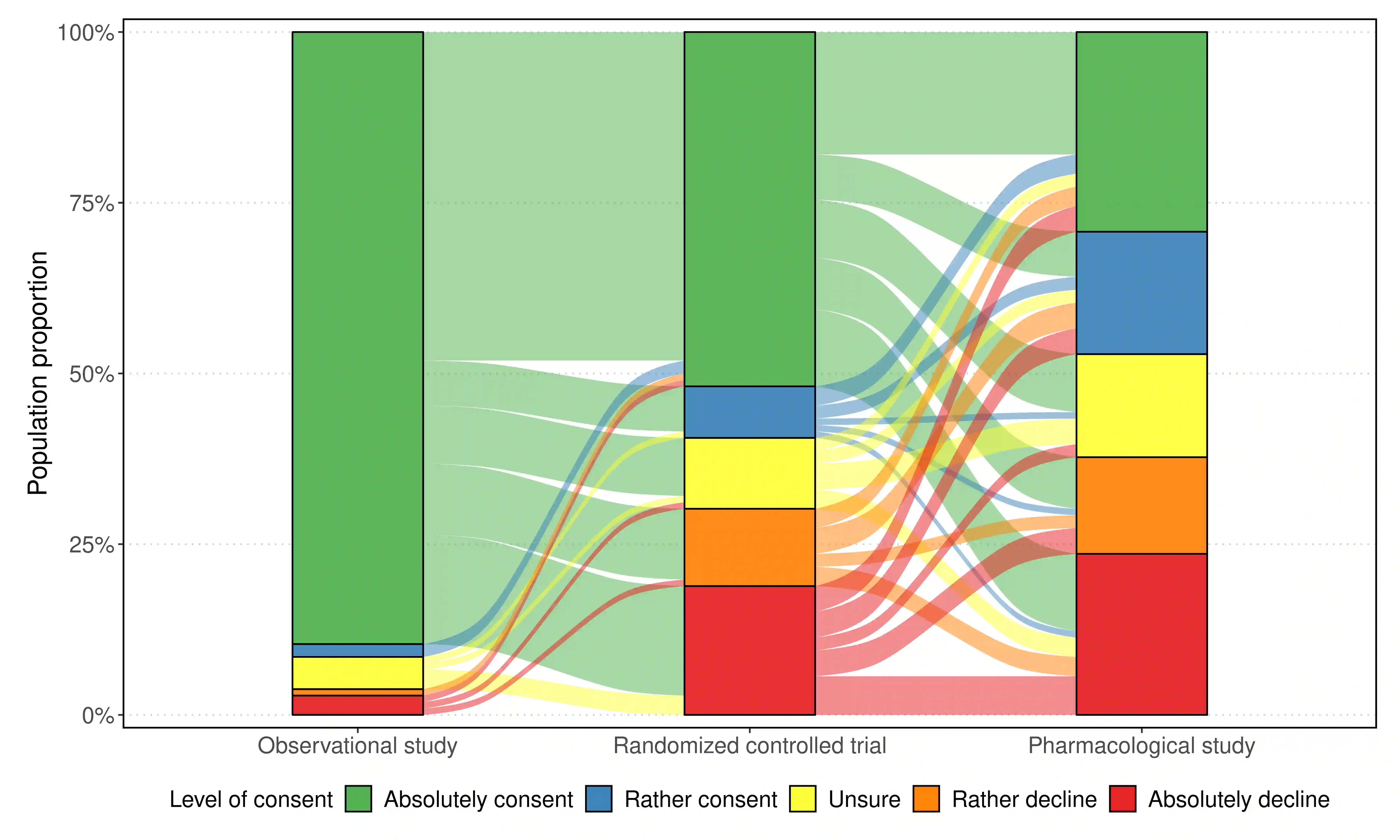
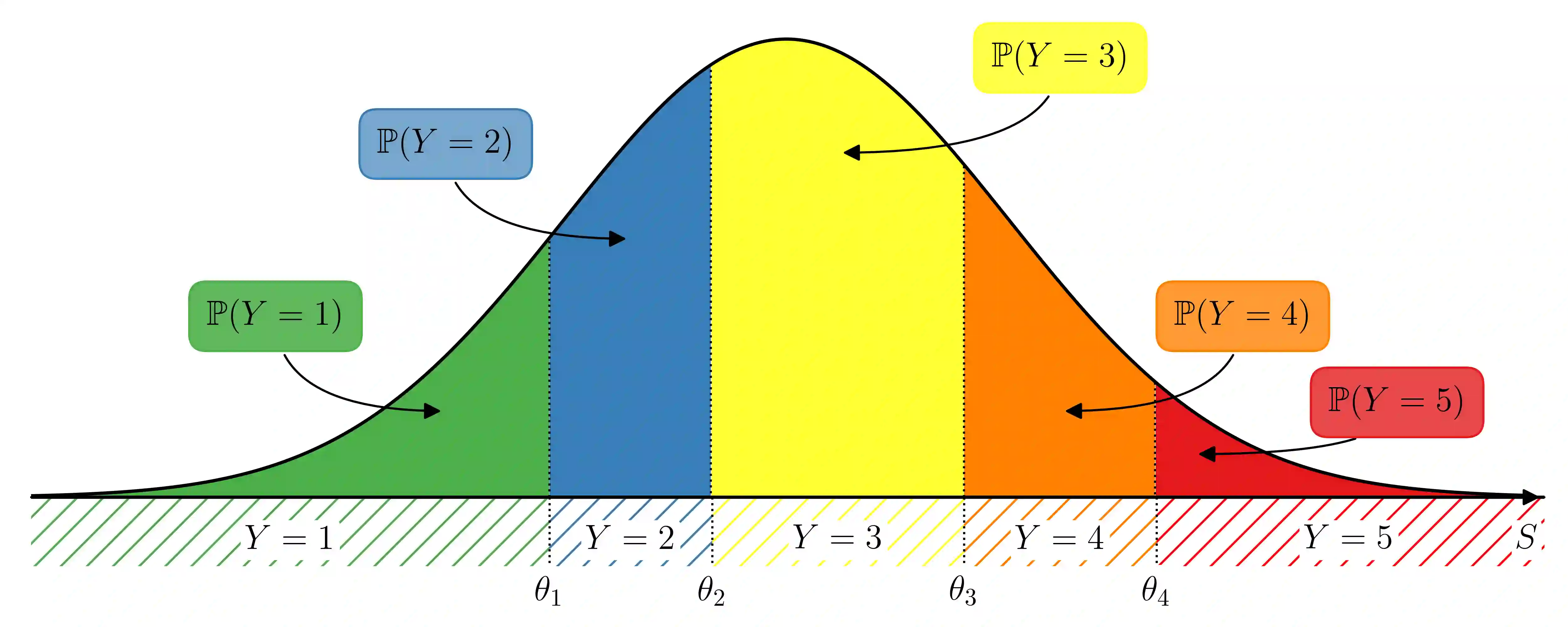
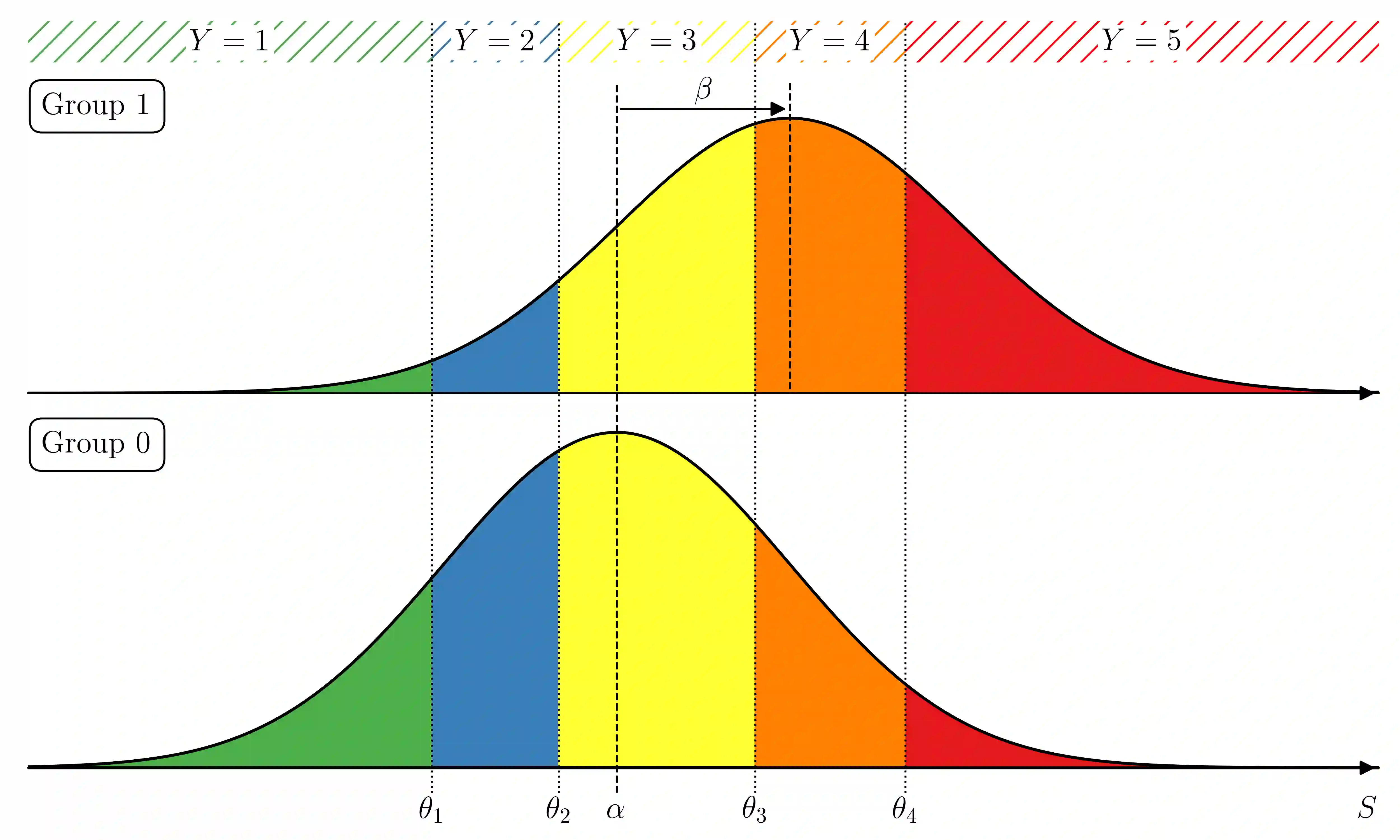
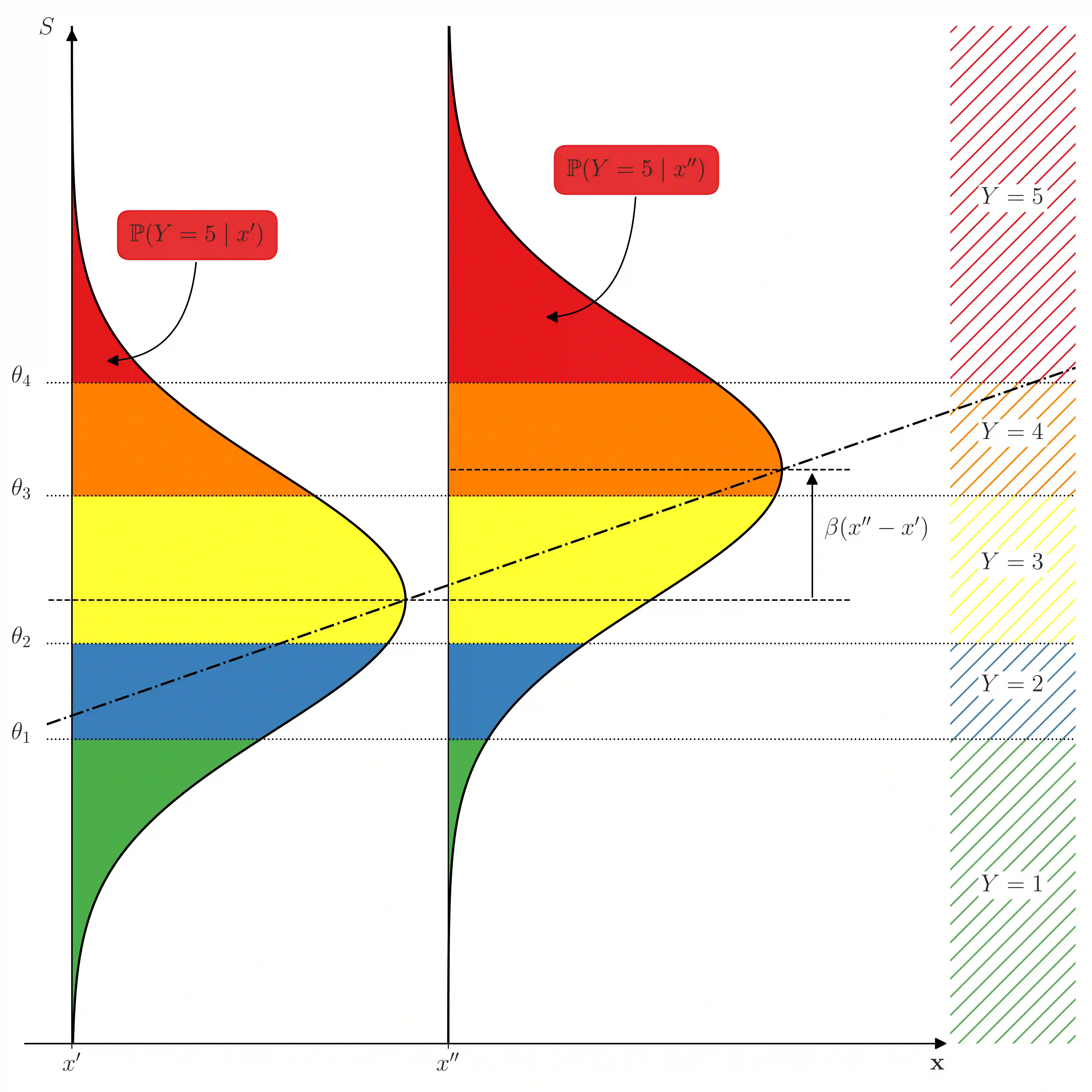
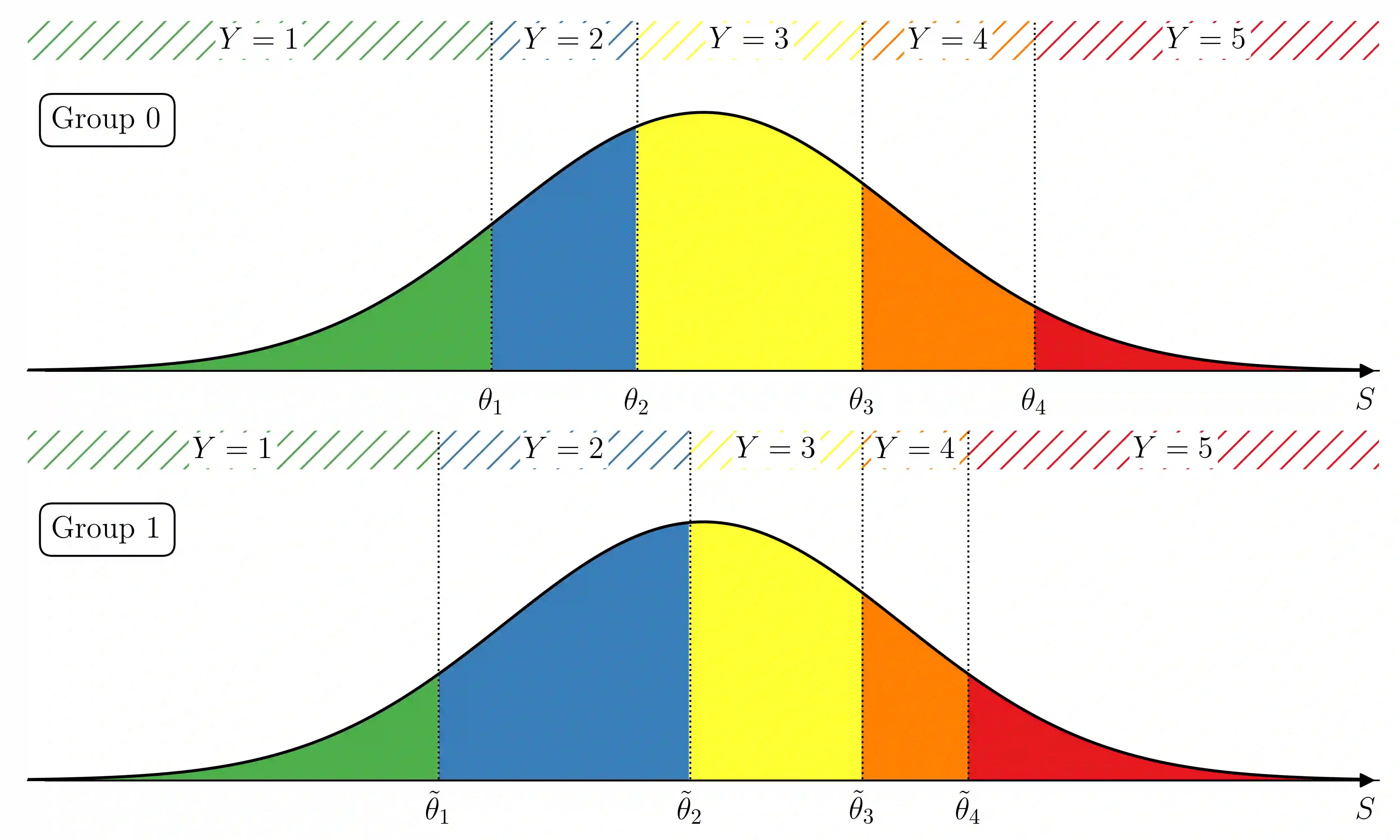
The analysis of survey data is a frequently arising issue in clinical trials, particularly when capturing quantities which are difficult to measure using, e.g., a technical device or a biochemical procedure. Typical examples are questionnaires about patient's well-being, pain, anxiety, quality of life or consent to an intervention. Data is captured on a discrete scale containing only a limited (usually three to ten) number of possible answers, of which the respondent has to pick the answer which fits best his personal opinion to the question. This data is generally located on an ordinal scale as answers can usually be arranged in an increasing order, e.g., "bad", "neutral", "good" for well-being or "none", "mild", "moderate", "severe" for pain. Since responses are often stored numerically for data processing purposes, analysis of survey data using ordinary linear regression (OLR) models seems to be natural. However, OLR assumptions are often not met as linear regression requires a constant variability of the response variable and can yield predictions out of the range of response categories. Moreover, in doing so, one only gains insights about the mean response which might, depending on the response distribution, not be very representative. In contrast, ordinal regression models are able to provide probability estimates for all response categories and thus yield information about the full response scale rather than just the mean. Although these methods are well described in the literature, they seem to be rarely applied to biomedical or survey data. In this paper, we give a concise overview about fundamentals of ordinal models, applications to a real data set, outline usage of state-of-the-art-software to do so and point out strengths, limitations and typical pitfalls. This article is a companion work to a current vignette-based structured interview study in paediatric anaesthesia.
翻译:调查数据的分析在临床试验中是一个常见问题,尤其是在捕捉难以通过技术设备或生化程序测量的指标时。典型例子包括关于患者幸福感、疼痛、焦虑、生活质量或干预同意的问卷调查。数据在包含有限数量(通常三到十个)可能答案的离散尺度上收集,受访者需从中选择最符合个人意见的答案。这些数据通常位于序数量表上,因为答案可按递增顺序排列,例如幸福感中的“差”、“中性”、“好”,或疼痛中的“无”、“轻度”、“中度”、“重度”。由于为便于数据处理,答案常以数字形式存储,因此使用普通线性回归模型分析调查数据似乎是自然的选择。然而,普通线性回归的假设通常无法满足,因为线性回归要求响应变量具有恒定的变异性,且可能产生超出响应类别范围的预测。此外,这样做仅能获得关于平均响应的洞察,而根据响应分布的不同,这一平均可能并不具有很好的代表性。相比之下,序数回归模型能够为所有响应类别提供概率估计,从而提供关于整个响应尺度的信息,而不仅仅是平均值。尽管这些方法在文献中已有详细描述,但它们在实际中似乎很少应用于生物医学或调查数据。本文简明概述了序数模型的基本原理、在真实数据集上的应用,阐述了使用最新软件的方法,并指出了其优势、局限性和常见陷阱。本文是当前一项基于小插图的儿科麻醉结构化访谈研究的配套工作。