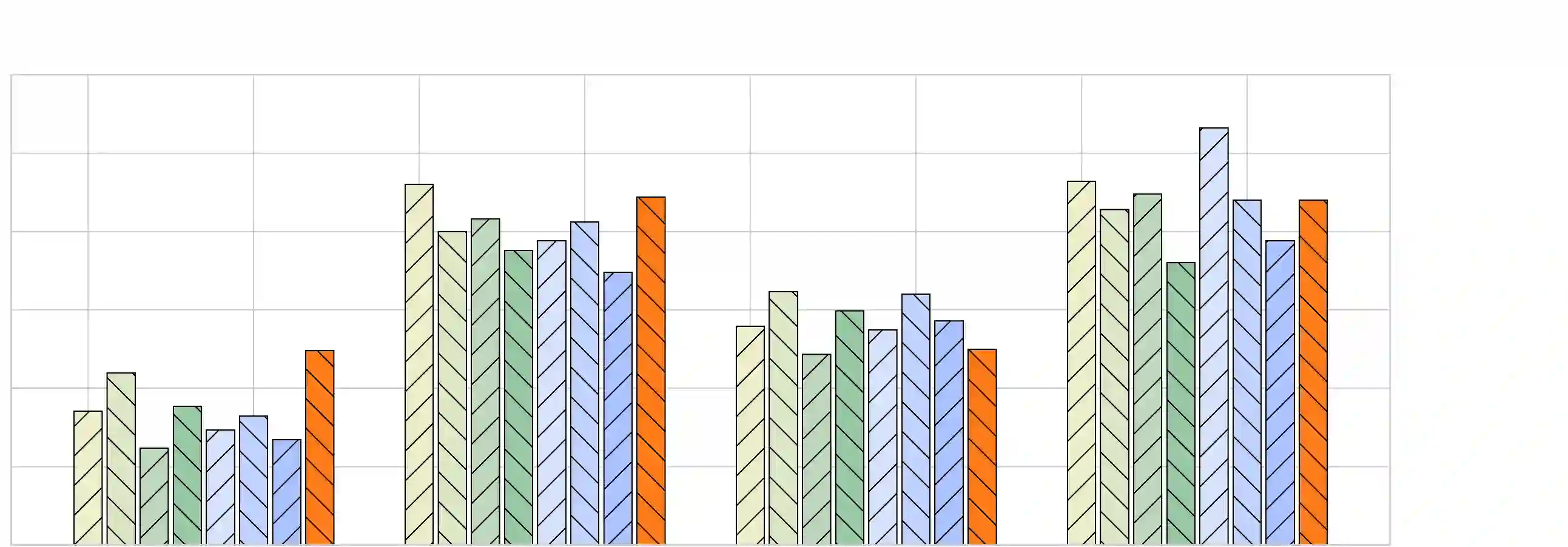
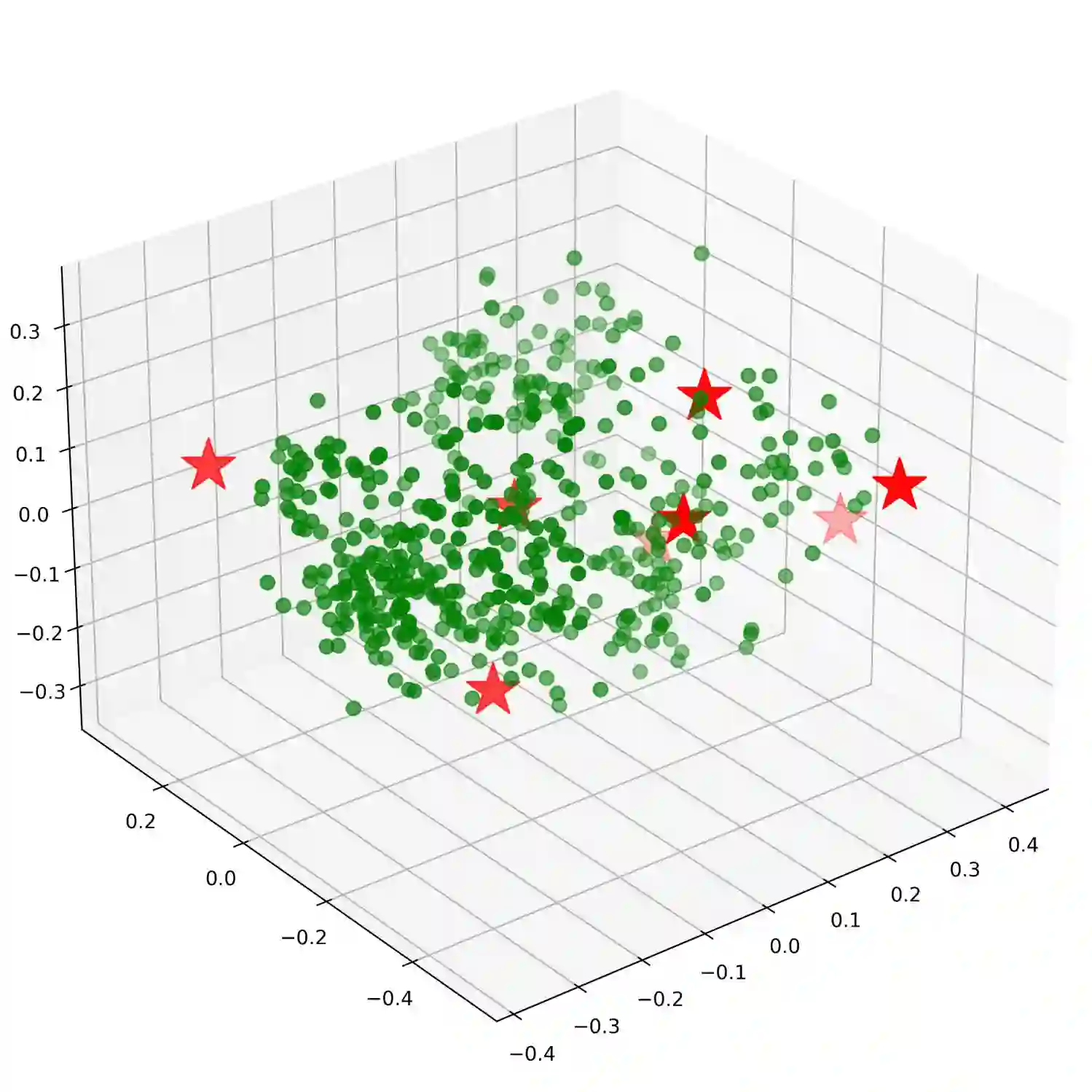
Prompt engineering is an essential technique for enhancing the abilities of large language models (LLMs) by providing explicit and specific instructions. It enables LLMs to excel in various tasks, such as arithmetic reasoning, question answering, summarization, relation extraction, machine translation, and sentiment analysis. Researchers have been actively exploring different prompt engineering strategies, such as Chain of Thought (CoT), Zero-CoT, and In-context learning. However, an unresolved problem arises from the fact that current approaches lack a solid theoretical foundation for determining optimal prompts. To address this issue in prompt engineering, we propose a new and effective approach called Prompt Space. Our methodology utilizes text embeddings to obtain basis vectors by matrix decomposition, and then constructs a space for representing all prompts. Prompt Space significantly outperforms state-of-the-art prompt paradigms on ten public reasoning benchmarks. Notably, without the help of the CoT method and the prompt "Let's think step by step", Prompt Space shows superior performance over the few-shot method. Overall, our approach provides a robust and fundamental theoretical framework for selecting simple and effective prompts. This advancement marks a significant step towards improving prompt engineering for a wide variety of applications in LLMs.
翻译:提示工程是通过提供明确且具体的指令来增强大型语言模型能力的关键技术。它使LLM在算术推理、问答、摘要生成、关系抽取、机器翻译和情感分析等各类任务中表现出色。研究者们积极探索了多种提示工程策略,如思维链、零样本思维链和上下文学习。然而,当前方法缺乏确定最优提示的坚实理论基础这一未解问题仍然存在。为解决这一提示工程中的核心难题,我们提出了一种名为"提示空间"的新颖有效方法。该方法利用文本嵌入通过矩阵分解获得基向量,进而构建表征所有提示的空间。在十个公开推理基准上,Prompt Space显著优于最先进的提示范式。值得注意的是,在无需思维链方法和"让我们逐步思考"提示辅助的情况下,Prompt Space展现出比少样本方法更优越的性能。总体而言,我们的方法为选择简洁有效的提示提供了稳健且基础性的理论框架。这一进展标志着推动LLM各类应用中的提示工程迈出了重要一步。