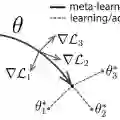
The aim of Few-Shot learning methods is to train models which can easily adapt to previously unseen tasks, based on small amounts of data. One of the most popular and elegant Few-Shot learning approaches is Model-Agnostic Meta-Learning (MAML). The main idea behind this method is to learn the general weights of the meta-model, which are further adapted to specific problems in a small number of gradient steps. However, the model's main limitation lies in the fact that the update procedure is realized by gradient-based optimisation. In consequence, MAML cannot always modify weights to the essential level in one or even a few gradient iterations. On the other hand, using many gradient steps results in a complex and time-consuming optimization procedure, which is hard to train in practice, and may lead to overfitting. In this paper, we propose HyperMAML, a novel generalization of MAML, where the training of the update procedure is also part of the model. Namely, in HyperMAML, instead of updating the weights with gradient descent, we use for this purpose a trainable Hypernetwork. Consequently, in this framework, the model can generate significant updates whose range is not limited to a fixed number of gradient steps. Experiments show that HyperMAML consistently outperforms MAML and performs comparably to other state-of-the-art techniques in a number of standard Few-Shot learning benchmarks.
翻译:小样本学习方法的目标是训练能够基于少量数据轻松适应先前未见任务的模型。模型无关元学习(MAML)是最流行且优雅的小样本学习方法之一。该方法的核心思想是学习元模型的通用权重,这些权重可通过少量梯度步骤进一步适配特定问题。然而,该模型的主要局限在于更新过程通过基于梯度的优化实现。因此,MAML无法始终通过一次甚至数次梯度迭代将权重调整至本质层面。另一方面,使用过多梯度步骤会导致复杂耗时的优化过程,这在实践中难以训练且可能引发过拟合。本文提出HyperMAML——一种新颖的MAML泛化框架,其将更新过程的训练也纳入模型组成部分。具体而言,在HyperMAML中,我们采用可训练的超网络替代梯度下降法进行权重更新。这使得该框架能够生成不受固定梯度步数限制的重要更新。实验表明,在多个标准小样本学习基准测试中,HyperMAML始终优于MAML,并与当前其他先进技术性能相当。