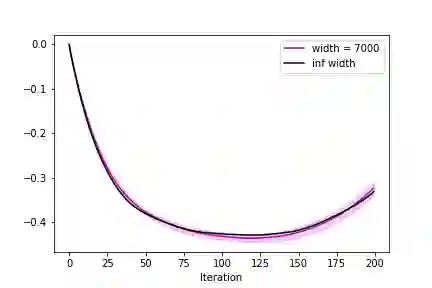
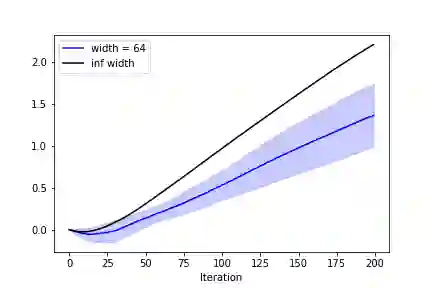
Going beyond stochastic gradient descent (SGD), what new phenomena emerge in wide neural networks trained by adaptive optimizers like Adam? Here we show: The same dichotomy between feature learning and kernel behaviors (as in SGD) holds for general optimizers as well, including Adam -- albeit with a nonlinear notion of "kernel." We derive the corresponding "neural tangent" and "maximal update" limits for any architecture. Two foundational advances underlie the above results: 1) A new Tensor Program language, NEXORT, that can express how adaptive optimizers process gradients into updates. 2) The introduction of bra-ket notation to drastically simplify expressions and calculations in Tensor Programs. This work summarizes and generalizes all previous results in the Tensor Programs series of papers.
翻译:超越随机梯度下降(SGD),自适应优化器(如Adam)在宽神经网络训练中会涌现出哪些新现象?本文表明:特征学习与核行为之间的二象性(如SGD中的情形)同样适用于包括Adam在内的一般优化器——尽管此时“核”的概念需以非线性方式理解。我们推导了任意架构下的相应“神经正切”与“最大更新”极限。上述成果基于两个基础性进展:1)一种新的张量程序语言NEXORT,能够表达自适应优化器如何将梯度转化为更新量;2)引入狄拉克符号(bra-ket notation),极大简化了张量程序中的表达式与计算。本工作总结并推广了张量程序系列论文中的所有先前结果。