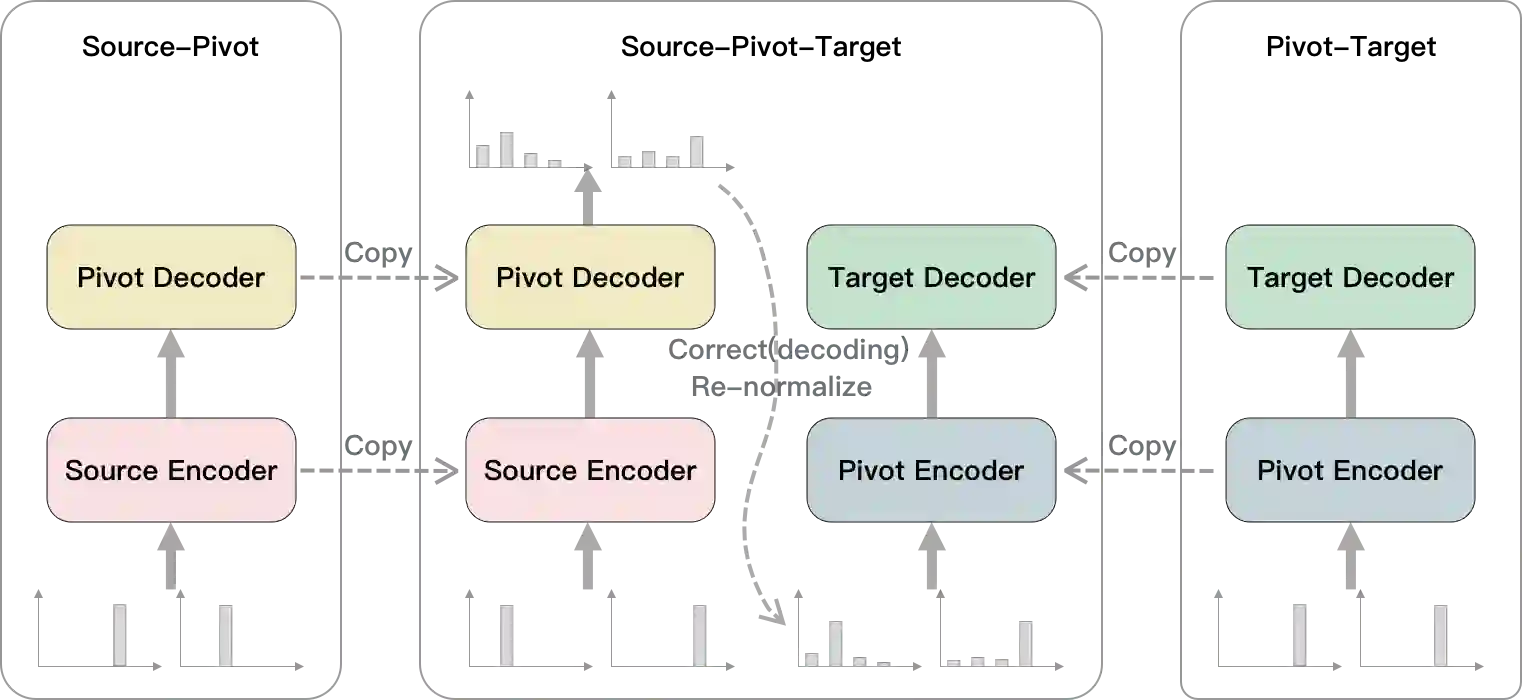
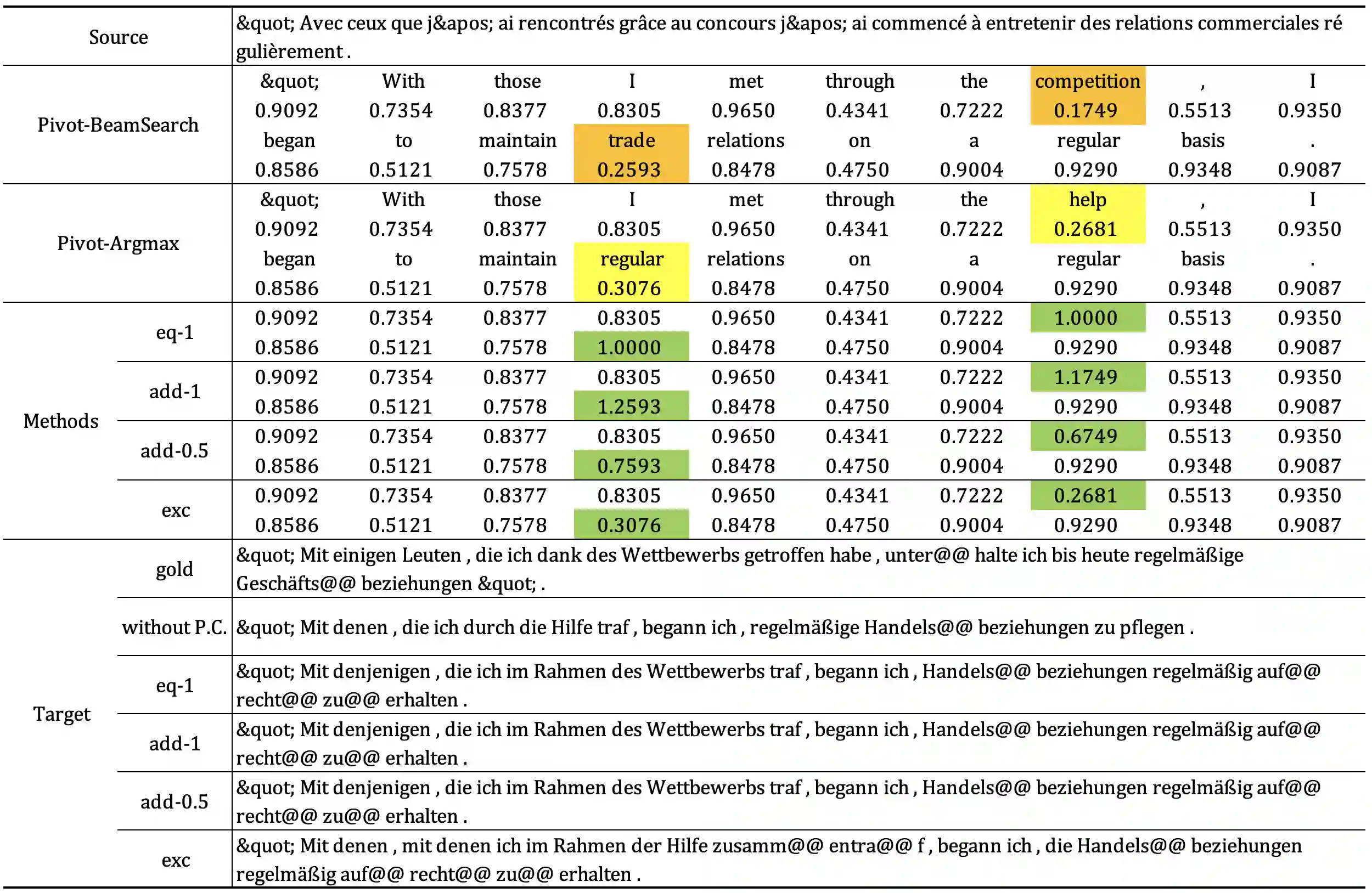
Utilizing pivot language effectively can significantly improve low-resource machine translation. Usually, the two translation models, source-pivot and pivot-target, are trained individually and do not utilize the limited (source, target) parallel data. This work proposes an end-to-end training method for the cascaded translation model and configures an improved decoding algorithm. The input of the pivot-target model is modified to weighted pivot embedding based on the probability distribution output by the source-pivot model. This allows the model to be trained end-to-end. In addition, we mitigate the inconsistency between tokens and probability distributions while using beam search in pivot decoding. Experiments demonstrate that our method enhances the quality of translation.
翻译:有效利用枢轴语言能够显著提升低资源机器翻译的性能。通常,源语言-枢轴语言与枢轴语言-目标语言这两个翻译模型是分别训练的,未能充分利用有限的(源语言,目标语言)平行数据。本文提出了一种针对级联翻译模型的端到端训练方法,并配置了改进的解码算法。我们将枢轴-目标模型的输入修改为基于源-枢轴模型输出的概率分布加权后的枢轴嵌入表示,从而实现了模型的端到端训练。此外,我们缓解了在枢轴解码中使用波束搜索时,词元与概率分布之间的不一致性问题。实验结果表明,我们的方法提升了翻译质量。