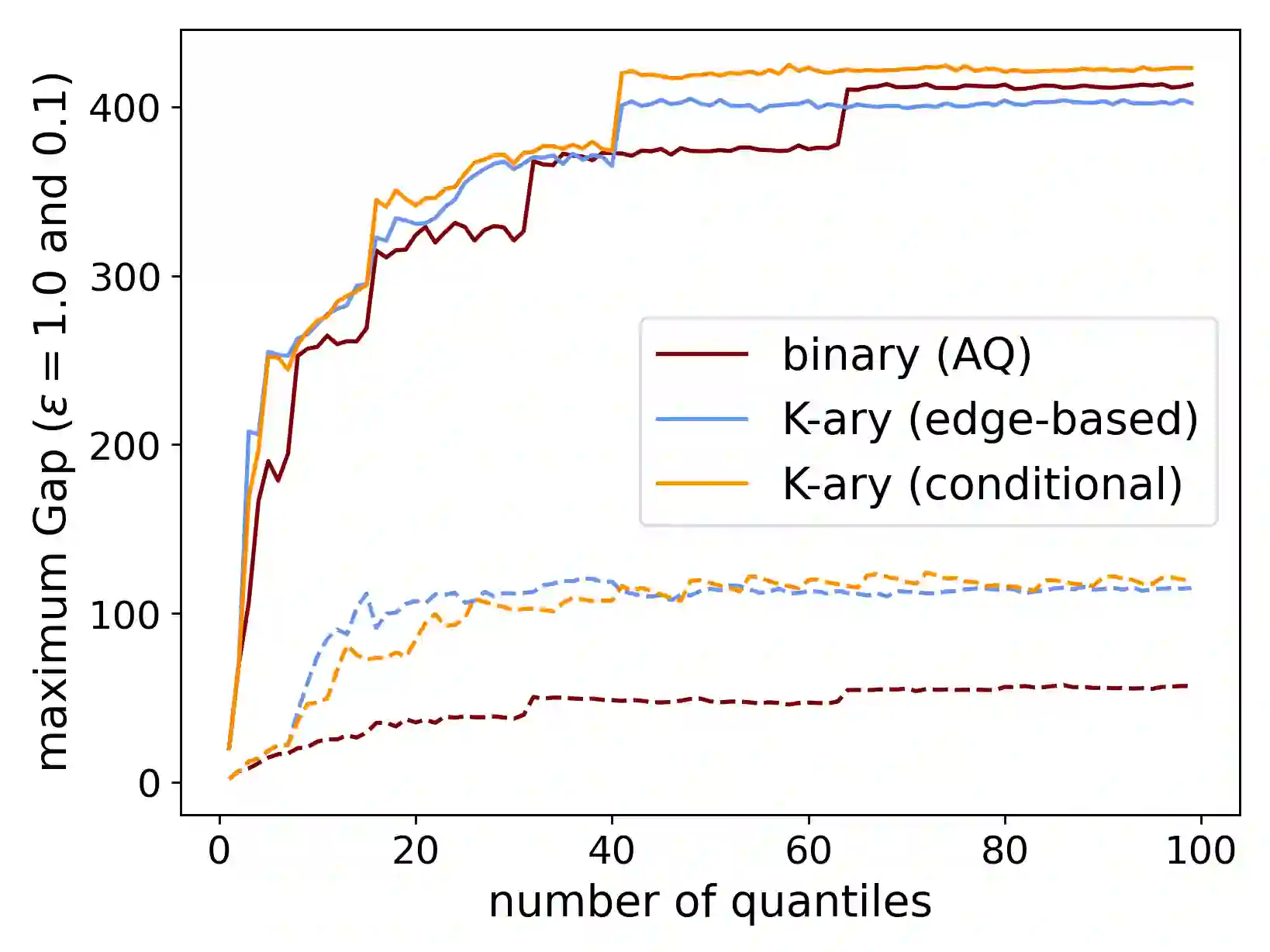
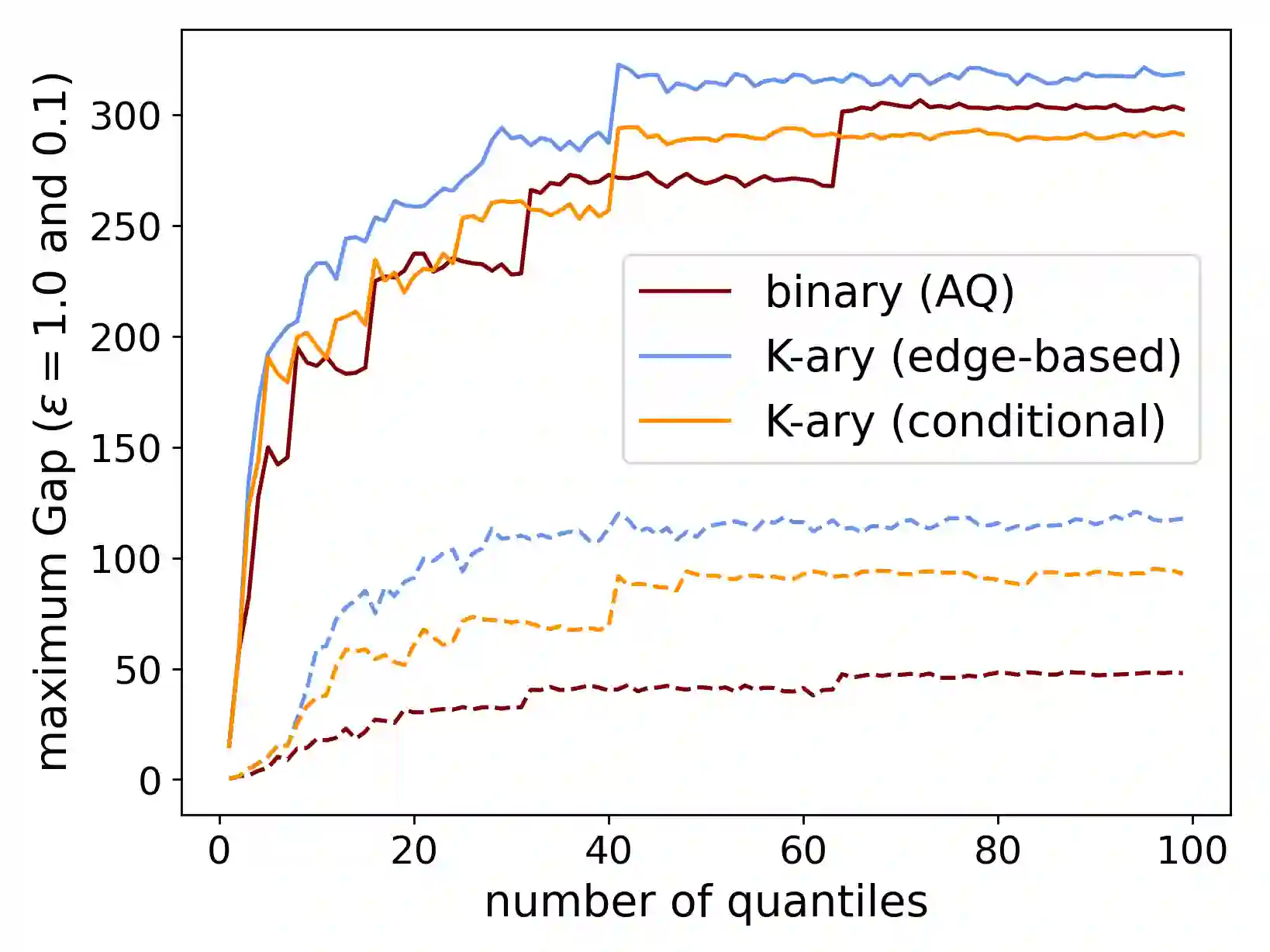
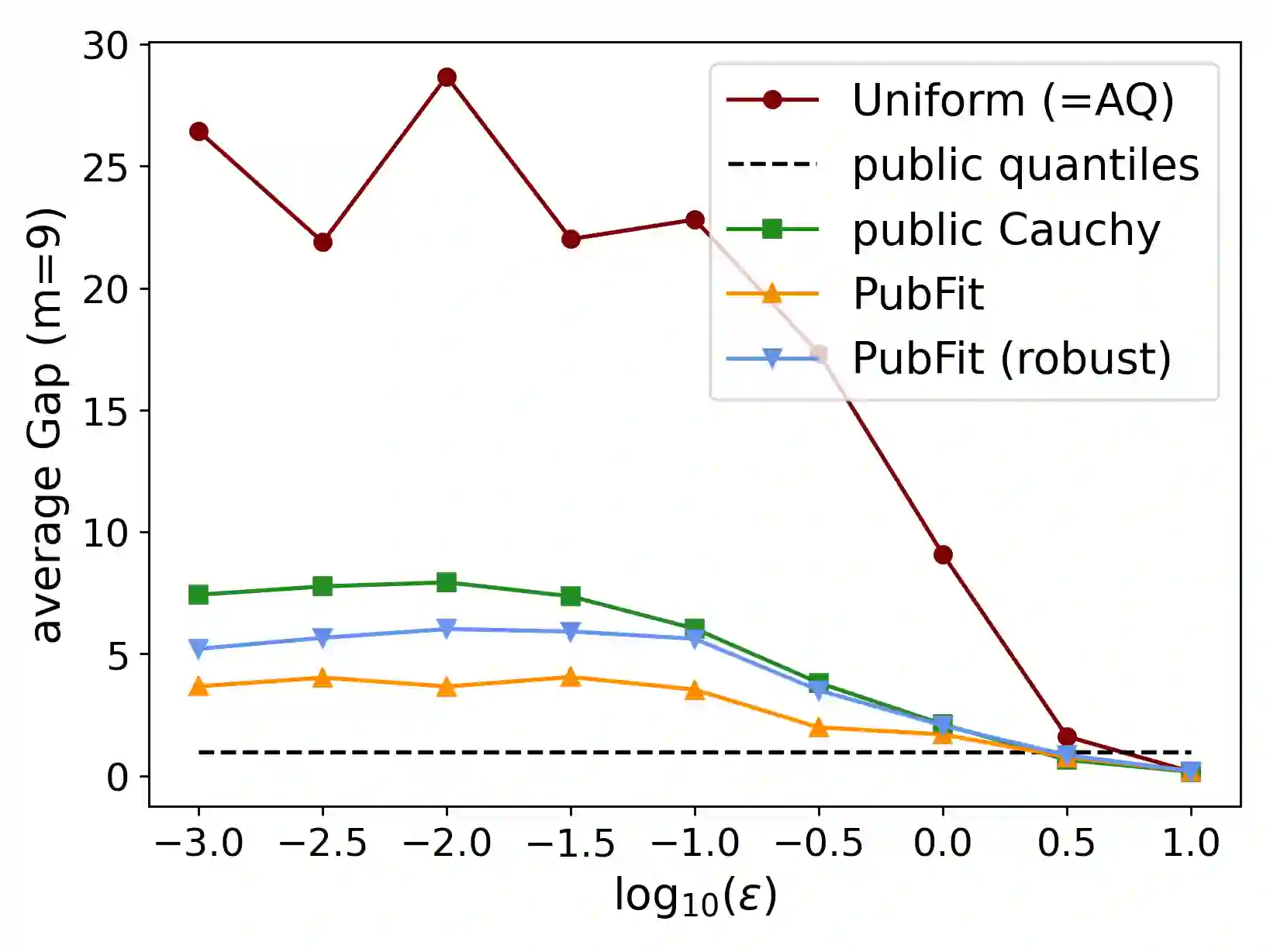
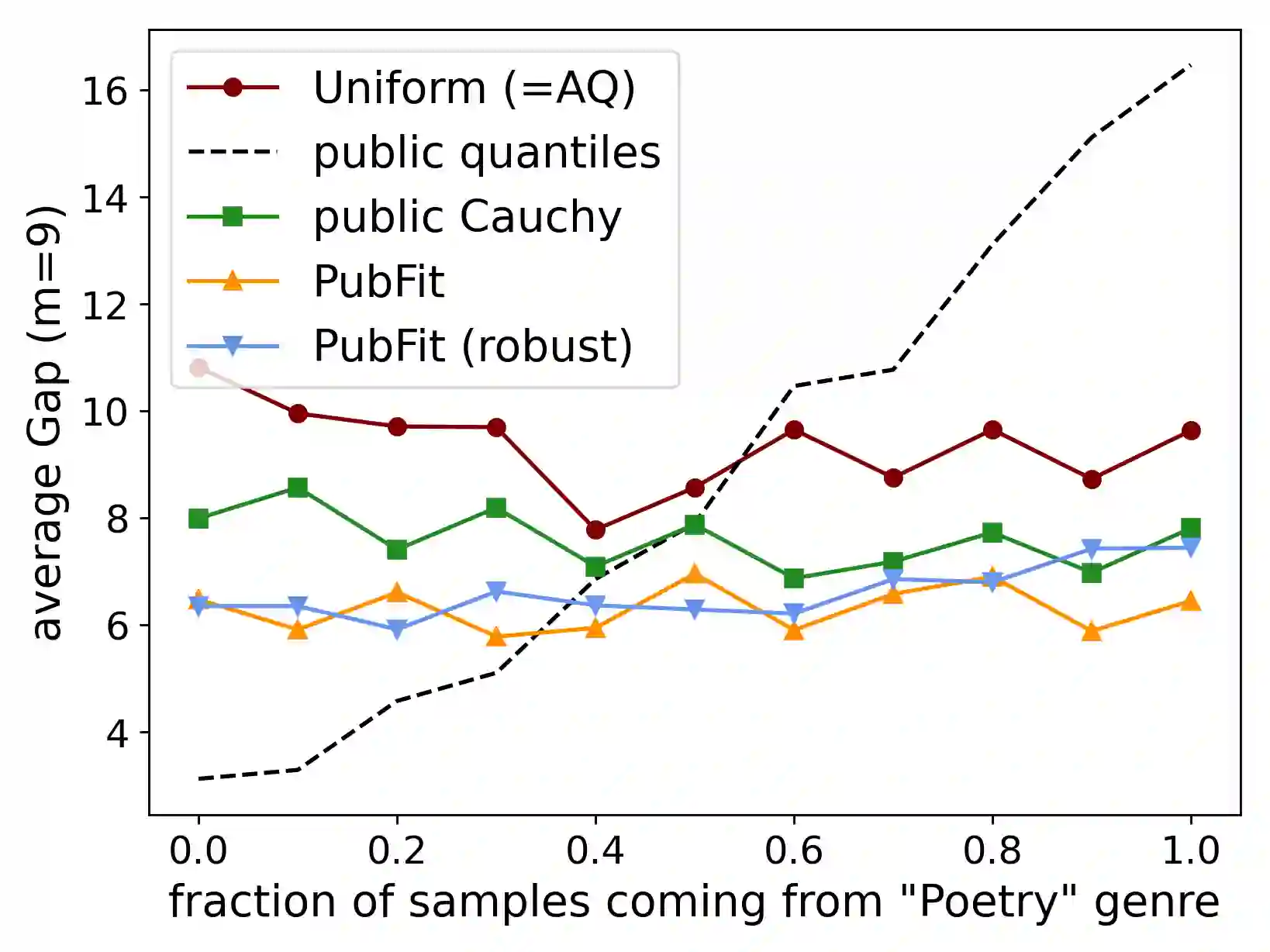
When applying differential privacy to sensitive data, we can often improve performance using external information such as other sensitive data, public data, or human priors. We propose to use the learning-augmented algorithms (or algorithms with predictions) framework -- previously applied largely to improve time complexity or competitive ratios -- as a powerful way of designing and analyzing privacy-preserving methods that can take advantage of such external information to improve utility. This idea is instantiated on the important task of multiple quantile release, for which we derive error guarantees that scale with a natural measure of prediction quality while (almost) recovering state-of-the-art prediction-independent guarantees. Our analysis enjoys several advantages, including minimal assumptions about the data, a natural way of adding robustness, and the provision of useful surrogate losses for two novel ``meta" algorithms that learn predictions from other (potentially sensitive) data. We conclude with experiments on challenging tasks demonstrating that learning predictions across one or more instances can lead to large error reductions while preserving privacy.
翻译:在将差分隐私应用于敏感数据时,我们通常可以利用外部信息(如其他敏感数据、公开数据或人类先验知识)来提升性能。本文提出将学习增强算法(或称带预测的算法)——此前主要应用于改善时间复杂度或竞争比——作为一种强大的设计与分析隐私保护方法的框架,使其能够利用此类外部信息提升效用。我们将这一思路具体应用于多次分位数发布这一重要任务,并推导出随预测质量的自然度量而缩放的误差保证,同时(几乎)恢复当前最优的无预测保证。我们的分析具有多项优势,包括对数据的最小假设、自然的鲁棒性增强方式,以及为两种新颖的从其他(可能敏感的)数据中学习预测的“元”算法提供有用的替代损失函数。最后,我们在具有挑战性的任务上通过实验证明,跨一个或多个实例学习预测能够在保护隐私的同时大幅降低误差。