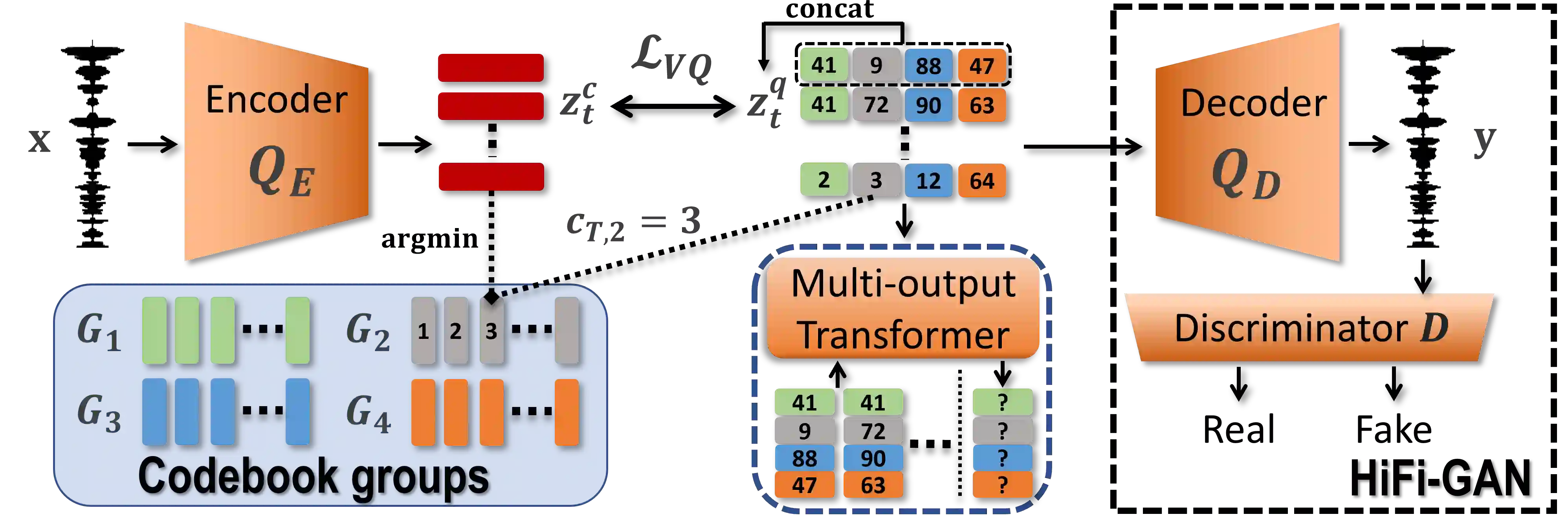
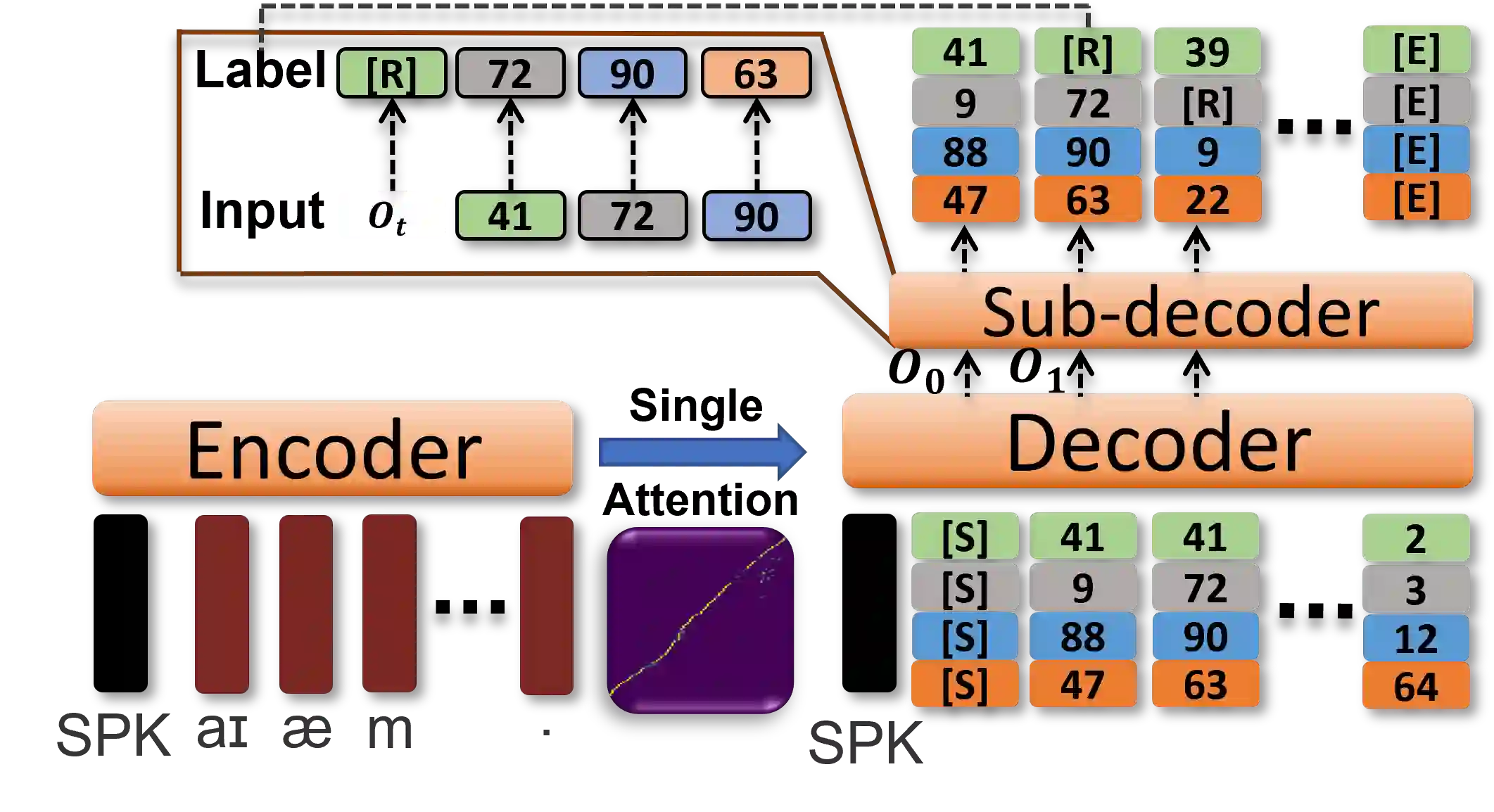
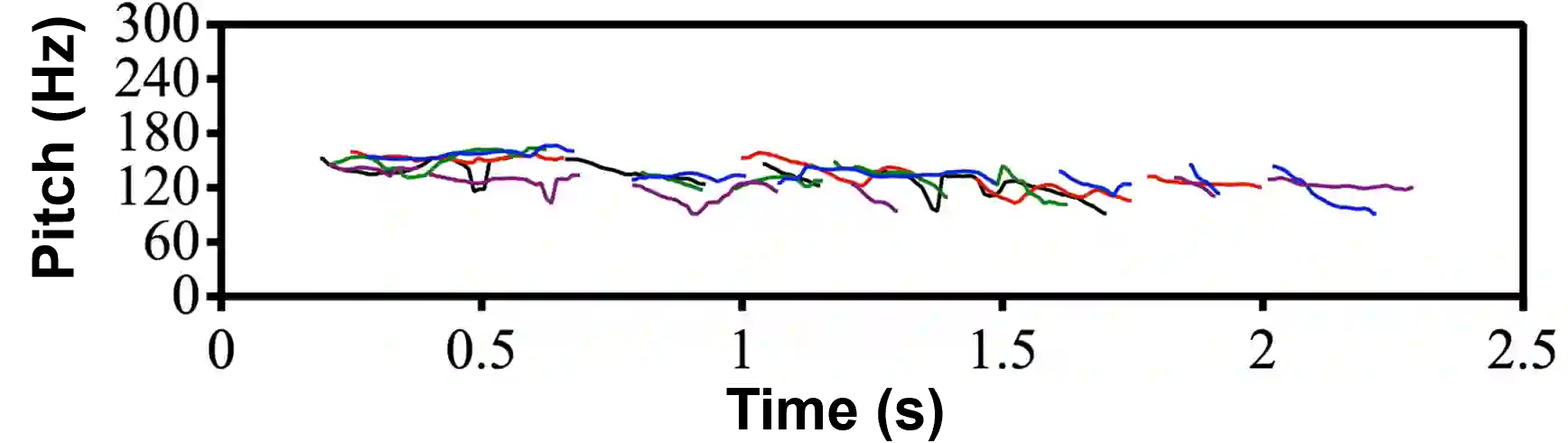
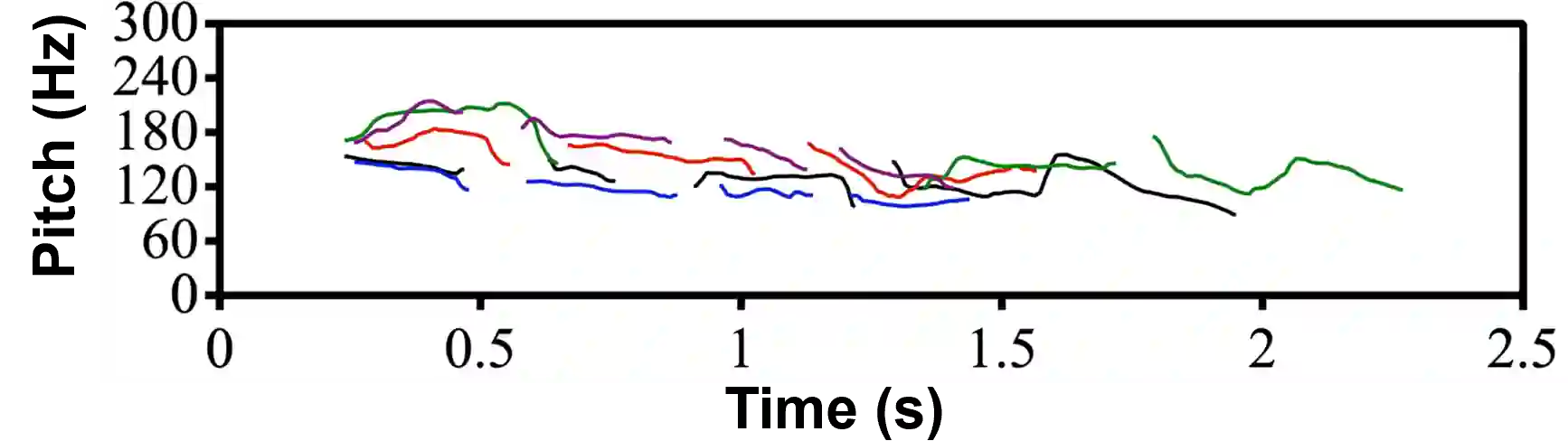
Recent Text-to-Speech (TTS) systems trained on reading or acted corpora have achieved near human-level naturalness. The diversity of human speech, however, often goes beyond the coverage of these corpora. We believe the ability to handle such diversity is crucial for AI systems to achieve human-level communication. Our work explores the use of more abundant real-world data for building speech synthesizers. We train TTS systems using real-world speech from YouTube and podcasts. We observe the mismatch between training and inference alignments in mel-spectrogram based autoregressive models, leading to unintelligible synthesis, and demonstrate that learned discrete codes within multiple code groups effectively resolves this issue. We introduce our MQTTS system whose architecture is designed for multiple code generation and monotonic alignment, along with the use of a clean silence prompt to improve synthesis quality. We conduct ablation analyses to identify the efficacy of our methods. We show that MQTTS outperforms existing TTS systems in several objective and subjective measures.
翻译:近期,基于朗读或表演语料库训练的文本到语音(TTS)系统已接近人类水平的自然度。然而,人类语音的多样性往往超出了这些语料库的覆盖范围。我们认为,处理这种多样性的能力对于人工智能系统实现人类水平的交流至关重要。本研究探索利用更丰富的真实世界数据构建语音合成器。我们使用来自YouTube和播客的真实世界语音训练TTS系统。在基于梅尔频谱的自回归模型中,我们观察到训练与推理对齐之间的失配现象,这导致合成语音不可理解,并证明多码组内的学习离散码能有效解决该问题。我们提出的MQTTS系统架构专为多码生成与单调对齐设计,同时采用静音提示来提升合成质量。通过消融实验验证了各方法的效果,并在多项客观与主观指标上证明MQTTS优于现有TTS系统。