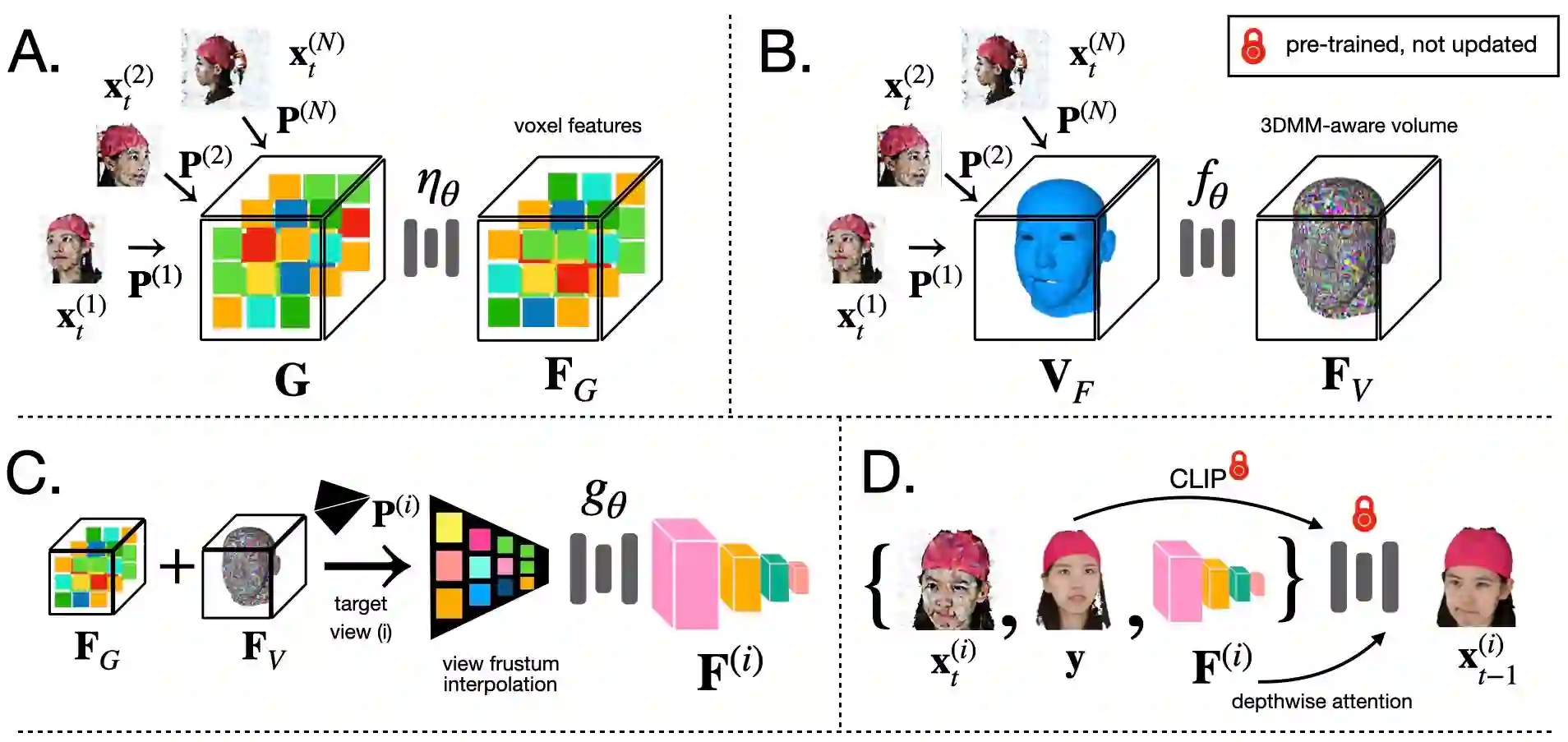
Recent advances in generative diffusion models have enabled the previously unfeasible capability of generating 3D assets from a single input image or a text prompt. In this work, we aim to enhance the quality and functionality of these models for the task of creating controllable, photorealistic human avatars. We achieve this by integrating a 3D morphable model into the state-of-the-art multiview-consistent diffusion approach. We demonstrate that accurate conditioning of a generative pipeline on the articulated 3D model enhances the baseline model performance on the task of novel view synthesis from a single image. More importantly, this integration facilitates a seamless and accurate incorporation of facial expression and body pose control into the generation process. To the best of our knowledge, our proposed framework is the first diffusion model to enable the creation of fully 3D-consistent, animatable, and photorealistic human avatars from a single image of an unseen subject; extensive quantitative and qualitative evaluations demonstrate the advantages of our approach over existing state-of-the-art avatar creation models on both novel view and novel expression synthesis tasks.
翻译:近年来,生成式扩散模型的发展使得从单张输入图像或文本提示生成三维资产的先前不可行能力得以实现。本研究旨在提升此类模型在可控、逼真人类化身创建任务中的质量与功能性。为此,我们将三维可变形模型集成至当前最先进的多视角一致扩散方法中。实验表明,基于铰接式三维模型对生成流水线进行精确条件控制,可提升基线模型在单张图像新视角合成任务上的性能。更重要的是,这种集成实现了面部表情与身体姿态控制的无缝精准嵌入。据我们所知,所提出的框架是首个能够从未知个体单张图像生成完全三维一致、可驱动且逼真的数字化化身的扩散模型;大量定量与定性评估表明,本方法在新视角合成与新颖表情合成任务上均优于现有最先进的虚拟化身生成模型。