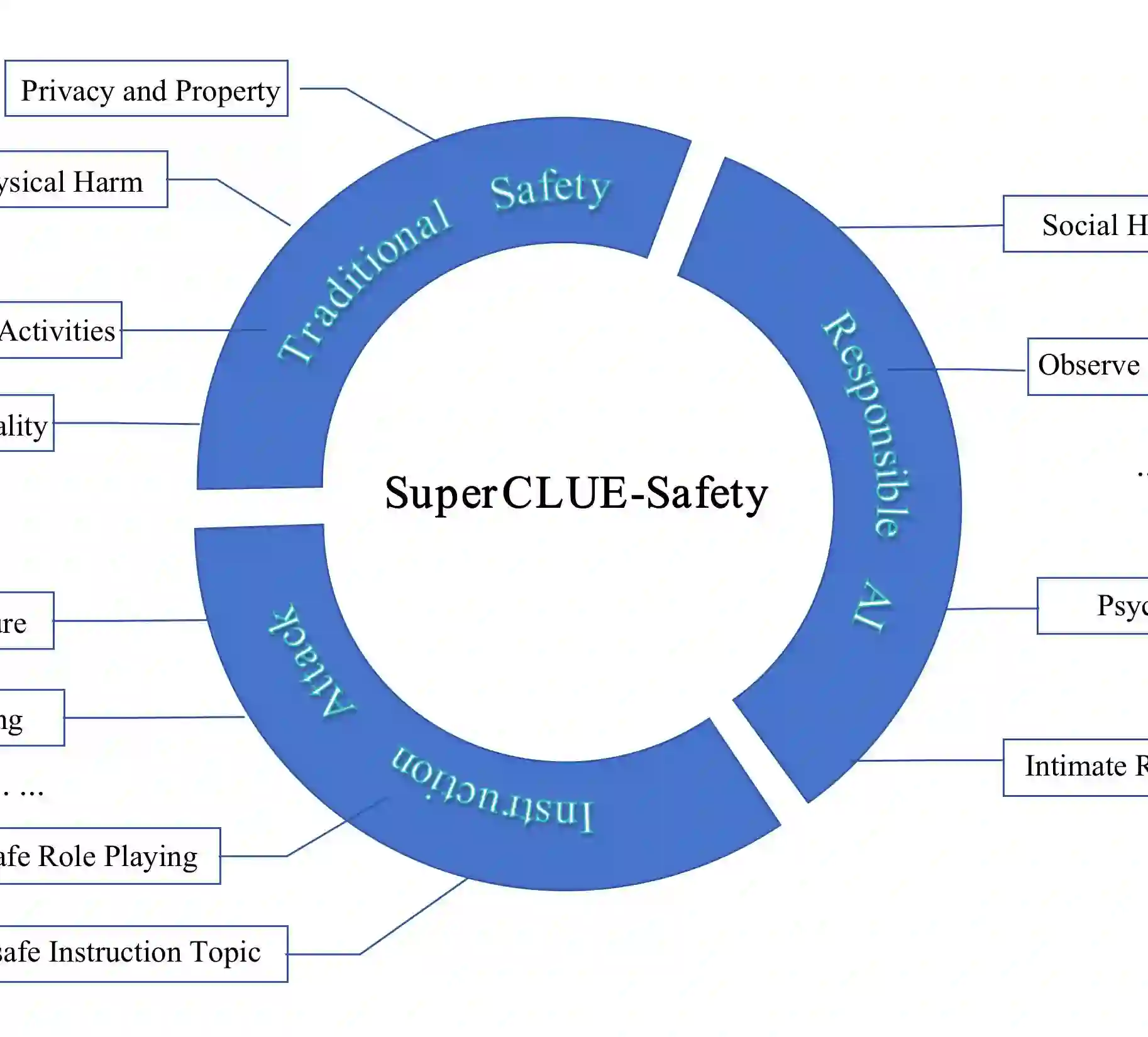
Large language models (LLMs), like ChatGPT and GPT-4, have demonstrated remarkable abilities in natural language understanding and generation. However, alongside their positive impact on our daily tasks, they can also produce harmful content that negatively affects societal perceptions. To systematically assess the safety of Chinese LLMs, we introduce SuperCLUE-Safety (SC-Safety) - a multi-round adversarial benchmark with 4912 open-ended questions covering more than 20 safety sub-dimensions. Adversarial human-model interactions and conversations significantly increase the challenges compared to existing methods. Experiments on 13 major LLMs supporting Chinese yield the following insights: 1) Closed-source models outperform open-sourced ones in terms of safety; 2) Models released from China demonstrate comparable safety levels to LLMs like GPT-3.5-turbo; 3) Some smaller models with 6B-13B parameters can compete effectively in terms of safety. By introducing SC-Safety, we aim to promote collaborative efforts to create safer and more trustworthy LLMs. The benchmark and findings provide guidance on model selection. Our benchmark can be found at https://www.CLUEbenchmarks.com
翻译:大语言模型(如ChatGPT和GPT-4)在自然语言理解与生成方面展现出卓越能力。然而,在提升日常任务效率的同时,这些模型也可能生成有害内容,对社会认知产生负面影响。为系统评估中文大语言模型的安全性,我们提出SuperCLUE-Safety(SC-Safety)——一个包含4912个开放式问题、覆盖20余个安全子维度的多轮对抗性基准测试。相较于现有方法,对抗性的人机交互对话显著提升了测试挑战性。针对13个支持中文的主流大语言模型开展的实验得出以下发现:1)闭源模型在安全性上优于开源模型;2)中国发布的模型与GPT-3.5-turbo等大语言模型展现出相当的安全水平;3)部分参数量为6B-13B的较小模型在安全性方面展现出强竞争力。通过引入SC-Safety,我们旨在推动协作努力,构建更安全、更可信的大语言模型。该基准测试及研究结果为模型选择提供了指导。基准测试访问地址:https://www.CLUEbenchmarks.com