'(s*)|是作为局部边界理论重新出现的兄弟基数估计研究的条件数。两个相边界源自独立的数学理论:次序统计将后过滤悬崖定位在s~k/K处,而格点渗流将内过滤悬崖定位在s_c~0.83/M处(M为图度数,与语料库规模无关)。临界性仅在受限预算B<√(k n)下存在。在预注册决策规则下,我们在合成扫描和真实SIFT1M上证实,遗憾在边界处集中约290倍,且遗憾曲线在不同语料库规模的两个数量级范围内服从有限尺寸标度塌缩至一个通用楔形。真实近似索引不会错误定位边界,但有偏成本模型会打开一个持续存在的校准偏差带,而估计误差鲁棒性无法修复此问题。本贡献在于刻画而非提出新索引。代码及完整预注册信息已公开。