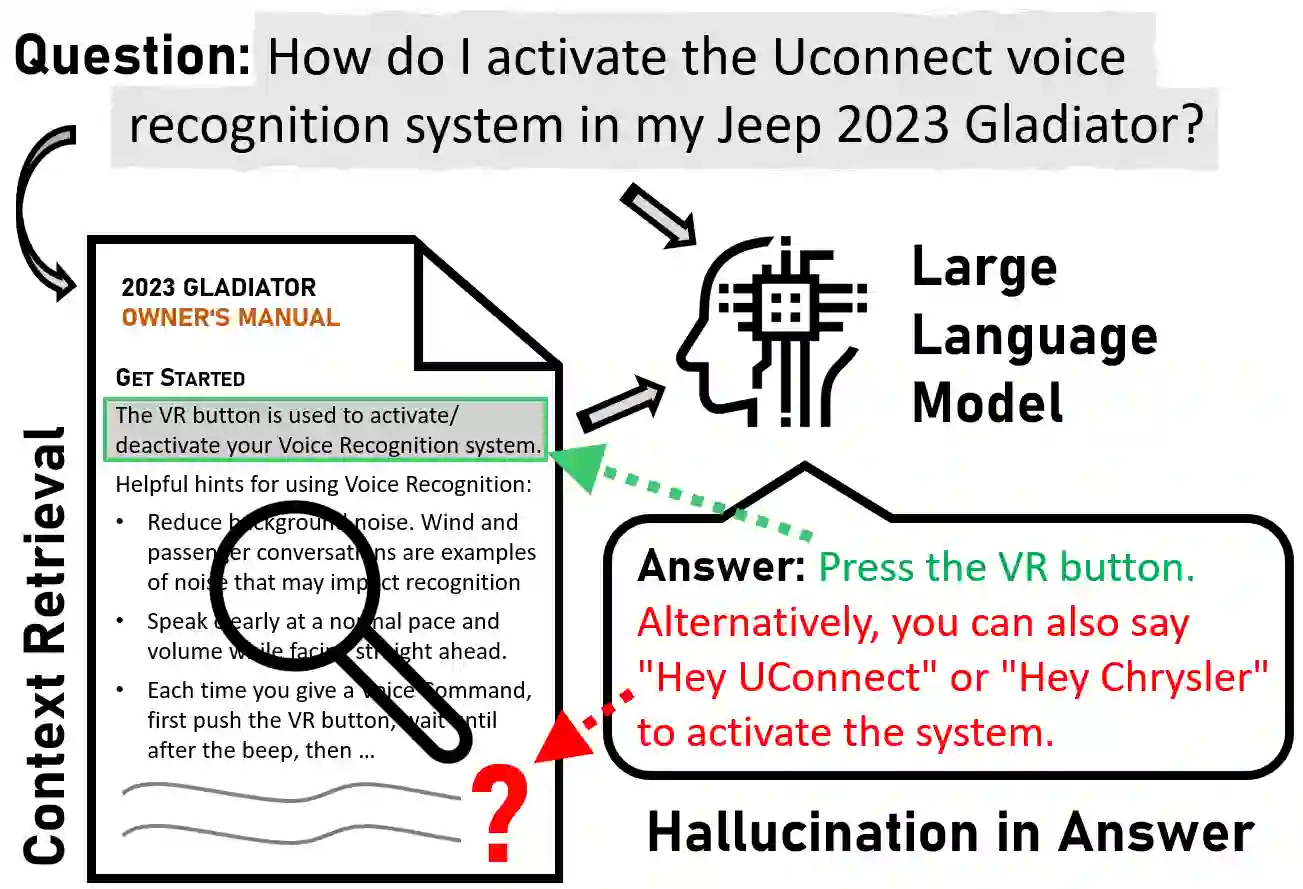
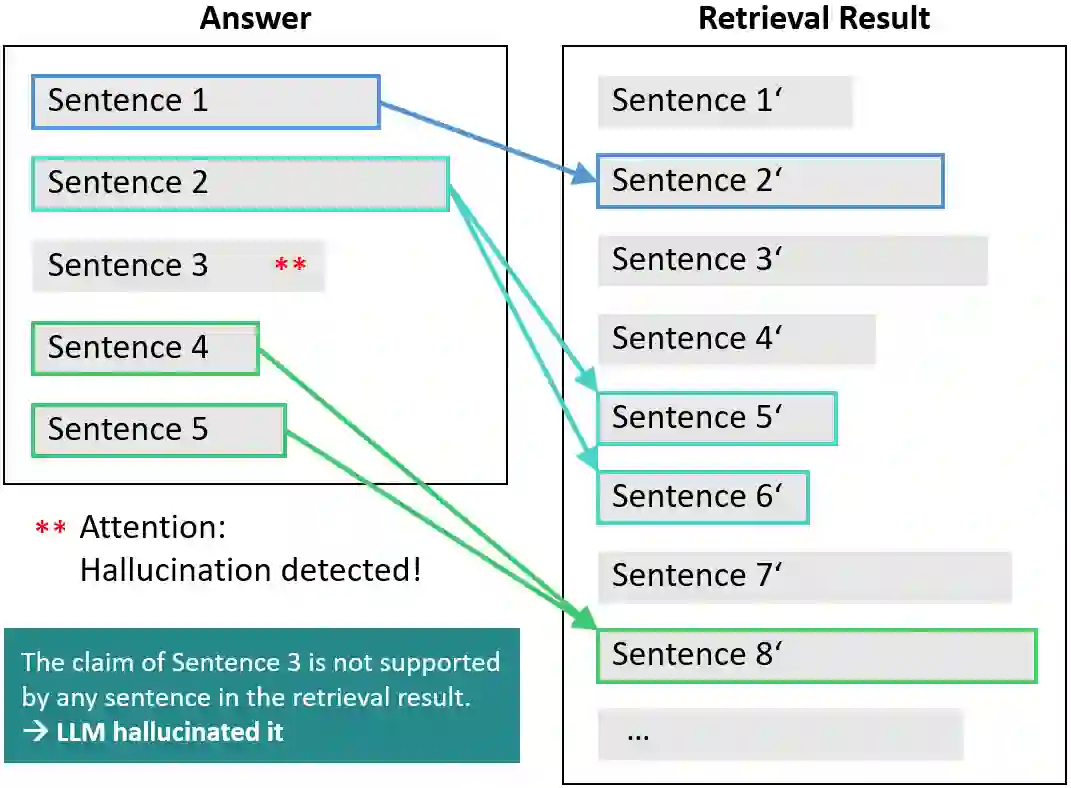
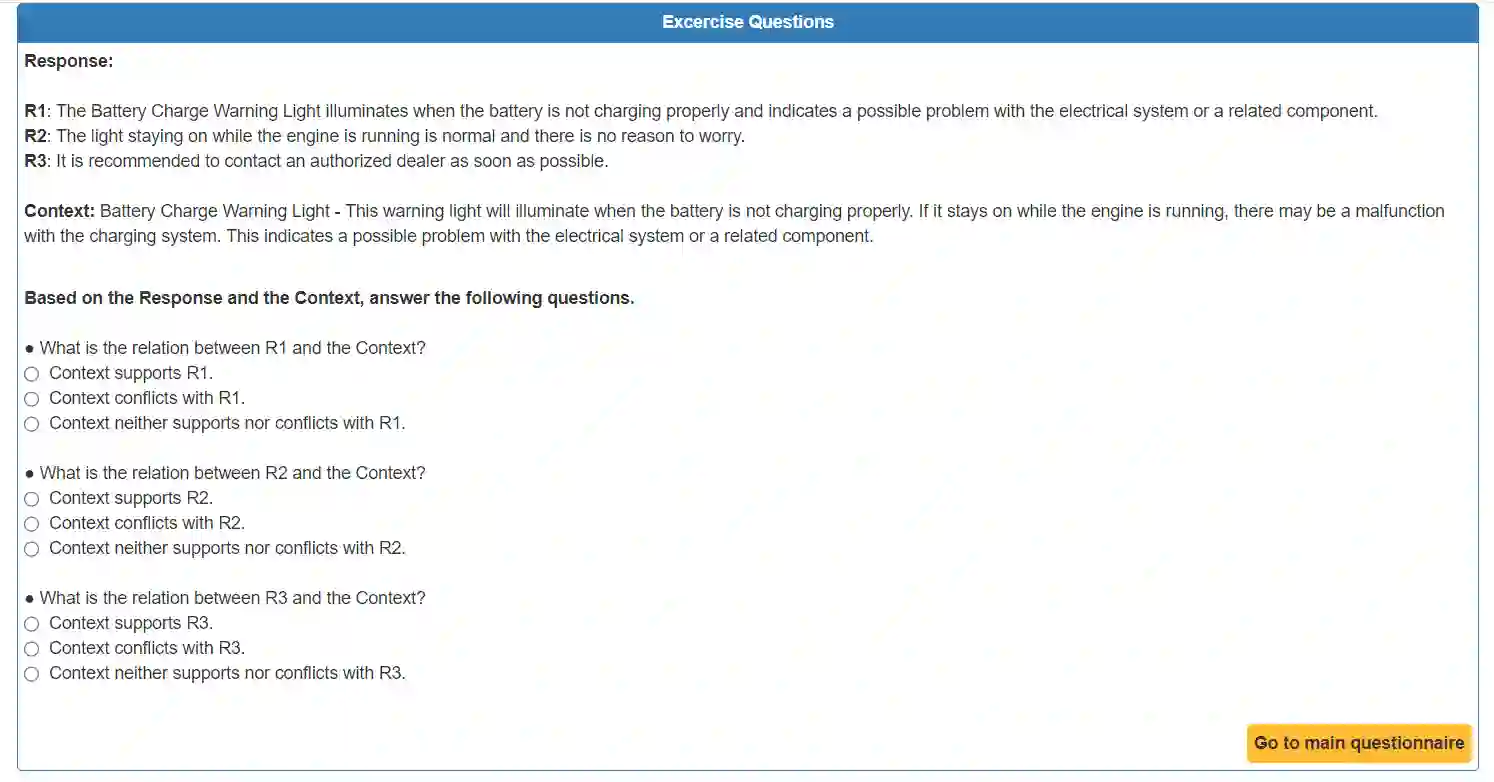
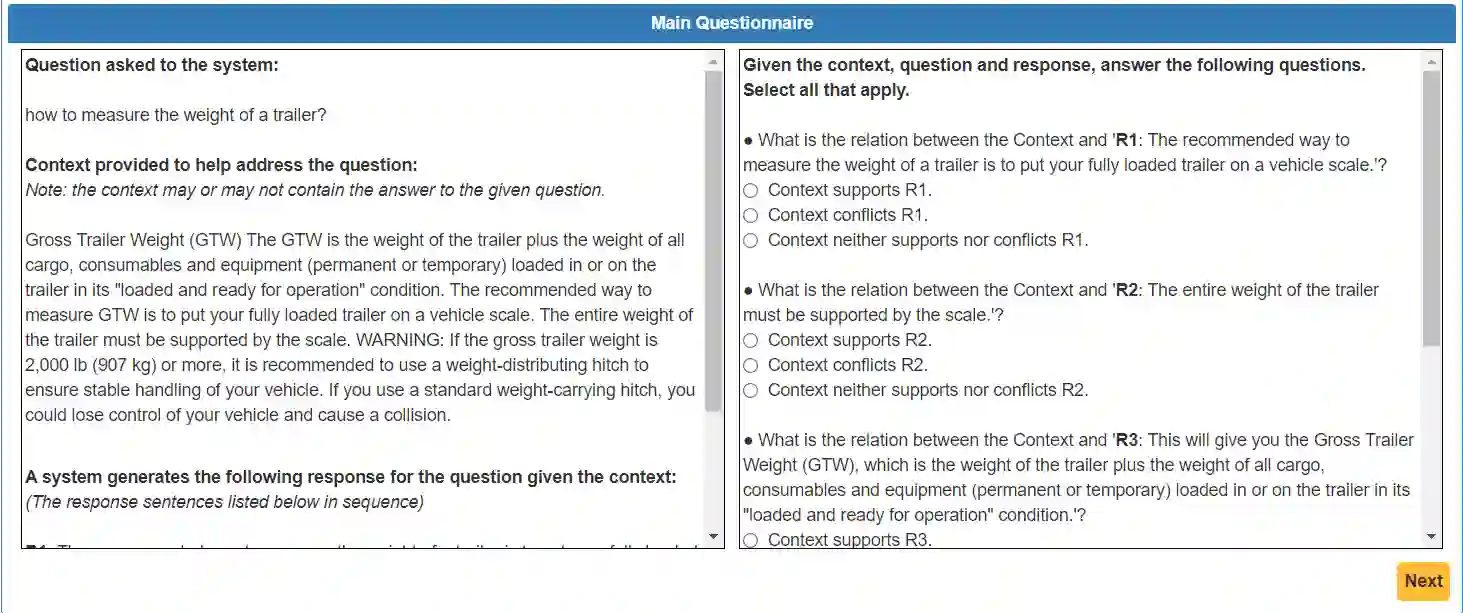
Hallucination is a well-known phenomenon in text generated by large language models (LLMs). The existence of hallucinatory responses is found in almost all application scenarios e.g., summarization, question-answering (QA) etc. For applications requiring high reliability (e.g., customer-facing assistants), the potential existence of hallucination in LLM-generated text is a critical problem. The amount of hallucination can be reduced by leveraging information retrieval to provide relevant background information to the LLM. However, LLMs can still generate hallucinatory content for various reasons (e.g., prioritizing its parametric knowledge over the context, failure to capture the relevant information from the context, etc.). Detecting hallucinations through automated methods is thus paramount. To facilitate research in this direction, we introduce a sophisticated dataset, DelucionQA, that captures hallucinations made by retrieval-augmented LLMs for a domain-specific QA task. Furthermore, we propose a set of hallucination detection methods to serve as baselines for future works from the research community. Analysis and case study are also provided to share valuable insights on hallucination phenomena in the target scenario.
翻译:幻觉是大语言模型(LLM)生成文本中广为人知的现象。几乎在所有应用场景(如摘要生成、问答等)中均存在幻觉响应。对于需要高可靠性的应用(例如面向客户的助手),LLM生成文本中可能存在的幻觉是一个关键问题。通过利用信息检索为LLM提供相关背景信息,可降低幻觉发生频率。然而,由于多种原因(如优先采用参数化知识而非上下文信息、未能从上下文中捕获相关内容等),LLM仍可能生成幻觉内容。因此,通过自动化方法检测幻觉至关重要。为促进该方向的研究,我们引入了一个精良的数据集DelucionQA,该数据集捕捉了检索增强型LLM在领域特定问答任务中产生的幻觉。此外,我们提出了一套幻觉检测方法,作为研究社区未来工作的基线。同时,通过分析与案例研究,我们针对目标场景中的幻觉现象提供了有价值的见解。