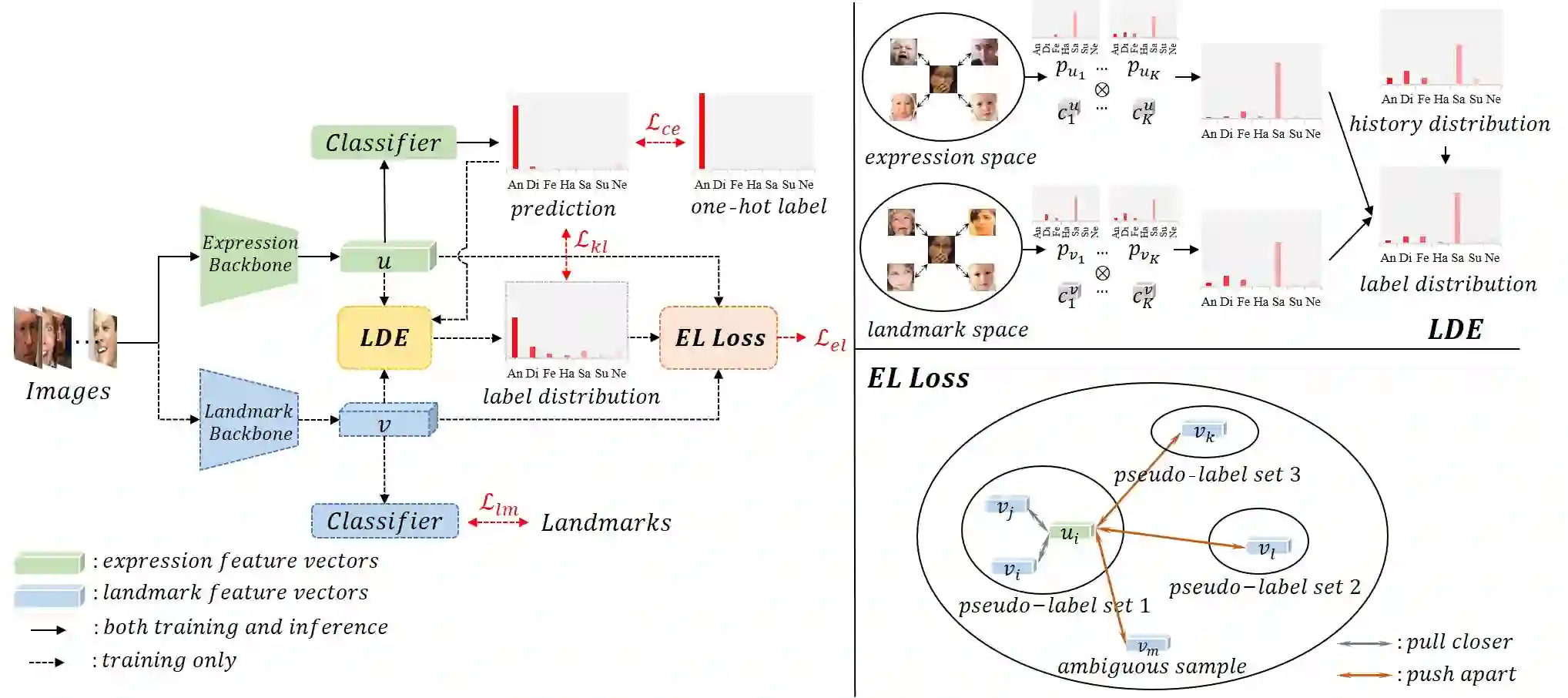
Facial expression recognition (FER) remains a challenging task due to the ambiguity of expressions. The derived noisy labels significantly harm the performance in real-world scenarios. To address this issue, we present a new FER model named Landmark-Aware Net~(LA-Net), which leverages facial landmarks to mitigate the impact of label noise from two perspectives. Firstly, LA-Net uses landmark information to suppress the uncertainty in expression space and constructs the label distribution of each sample by neighborhood aggregation, which in turn improves the quality of training supervision. Secondly, the model incorporates landmark information into expression representations using the devised expression-landmark contrastive loss. The enhanced expression feature extractor can be less susceptible to label noise. Our method can be integrated with any deep neural network for better training supervision without introducing extra inference costs. We conduct extensive experiments on both in-the-wild datasets and synthetic noisy datasets and demonstrate that LA-Net achieves state-of-the-art performance.
翻译:面部表情识别(FER)因表情的模糊性而仍具挑战性。在现实场景中,由此产生的噪声标签会严重损害模型性能。为解决该问题,我们提出一种名为地标感知网络(LA-Net)的新型FER模型,该模型从两个角度利用面部地标来缓解标签噪声的影响。首先,LA-Net利用地标信息抑制表情空间中的不确定性,并通过邻域聚合构建每个样本的标签分布,进而提升训练监督的质量。其次,模型通过设计的面部表情-地标对比损失函数,将地标信息融入表情表征中。增强后的表情特征提取器能降低对标签噪声的敏感度。我们的方法可集成至任意深度神经网络中,在不引入额外推理成本的前提下实现更优的训练监督。我们在自然场景数据集与合成噪声数据集上进行了广泛实验,结果表明LA-Net达到了最先进的性能水平。