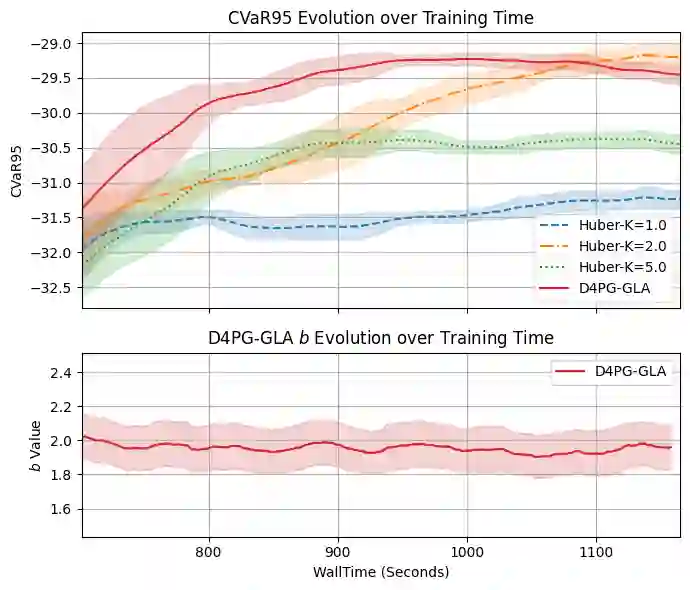
Distributional Reinforcement Learning (RL) estimates return distribution mainly by learning quantile values via minimizing the quantile Huber loss function, entailing a threshold parameter often selected heuristically or via hyperparameter search, which may not generalize well and can be suboptimal. This paper introduces a generalized quantile Huber loss function derived from Wasserstein distance (WD) calculation between Gaussian distributions, capturing noise in predicted (current) and target (Bellman-updated) quantile values. Compared to the classical quantile Huber loss, this innovative loss function enhances robustness against outliers. Notably, the classical Huber loss function can be seen as an approximation of our proposed loss, enabling parameter adjustment by approximating the amount of noise in the data during the learning process. Empirical tests on Atari games, a common application in distributional RL, and a recent hedging strategy using distributional RL, validate the effectiveness of our proposed loss function and its potential for parameter adjustments in distributional RL.
翻译:分布强化学习主要通过最小化分位数Huber损失函数来学习分位数值,从而估计回报分布。该函数含有一个阈值参数,通常通过启发式方法或超参数搜索确定,这可能导致泛化能力不足且结果非最优。本文提出一种基于高斯分布间Wasserstein距离计算得到的广义分位数Huber损失函数,该函数能捕获预测(当前)分位数值与目标(贝尔曼更新后)分位数值中的噪声。相较于经典的分位数Huber损失,这一创新型损失函数增强了对抗异常值的鲁棒性。值得注意的是,经典Huber损失函数可被视为我们提出的损失函数的近似形式,从而允许在学习过程中通过近似数据中的噪声量来进行参数调整。在分布强化学习常用基准Atari游戏以及近期基于分布强化学习的对冲策略上的实证测试,验证了我们提出的损失函数的有效性及其在分布强化学习中参数调整的潜力。