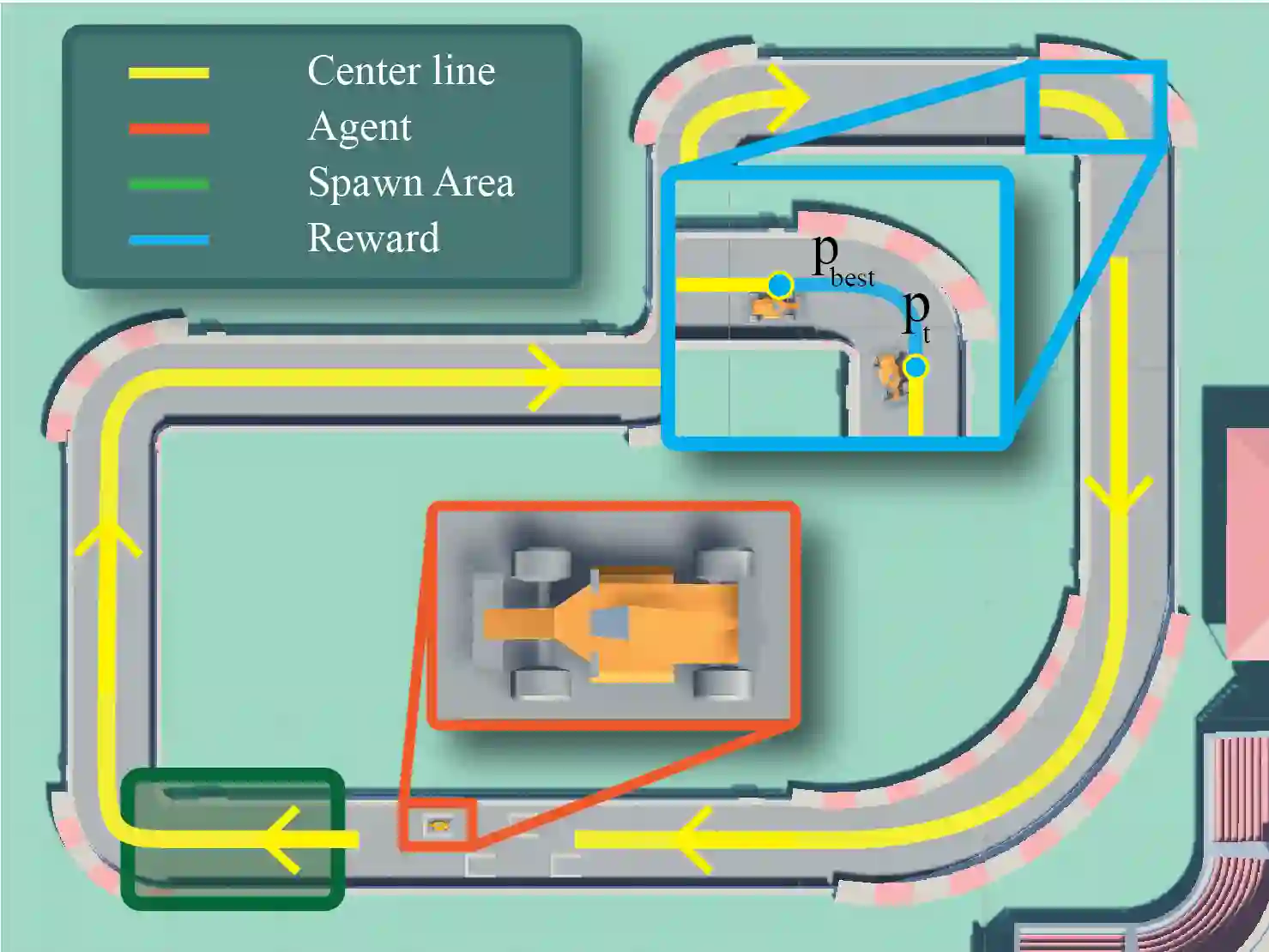
Offline Reinforcement Learning (ORL) is a promising approach to reduce the high sample complexity of traditional Reinforcement Learning (RL) by eliminating the need for continuous environmental interactions. ORL exploits a dataset of pre-collected transitions and thus expands the range of application of RL to tasks in which the excessive environment queries increase training time and decrease efficiency, such as in modern AAA games. This paper introduces OfflineMania a novel environment for ORL research. It is inspired by the iconic TrackMania series and developed using the Unity 3D game engine. The environment simulates a single-agent racing game in which the objective is to complete the track through optimal navigation. We provide a variety of datasets to assess ORL performance. These datasets, created from policies of varying ability and in different sizes, aim to offer a challenging testbed for algorithm development and evaluation. We further establish a set of baselines for a range of Online RL, ORL, and hybrid Offline to Online RL approaches using our environment.
翻译:离线强化学习(ORL)是一种有前景的方法,它通过消除持续环境交互的需求,降低了传统强化学习(RL)的高样本复杂度。ORL利用预先收集的转移数据集,从而将RL的应用范围扩展到那些因过度环境查询而增加训练时间、降低效率的任务中,例如现代AAA级游戏。本文介绍了OfflineMania,一个用于ORL研究的新型环境。其灵感来源于标志性的TrackMania系列,并使用Unity 3D游戏引擎开发。该环境模拟了一个单智能体竞速游戏,其目标是通过最优导航完成赛道。我们提供了多种数据集来评估ORL性能。这些数据集由不同能力策略生成且规模各异,旨在为算法开发和评估提供一个具有挑战性的测试平台。我们进一步利用该环境,为一系列在线RL、ORL以及混合式离线到在线RL方法建立了一组基线。