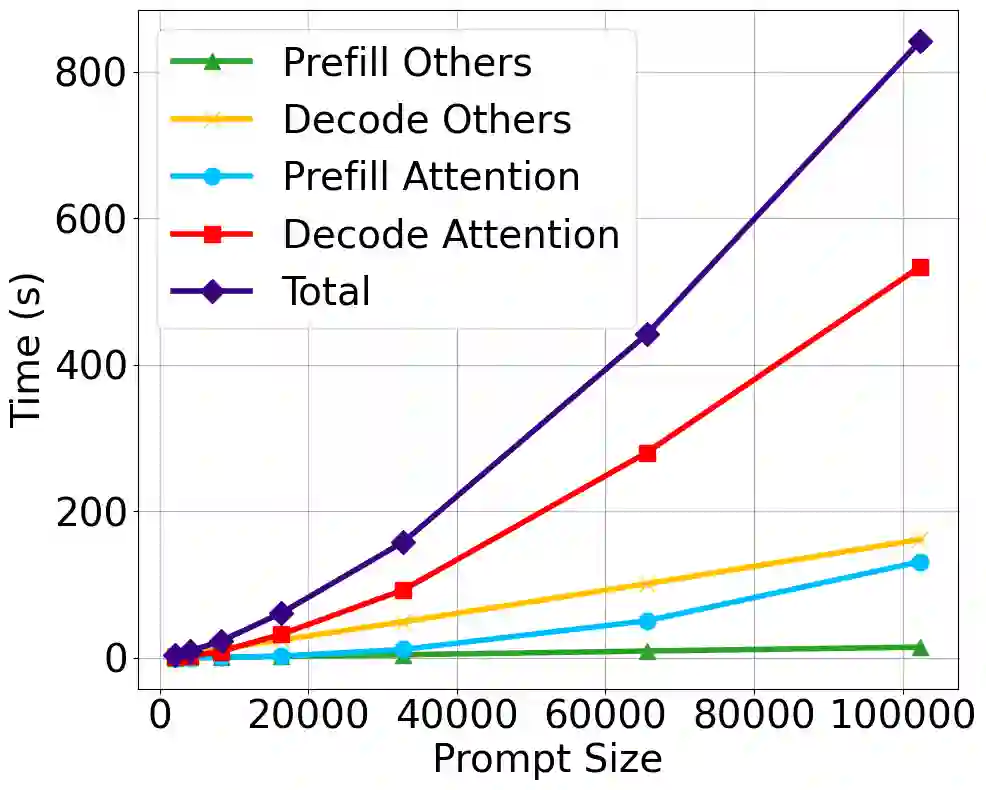
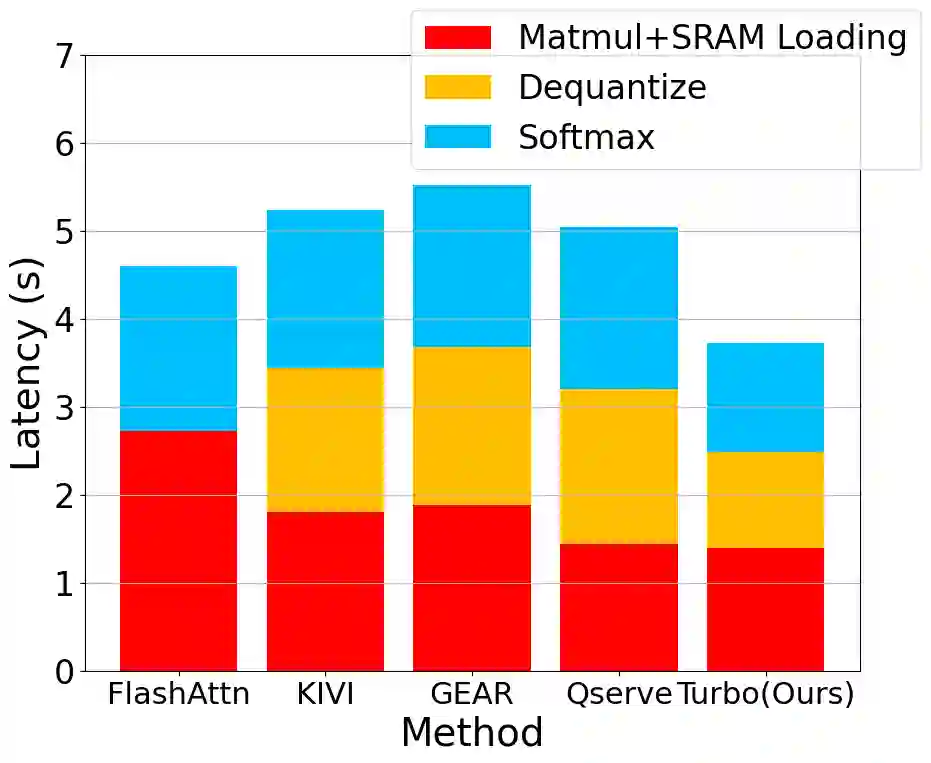
Large language model (LLM) inference demands significant amount of computation and memory, especially in the key attention mechanism. While techniques, such as quantization and acceleration algorithms, like FlashAttention, have improved efficiency of the overall inference, they address different aspects of the problem: quantization focuses on weight-activation operations, while FlashAttention improves execution but requires high-precision formats. Recent Key-value (KV) cache quantization reduces memory bandwidth but still needs floating-point dequantization for attention operation. We present TurboAttention, a comprehensive approach to enable quantized execution of attention that simultaneously addresses both memory and computational efficiency. Our solution introduces two key innovations: FlashQ, a headwise attention quantization technique that enables both compression of KV cache and quantized execution of activation-activation multiplication, and Sparsity-based Softmax Approximation (SAS), which eliminates the need for dequantization to FP32 during exponentiation operation in attention. Experimental results demonstrate that TurboAttention achieves 1.2-1.8x speedup in attention, reduces the KV cache size by over 4.4x, and enables up to 2.37x maximum throughput over the FP16 baseline while outperforming state-of-the-art quantization and compression techniques across various datasets and models.
翻译:大语言模型(LLM)推理需要大量的计算和内存资源,尤其是在关键的注意力机制部分。尽管量化技术和FlashAttention等加速算法提升了整体推理效率,但它们分别针对不同层面的问题:量化主要针对权重-激活运算,而FlashAttention虽能提升执行效率却需要高精度格式。近期的键值(KV)缓存量化技术虽能降低内存带宽,但在注意力运算中仍需进行浮点反量化。本文提出TurboAttention,一种实现注意力量化执行的综合性方案,可同时提升内存与计算效率。我们的方案包含两项核心创新:FlashQ——一种支持KV缓存压缩与激活-激活乘法量化执行的头部注意力量化技术;以及基于稀疏性的Softmax近似方法(SAS)——该技术消除了注意力运算中指数计算环节对FP32反量化的需求。实验结果表明,TurboAttention在注意力计算中实现了1.2-1.8倍加速,将KV缓存大小缩减超过4.4倍,并在FP16基线基础上达成最高2.37倍吞吐量提升,同时在多种数据集和模型上超越了当前最先进的量化与压缩技术。