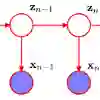
The Hidden Markov Model (HMM) is one of the most widely used statistical models for sequential data analysis, and it has been successfully applied in a large variety of domains. One of the key reasons for this versatility is the ability of HMMs to deal with missing data. However, standard HMM learning algorithms rely crucially on the assumption that the positions of the missing observations within the observation sequence are known. In some situations where such assumptions are not feasible, a number of special algorithms have been developed. Currently, these algorithms rely strongly on specific structural assumptions of the underlying chain, such as acyclicity, and are not applicable in the general case. In particular, there are numerous domains within medicine and computational biology, where the missing observation locations are unknown and acyclicity assumptions do not hold, thus presenting a barrier for the application of HMMs in those fields. In this paper we consider a general problem of learning HMMs from data with unknown missing observation locations (i.e., only the order of the non-missing observations are known). We introduce a generative model of the location omissions and propose two learning methods for this model, a (semi) analytic approach, and a Gibbs sampler. We evaluate and compare the algorithms in a variety of scenarios, measuring their reconstruction precision and robustness under model misspecification.
翻译:隐马尔可夫模型(HMM)是序列数据分析中最广泛使用的统计模型之一,已在众多领域得到成功应用。这种通用性的关键原因之一在于HMM处理缺失数据的能力。然而,标准HMM学习算法严重依赖于一个假设:观测序列中缺失观测的位置是已知的。在某些无法满足此类假设的场景中,研究人员已开发出若干特殊算法。现有算法强烈依赖于底层链的特定结构假设(如无环性),无法在一般情况下适用。特别地,在医学和计算生物学的许多领域中,缺失观测位置未知且无环性假设不成立,这为HMM在这些领域的应用设置了障碍。本文研究从缺失观测位置未知的数据中学习HMM的通用问题(即仅已知非缺失观测的顺序)。我们提出了一种缺失位置生成模型,并为该模型设计了两种学习方法:一种(半)解析方法和一种吉布斯采样器。我们在多种场景下评估并比较了这些算法,测量了它们在模型误设情况下的重建精度和鲁棒性。