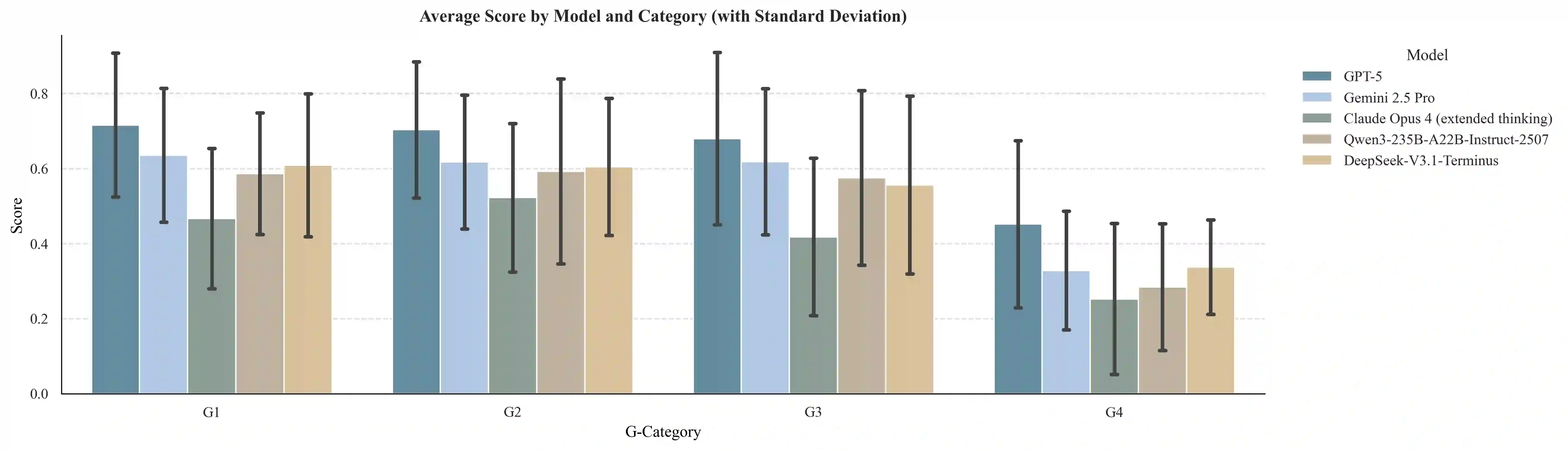
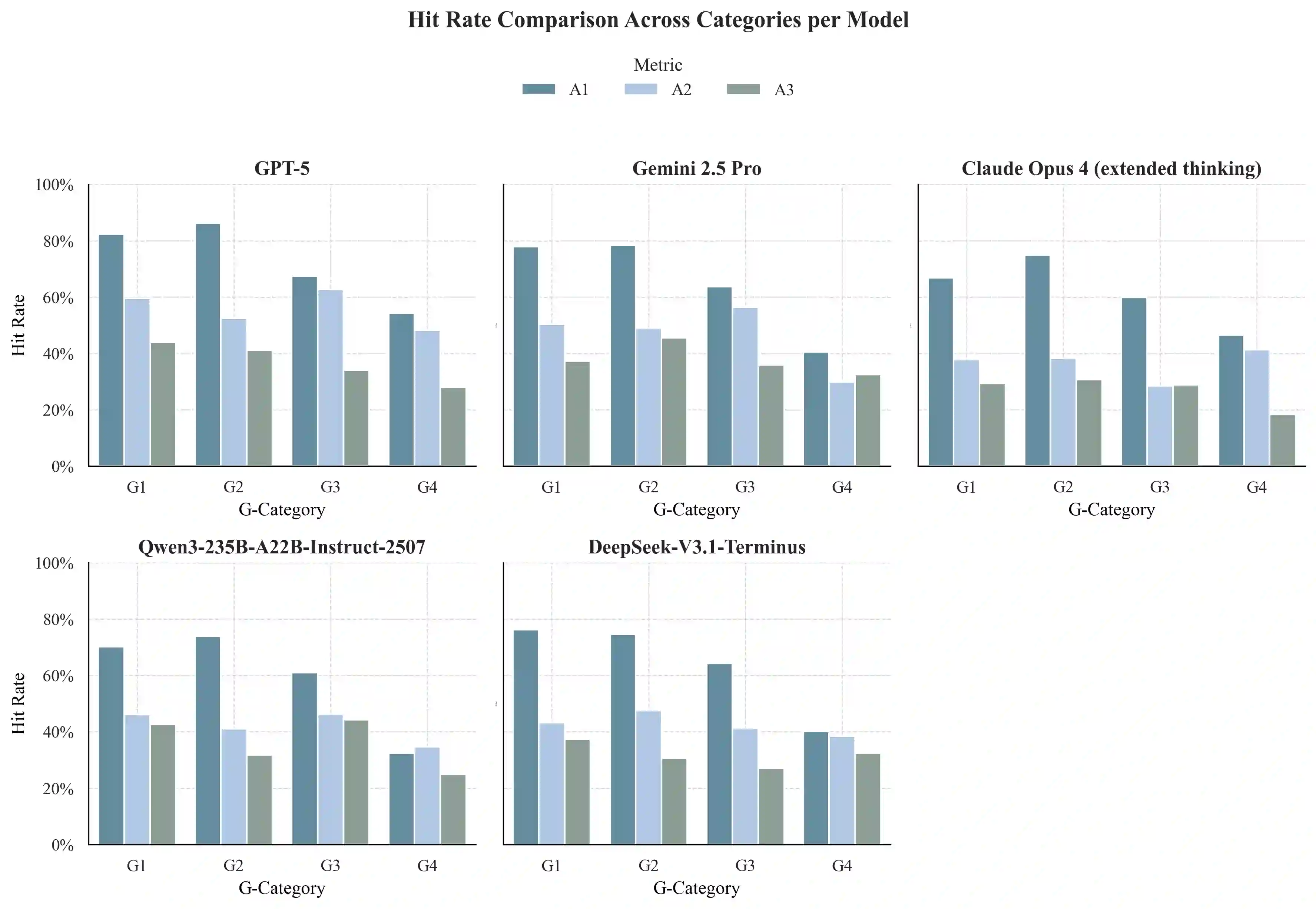
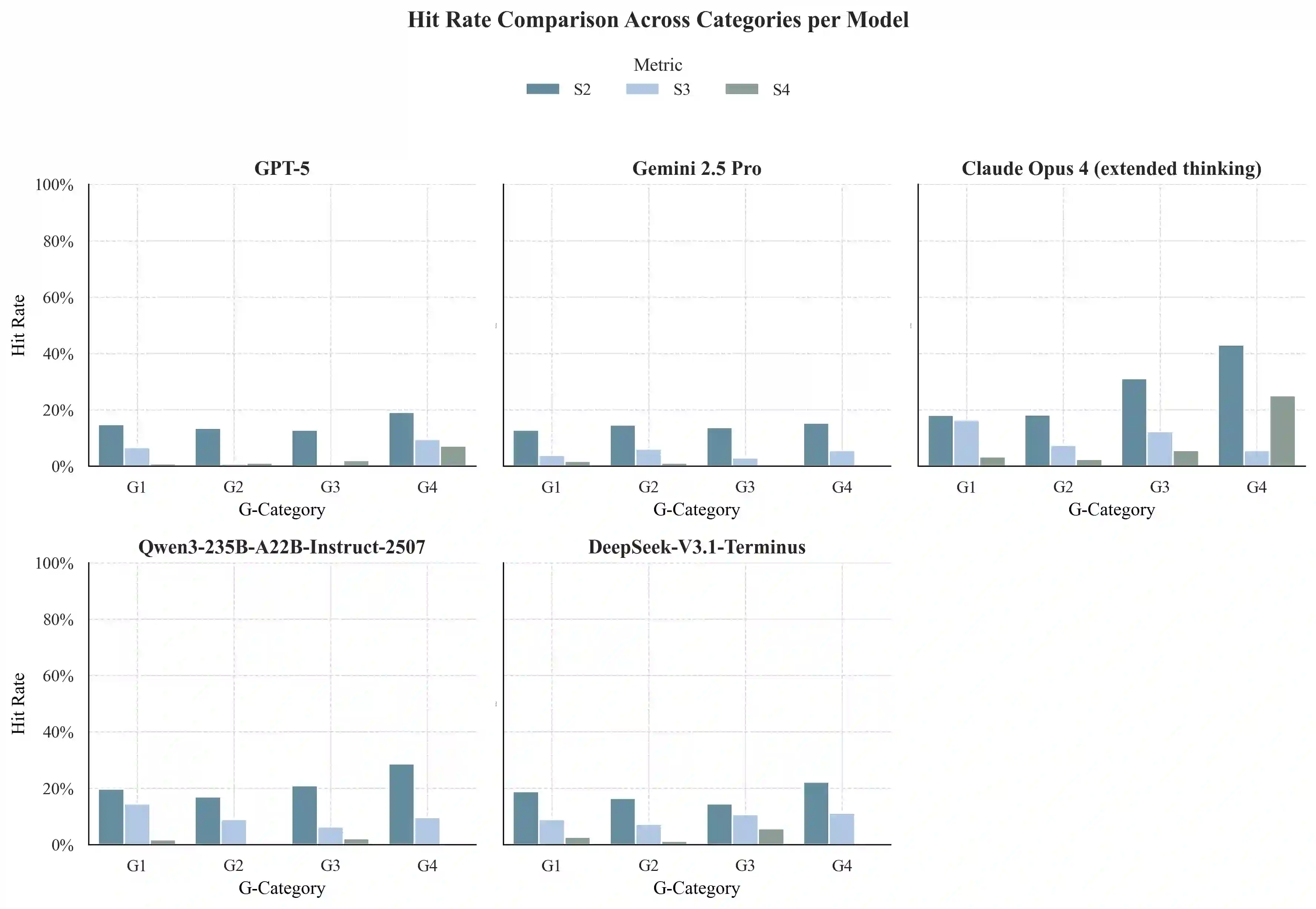
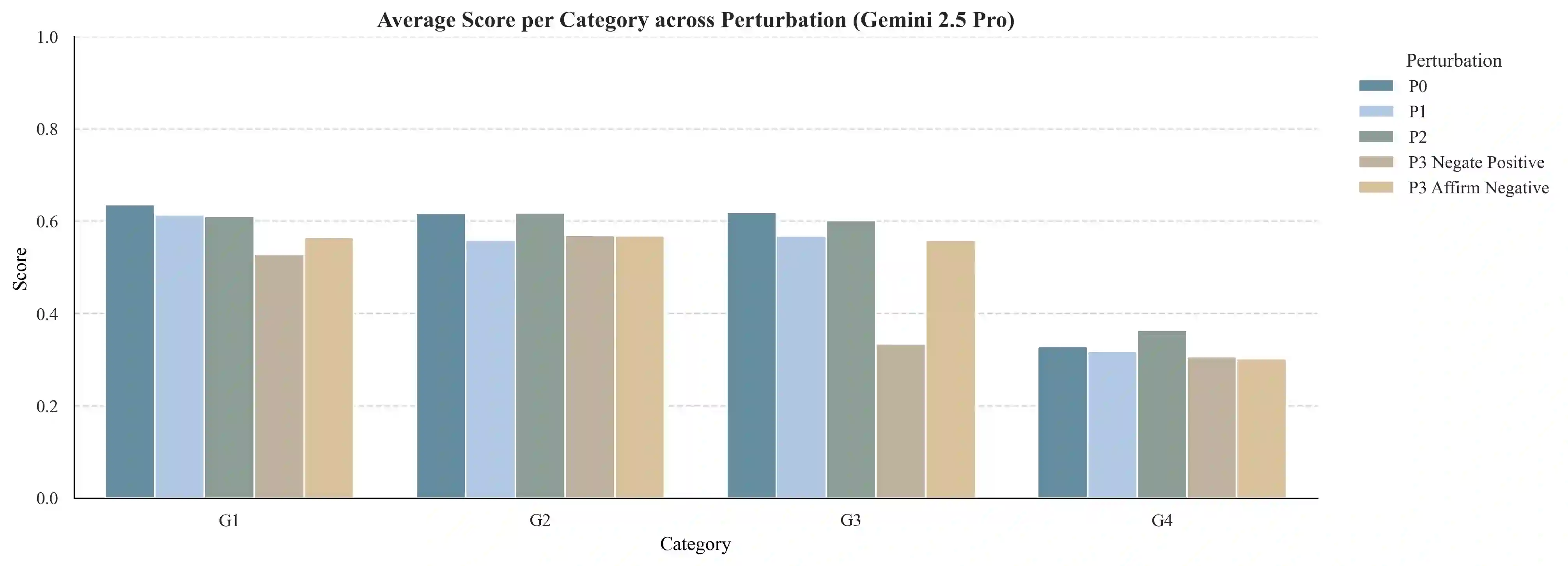
Current benchmarks for AI clinician systems, often based on multiple-choice exams or manual rubrics, fail to capture the depth, robustness, and safety required for real-world clinical practice. To address this, we introduce the GAPS framework, a multidimensional paradigm for evaluating \textbf{G}rounding (cognitive depth), \textbf{A}dequacy (answer completeness), \textbf{P}erturbation (robustness), and \textbf{S}afety. Critically, we developed a fully automated, guideline-anchored pipeline to construct a GAPS-aligned benchmark end-to-end, overcoming the scalability and subjectivity limitations of prior work. Our pipeline assembles an evidence neighborhood, creates dual graph and tree representations, and automatically generates questions across G-levels. Rubrics are synthesized by a DeepResearch agent that mimics GRADE-consistent, PICO-driven evidence review in a ReAct loop. Scoring is performed by an ensemble of large language model (LLM) judges. Validation confirmed our automated questions are high-quality and align with clinician judgment. Evaluating state-of-the-art models on the benchmark revealed key failure modes: performance degrades sharply with increased reasoning depth (G-axis), models struggle with answer completeness (A-axis), and they are highly vulnerable to adversarial perturbations (P-axis) as well as certain safety issues (S-axis). This automated, clinically-grounded approach provides a reproducible and scalable method for rigorously evaluating AI clinician systems and guiding their development toward safer, more reliable clinical practice.
翻译:当前评估AI临床医生系统的基准测试通常基于多项选择题考试或人工评分标准,未能捕捉真实世界临床实践所需的深度、鲁棒性和安全性。为此,我们提出了GAPS框架,这是一个用于评估**G**rounding(认知深度)、**A**dequacy(答案完整性)、**P**erturbation(鲁棒性)和**S**afety(安全性)的多维范式。关键的是,我们开发了一个完全自动化、基于指南的流程,以端到端方式构建符合GAPS标准的基准测试,克服了先前工作中可扩展性和主观性的局限。该流程通过构建证据邻域、创建双重图与树表示,并自动生成跨G级别的问题。评分标准由DeepResearch智能体在ReAct循环中模拟基于GRADE一致性、PICO驱动的证据评审过程综合生成。评分则由大型语言模型(LLM)评委组成的集成系统执行。验证结果表明,我们自动生成的问题质量较高,且与临床医生的判断一致。在该基准测试上评估当前最先进的模型揭示了关键失效模式:随着推理深度(G轴)增加,模型性能急剧下降;模型在答案完整性(A轴)方面存在困难;并且它们对对抗性扰动(P轴)以及某些安全问题(S轴)高度敏感。这种自动化、基于临床的方法为严格评估AI临床医生系统并指导其向更安全、更可靠的临床实践发展,提供了一种可重复且可扩展的途径。