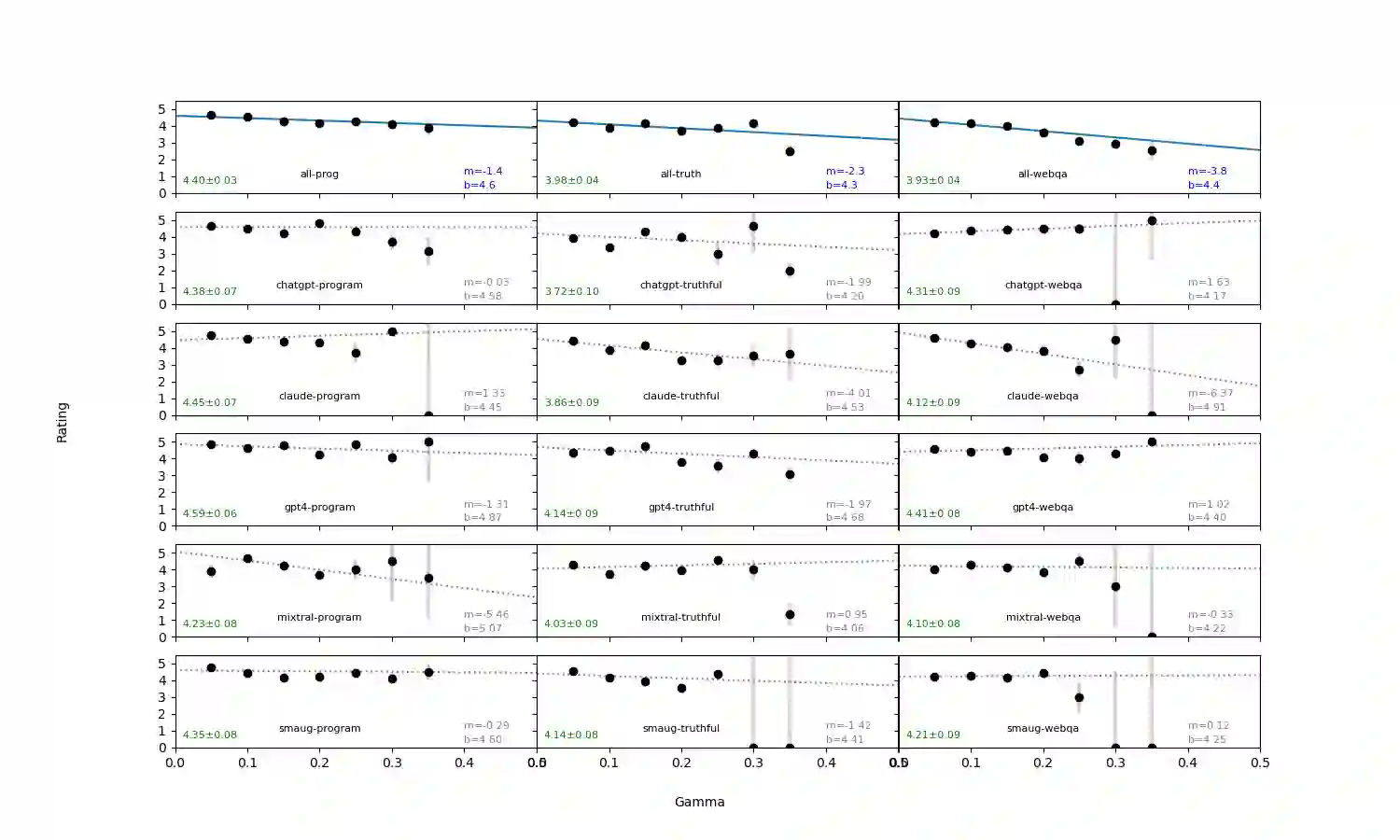
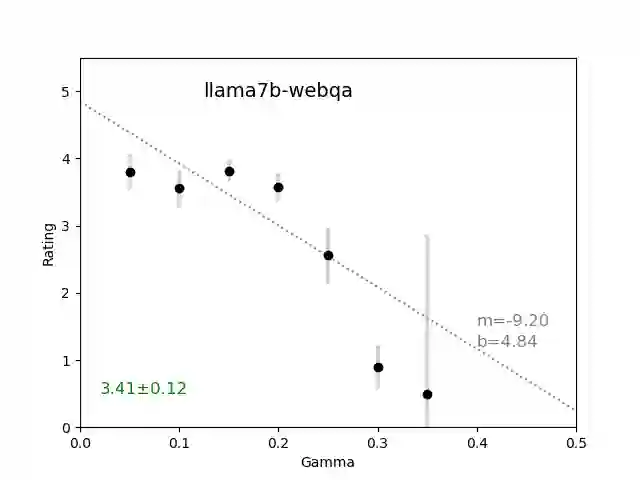
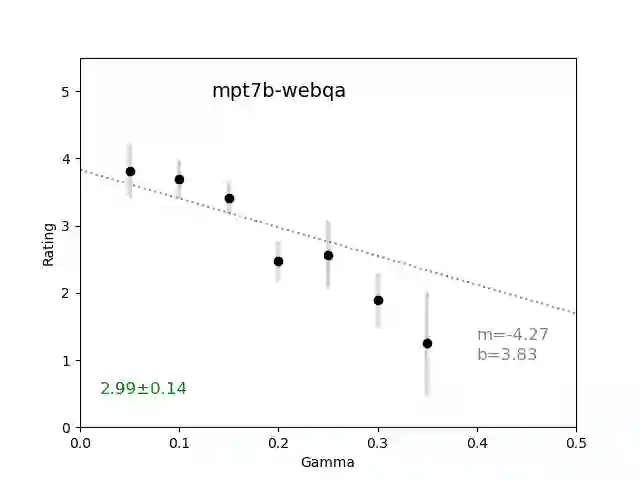
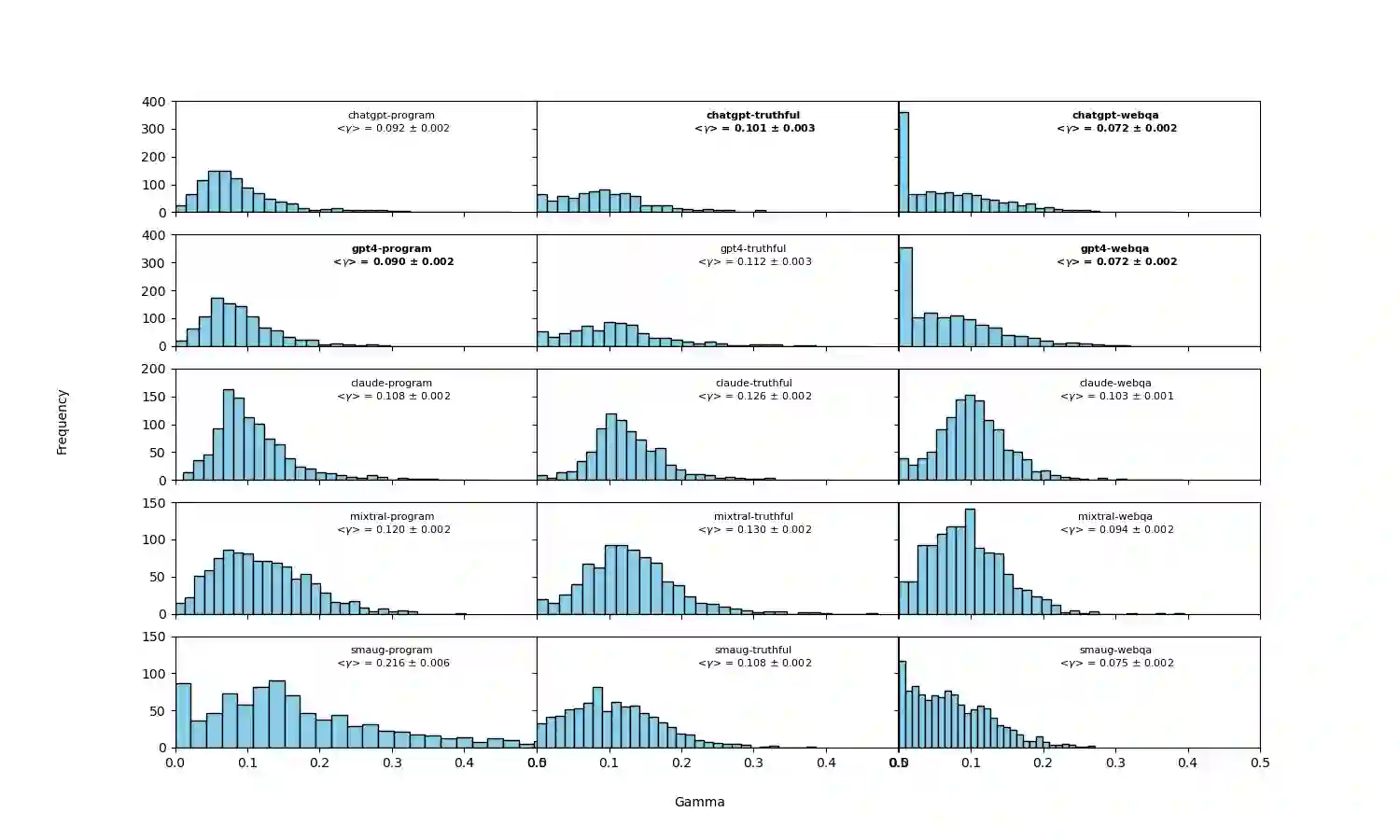
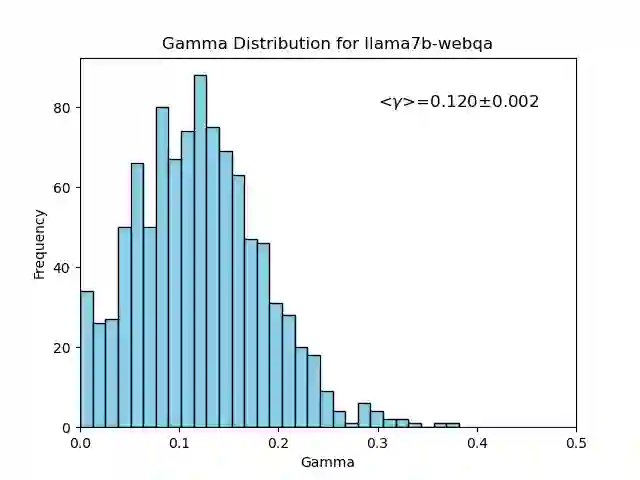
We introduce an intuitive method to test the robustness (stability and explainability) of any black-box LLM in real-time, based upon the local deviation from harmoniticity, denoted as $\gamma$. To the best of our knowledge this is the first completely model-agnostic and unsupervised method of measuring the robustness of any given response from an LLM, based upon the model itself conforming to a purely mathematical standard. We conduct human annotation experiments to show the positive correlation of $\gamma$ with false or misleading answers, and demonstrate that following the gradient of $\gamma$ in stochastic gradient ascent efficiently exposes adversarial prompts. Measuring $\gamma$ across thousands of queries in popular LLMs (GPT-4, ChatGPT, Claude-2.1, Mixtral-8x7B, Smaug-72B, Llama2-7B, and MPT-7B) allows us to estimate the liklihood of wrong or hallucinatory answers automatically and quantitatively rank the reliability of these models in various objective domains (Web QA, TruthfulQA, and Programming QA). Across all models and domains tested, human ratings confirm that $\gamma \to 0$ indicates trustworthiness, and the low-$\gamma$ leaders among these models are GPT-4, ChatGPT, and Smaug-72B.
翻译:我们提出一种直观方法,基于局部谐调偏差(记为$\gamma$)实时测试任意黑盒语言模型的鲁棒性(稳定性与可解释性)。据我们所知,这是首个完全模型无关且无监督的方法,通过使模型自身符合纯数学标准来衡量语言模型任意响应的鲁棒性。我们进行人工标注实验,证明$\gamma$值与虚假或误导性回答呈正相关,并展示沿随机梯度上升方向追踪$\gamma$梯度可高效暴露对抗性提示。通过测量主流语言模型(GPT-4、ChatGPT、Claude-2.1、Mixtral-8x7B、Smaug-72B、Llama2-7B及MPT-7B)数千次查询中的$\gamma$值,我们可自动估计错误或幻觉答案的可能性,并定量排序这些模型在客观领域(Web问答、TruthfulQA及编程问答)的可靠性。在所有测试模型与领域中,人工评估证实$\gamma \to 0$代表可信赖性,而低$\gamma$领先的模型包括GPT-4、ChatGPT及Smaug-72B。