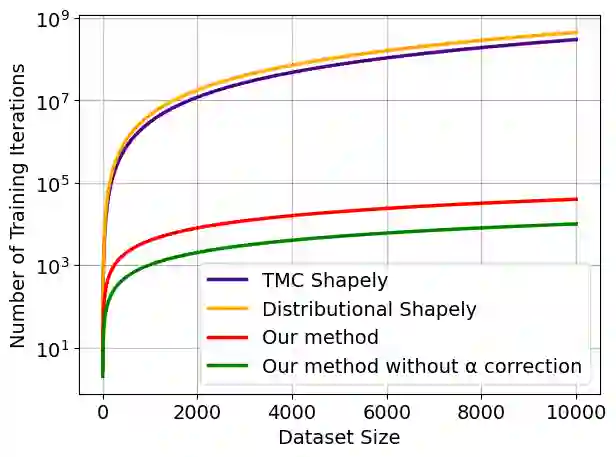
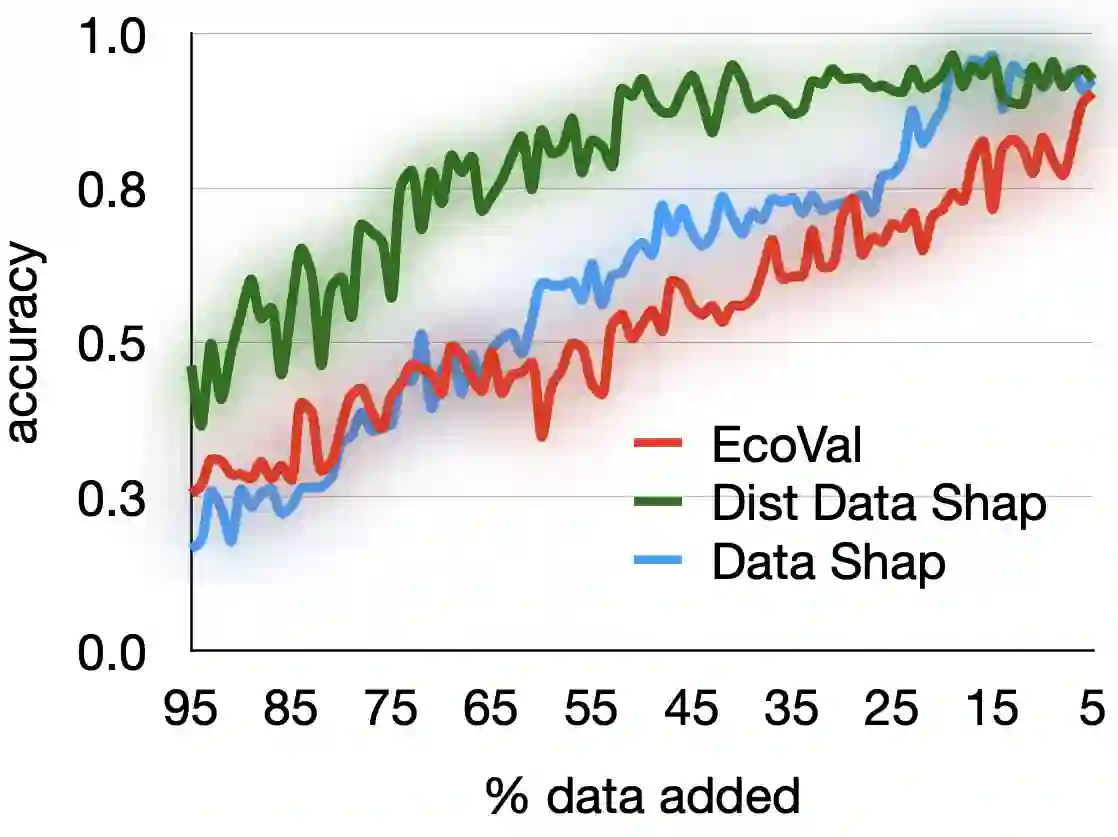
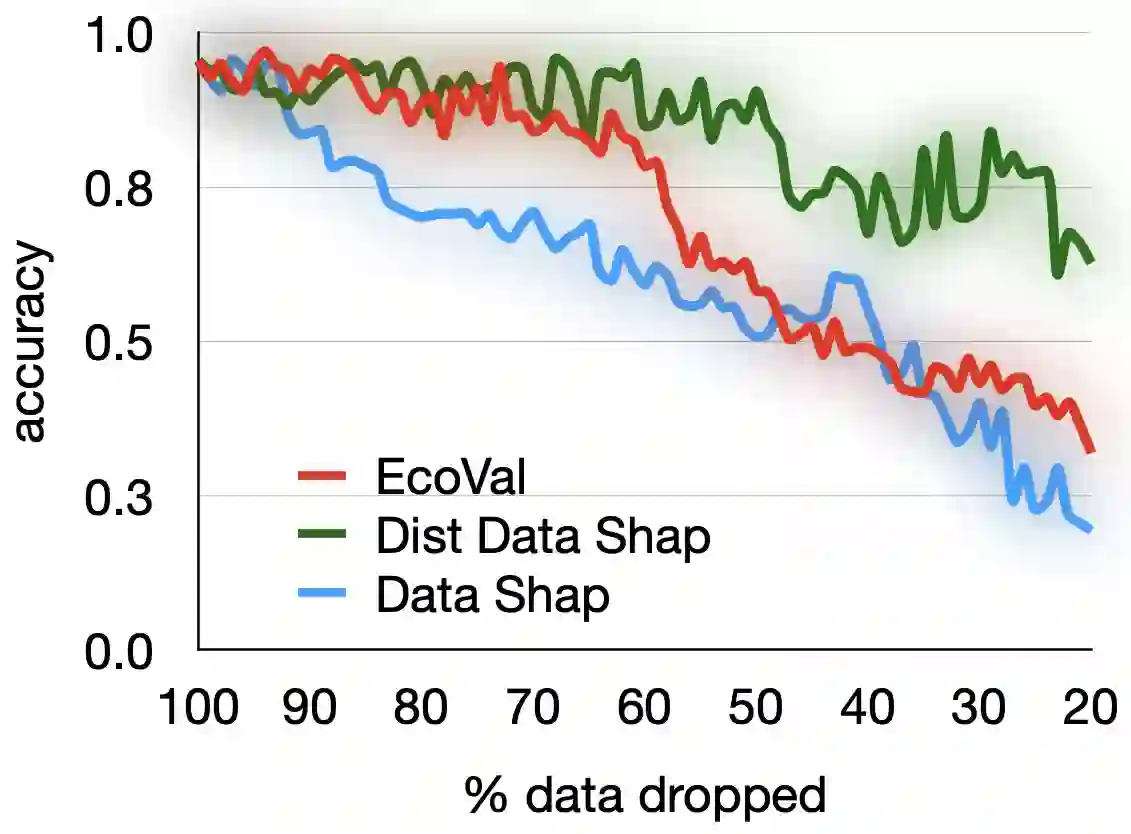
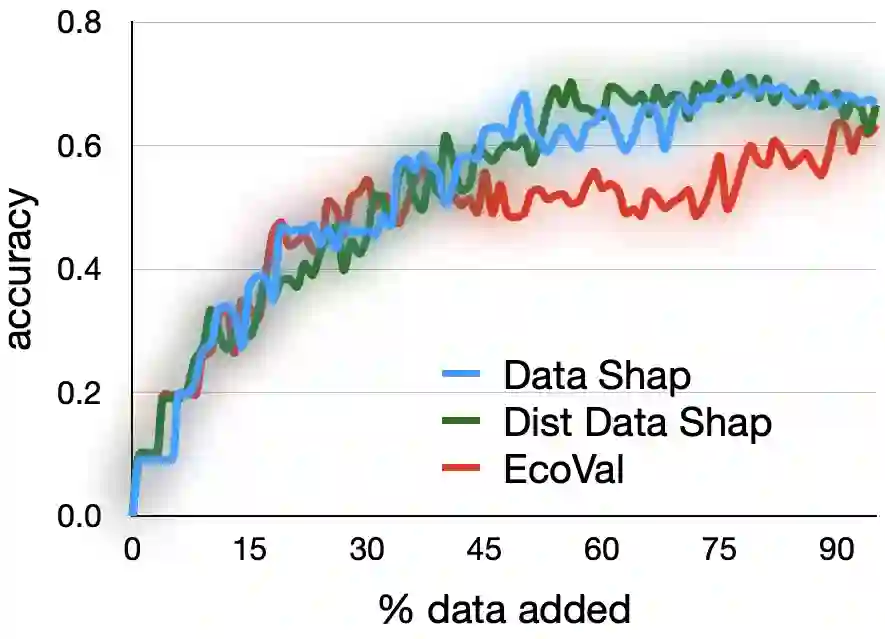
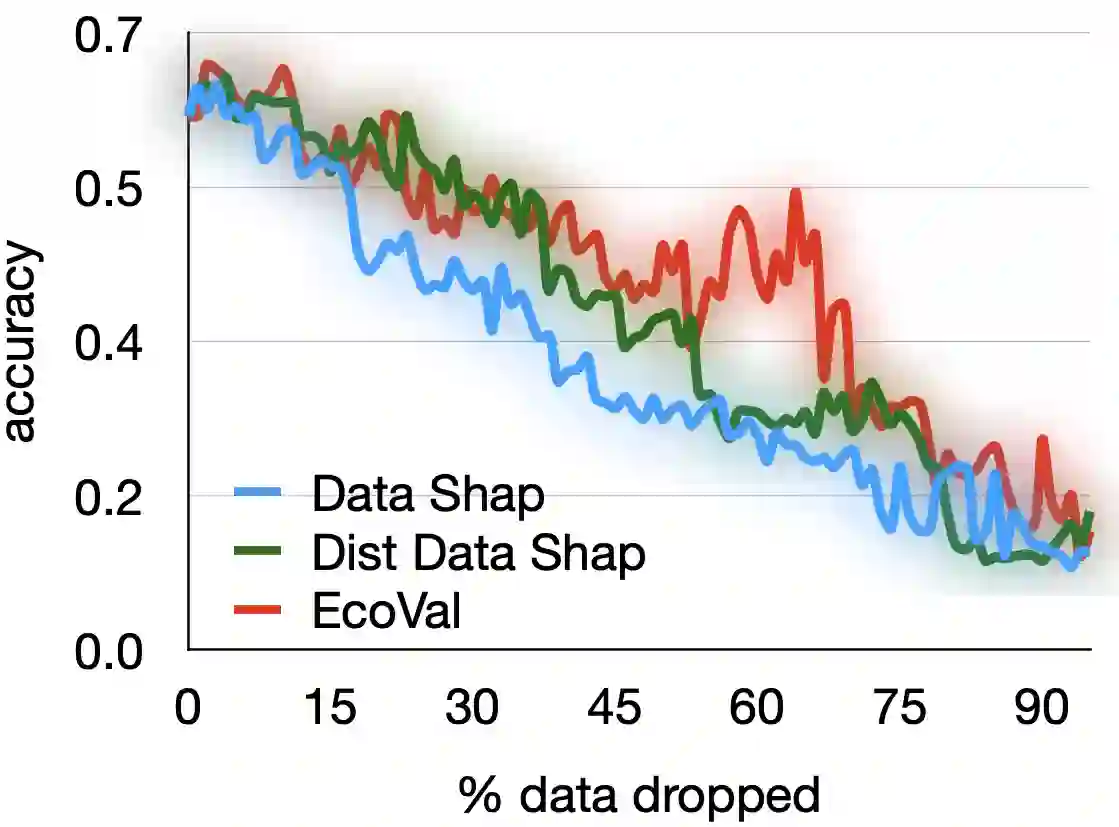
Quantifying the value of data within a machine learning workflow can play a pivotal role in making more strategic decisions in machine learning initiatives. The existing Shapley value based frameworks for data valuation in machine learning are computationally expensive as they require considerable amount of repeated training of the model to obtain the Shapley value. In this paper, we introduce an efficient data valuation framework EcoVal, to estimate the value of data for machine learning models in a fast and practical manner. Instead of directly working with individual data sample, we determine the value of a cluster of similar data points. This value is further propagated amongst all the member cluster points. We show that the overall data value can be determined by estimating the intrinsic and extrinsic value of each data. This is enabled by formulating the performance of a model as a \textit{production function}, a concept which is popularly used to estimate the amount of output based on factors like labor and capital in a traditional free economic market. We provide a formal proof of our valuation technique and elucidate the principles and mechanisms that enable its accelerated performance. We demonstrate the real-world applicability of our method by showcasing its effectiveness for both in-distribution and out-of-sample data. This work addresses one of the core challenges of efficient data valuation at scale in machine learning models.
翻译:在机器学习工作流中量化数据的价值,可为机器学习项目的战略决策提供关键支撑。现有基于Shapley值的机器学习数据估值框架,因需大量重复训练模型以获取Shapley值而计算成本高昂。本文提出高效数据估值框架EcoVal,以快速且实用的方式估计机器学习模型的数据价值。我们无需直接处理单个数据样本,而是通过确定相似数据点簇的价值,并将其进一步传播至所有簇内成员点。研究表明,整体数据价值可通过估计每个数据的固有价值与外在价值来确定。这一方法通过将模型性能表达为"生产函数"实现——生产函数是传统自由经济市场中用于根据劳动力、资本等要素估算产出量的常用概念。我们提供了估值技术的正式证明,并阐释了其实现加速性能的原理与机制。通过展示本方法在分布内数据与样本外数据中的有效性,我们验证了其实用性。这项工作解决了机器学习模型中大规模高效数据估值这一核心难题。