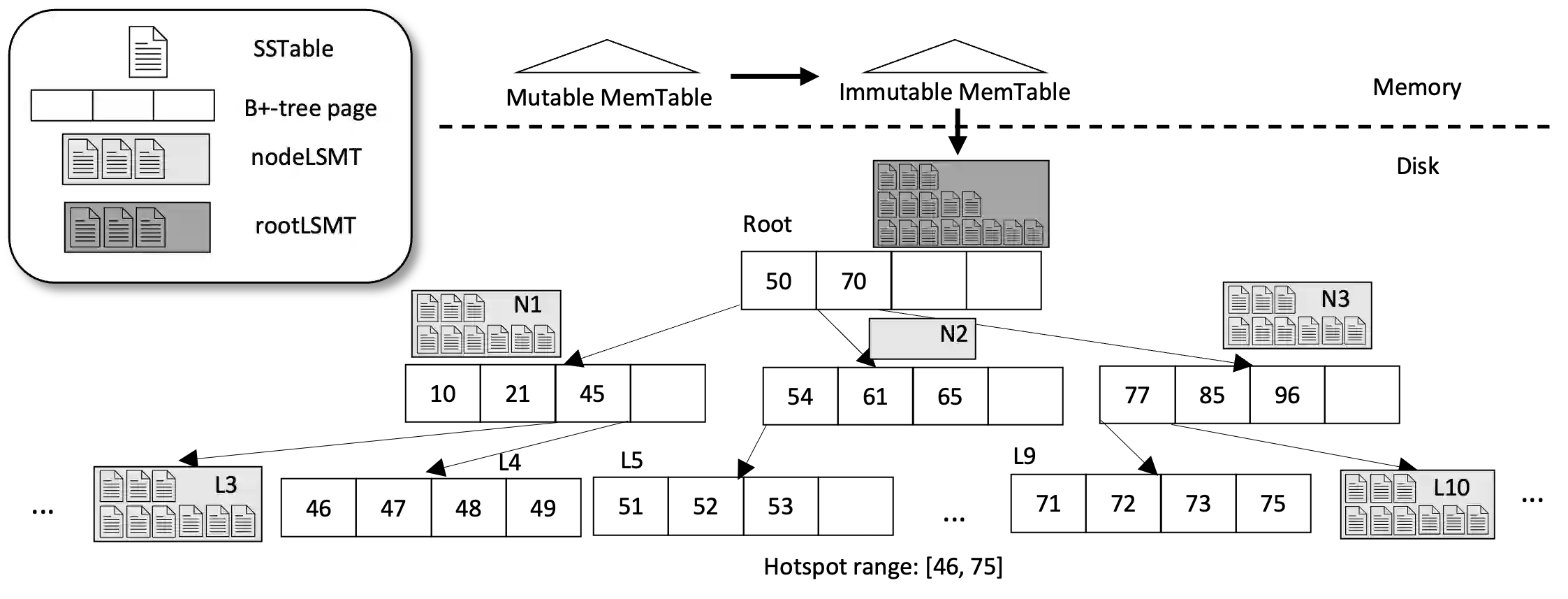
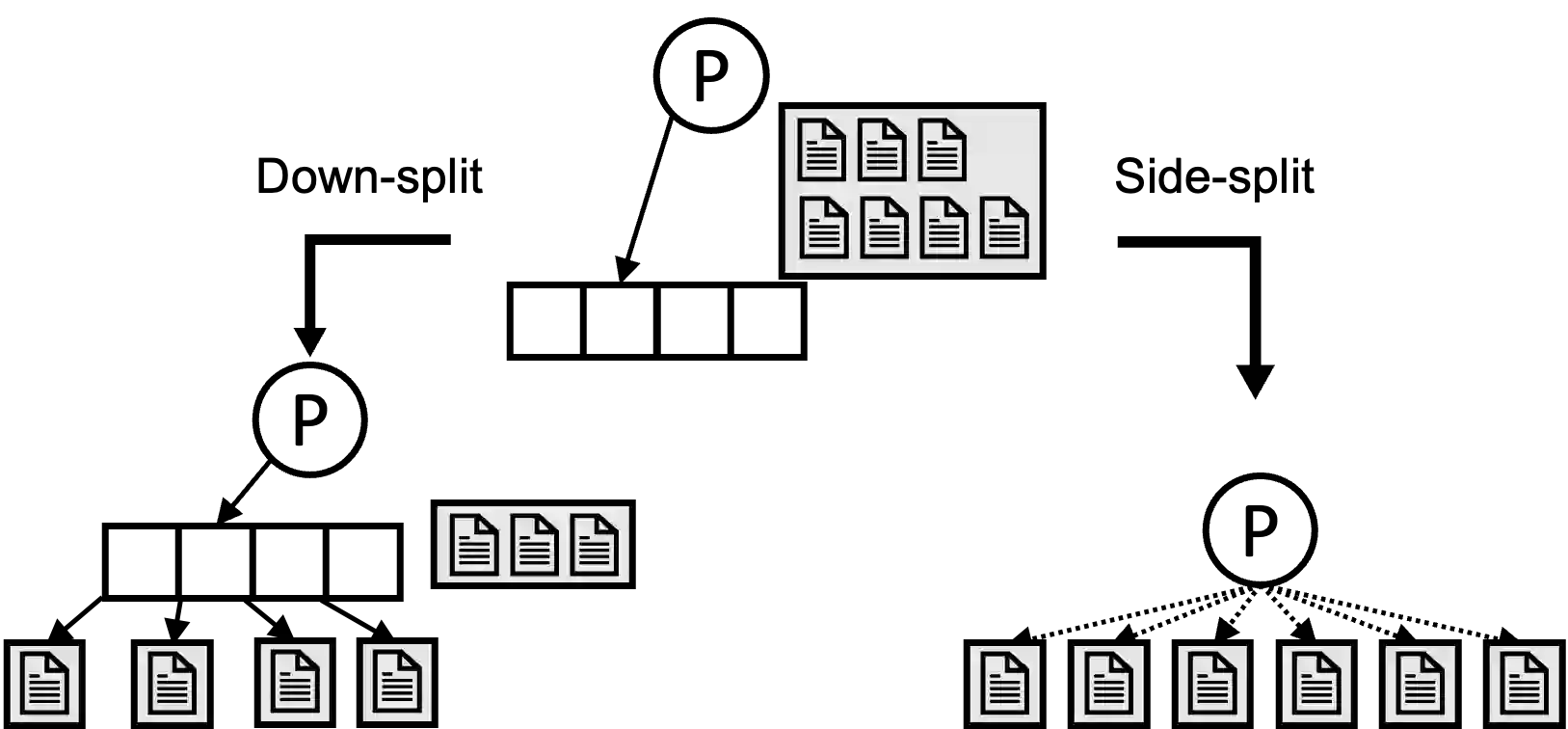
HTAP systems are designed to handle transactional and analytical workloads. Besides a mixed workload at any given time, the workload can also change over time. A popular kind of continuously changing workload is one that oscillates between being write-heavy and being read-heavy. These oscillating workloads can be observed in many applications. Indexes, e.g., the B+-tree and the LSM-Tree cannot perform equally well all the time. Conventional adaptive indexing does not solve this issue either as it focuses on adapting in one direction. This paper investigates how to support oscillating workloads with adaptive indexes that adapt the underlying index structures in both directions. With the observation that real-world datasets are skewed, we focus on optimizing the indexes within the hotspot regions. We encapsulate the adaptation techniques into the Adaptive Hotspot-Aware Tree adaptive index. We compare the indexes and discuss the insights of each adaptation technique. Our investigation highlights the trade-offs of AHA-tree as well as the pros and cons of each design choice. AHA-tree can behave competitively as compared to an LSM-tree for write-heavy transactional workloads. Upon switching to a read-heavy analytical workload, and after some transient adaptation period, AHA-tree can behave as a B+-tree and can match the B+-trees read performance.
翻译:HTAP系统旨在处理事务型和分析型工作负载。除了在任意时刻存在混合工作负载外,工作负载也可能随时间变化。一种常见的持续变化工作负载是在写密集和读密集之间振荡的类型。这类振荡工作负载在许多应用中均可观察到。传统索引(如B+树和LSM树)无法始终保持同等性能。传统自适应索引仅关注单向调整,同样无法解决此问题。本文研究如何通过自适应索引支持振荡工作负载,使底层索引结构能够双向调整。基于现实数据集呈偏斜分布的观察,我们聚焦于优化热点区域内的索引。将自适应技术封装为自适应热点感知树(Adaptive Hotspot-Aware Tree,AHA-tree)自适应索引。我们对各类索引进行比较,并探讨每种自适应技术的设计思路。研究揭示了AHA-tree的权衡特性及各设计方案的优缺点。在写密集事务型工作负载下,AHA-tree可展现出与LSM树相当的竞争力。当切换至读密集分析型工作负载时,经过短暂的自适应过渡期,AHA-tree能够演变为B+树结构,并达到与B+树相当的读取性能。