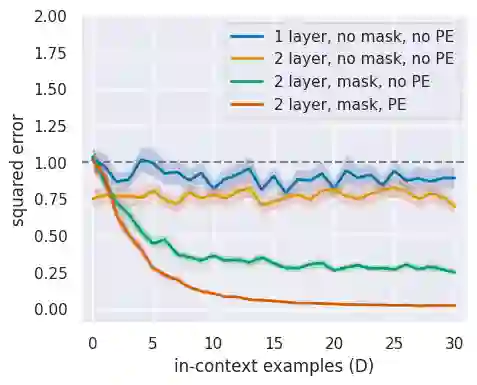
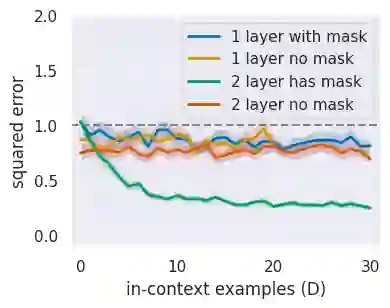
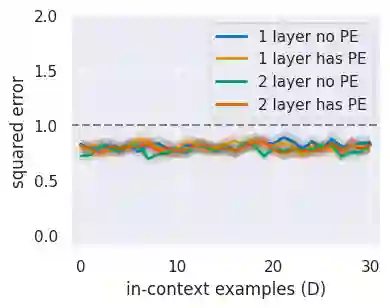
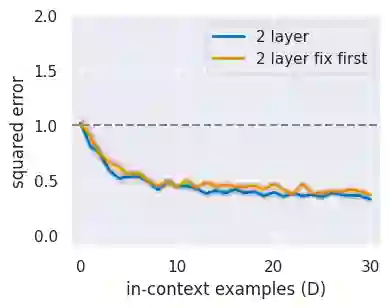
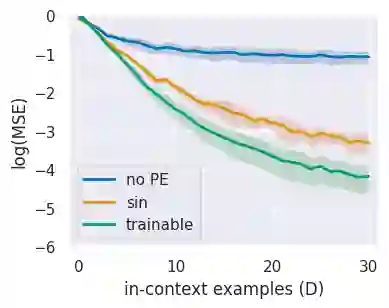
In practice, it is observed that transformer-based models can learn concepts in context in the inference stage. While existing literature, e.g., \citet{zhang2023trained,huang2023context}, provide theoretical explanations on this in-context learning ability, they assume the input $x_i$ and the output $y_i$ for each sample are embedded in the same token (i.e., structured data). However, in reality, they are presented in two tokens (i.e., unstructured data \cite{wibisono2023role}). In this case, this paper conducts experiments in linear regression tasks to study the benefits of the architecture of transformers and provides some corresponding theoretical intuitions to explain why the transformer can learn from unstructured data. We study the exact components in a transformer that facilitate the in-context learning. In particular, we observe that (1) a transformer with two layers of softmax (self-)attentions with look-ahead attention mask can learn from the prompt if $y_i$ is in the token next to $x_i$ for each example; (2) positional encoding can further improve the performance; and (3) multi-head attention with a high input embedding dimension has a better prediction performance than single-head attention.
翻译:在实践中观察到,基于Transformer的模型可以在推理阶段通过上下文学习概念。尽管现有文献(如\citet{zhang2023trained,huang2023context})对此上下文学习能力提供了理论解释,但它们假设每个样本的输入$x_i$和输出$y_i$嵌入在同一词元(即结构化数据)中。然而实际场景中,两者通常以两个词元呈现(即非结构化数据\cite{wibisono2023role})。为此,本文在线性回归任务中开展实验,研究Transformer架构的优势,并提供相应理论直觉解释为何Transformer能从非结构化数据中学习。我们探究了Transformer中促进上下文学习的具体组件。特别观察到:(1)具有前瞻注意力掩码的双层softmax(自)注意力机制的Transformer,能够在每个样本的$y_i$位于$x_i$相邻词元时从提示中学习;(2)位置编码可进一步提升性能;(3)高输入嵌入维度的多头注意力比单头注意力具有更优的预测性能。