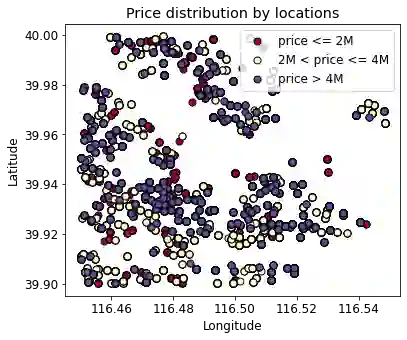
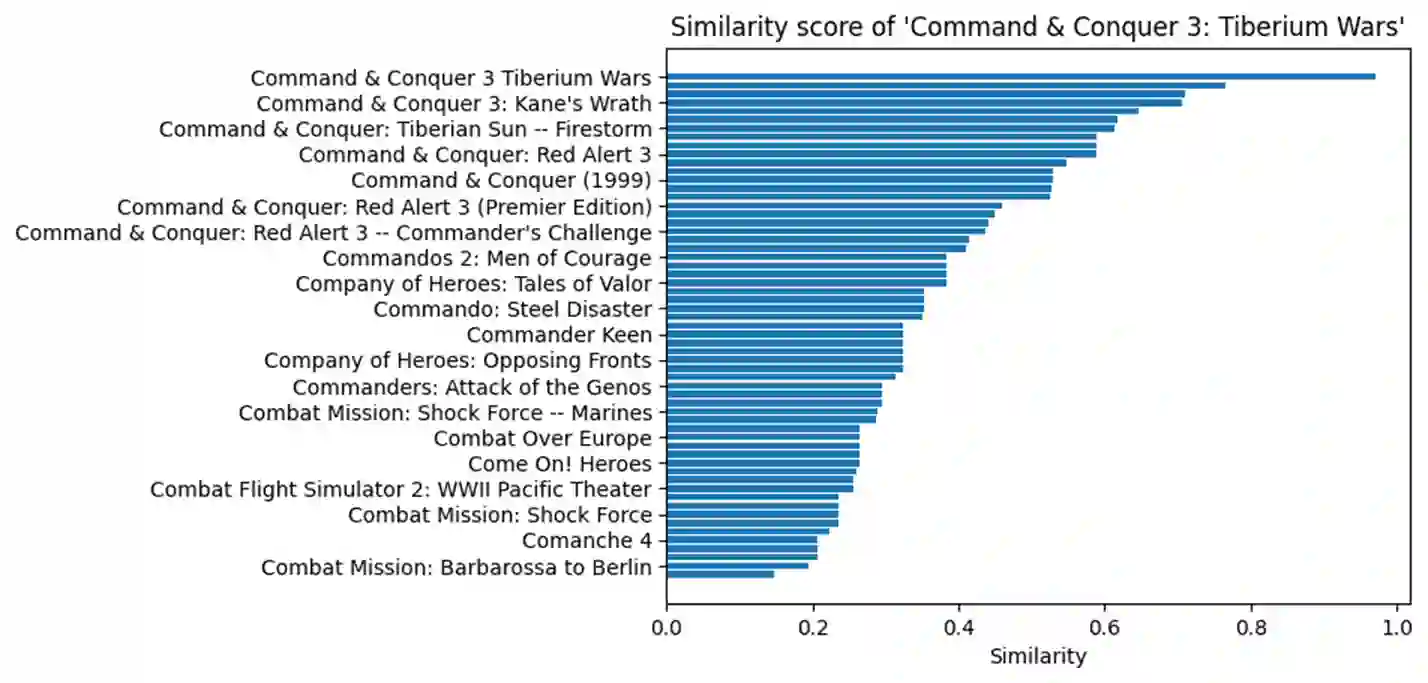
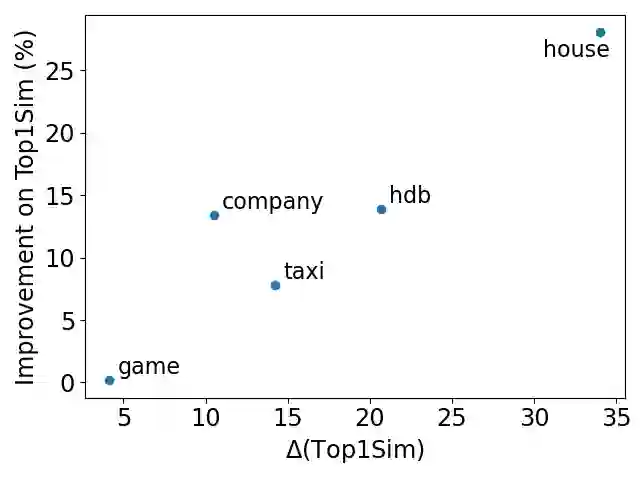
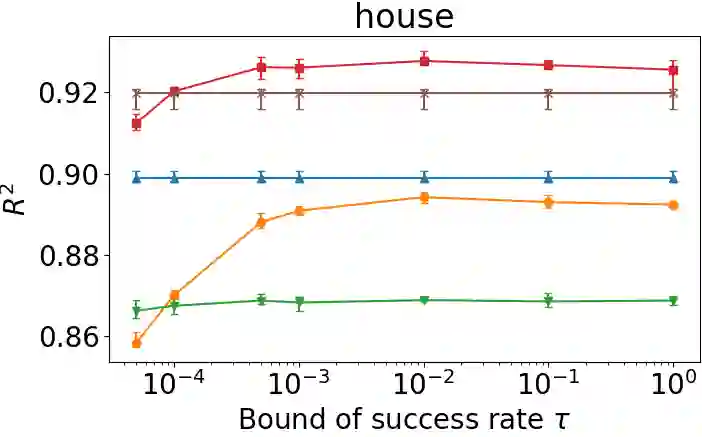
Federated learning is a learning paradigm to enable collaborative learning across different parties without revealing raw data. Notably, vertical federated learning (VFL), where parties share the same set of samples but only hold partial features, has a wide range of real-world applications. However, most existing studies in VFL disregard the "record linkage" process. They design algorithms either assuming the data from different parties can be exactly linked or simply linking each record with its most similar neighboring record. These approaches may fail to capture the key features from other less similar records. Moreover, such improper linkage cannot be corrected by training since existing approaches provide no feedback on linkage during training. In this paper, we design a novel coupled training paradigm, FedSim, that integrates one-to-many linkage into the training process. Besides enabling VFL in many real-world applications with fuzzy identifiers, FedSim also achieves better performance in traditional VFL tasks. Moreover, we theoretically analyze the additional privacy risk incurred by sharing similarities. Our experiments on eight datasets with various similarity metrics show that FedSim outperforms other state-of-the-art baselines. The codes of FedSim are available at https://github.com/Xtra-Computing/FedSim.
翻译:联邦学习是一种学习范式,能够在不泄露原始数据的情况下实现跨不同参与方的协作学习。值得注意的是,纵向联邦学习(VFL),其中各参与方共享同一组样本但仅持有部分特征,在现实应用中具有广泛用途。然而,现有的大多数VFL研究忽略了"记录链接"过程。它们设计的算法要么假设来自不同参与方的数据可以精确链接,要么简单地将每个记录与其最相似的邻近记录进行链接。这些方法可能无法从其他较不相似的记录中捕捉关键特征。此外,这种不当链接无法通过训练进行修正,因为现有方法在训练过程中对链接不提供任何反馈。在本文中,我们设计了一种新颖的耦合训练范式FedSim,它将一对多链接整合到训练过程中。除了在具有模糊标识符的许多现实应用中实现VFL外,FedSim在传统VFL任务中也取得了更好的性能。此外,我们从理论上分析了因共享相似性而带来的额外隐私风险。我们在八个数据集上使用各种相似性度量的实验表明,FedSim优于其他最新的基准方法。FedSim的代码可在https://github.com/Xtra-Computing/FedSim获取。