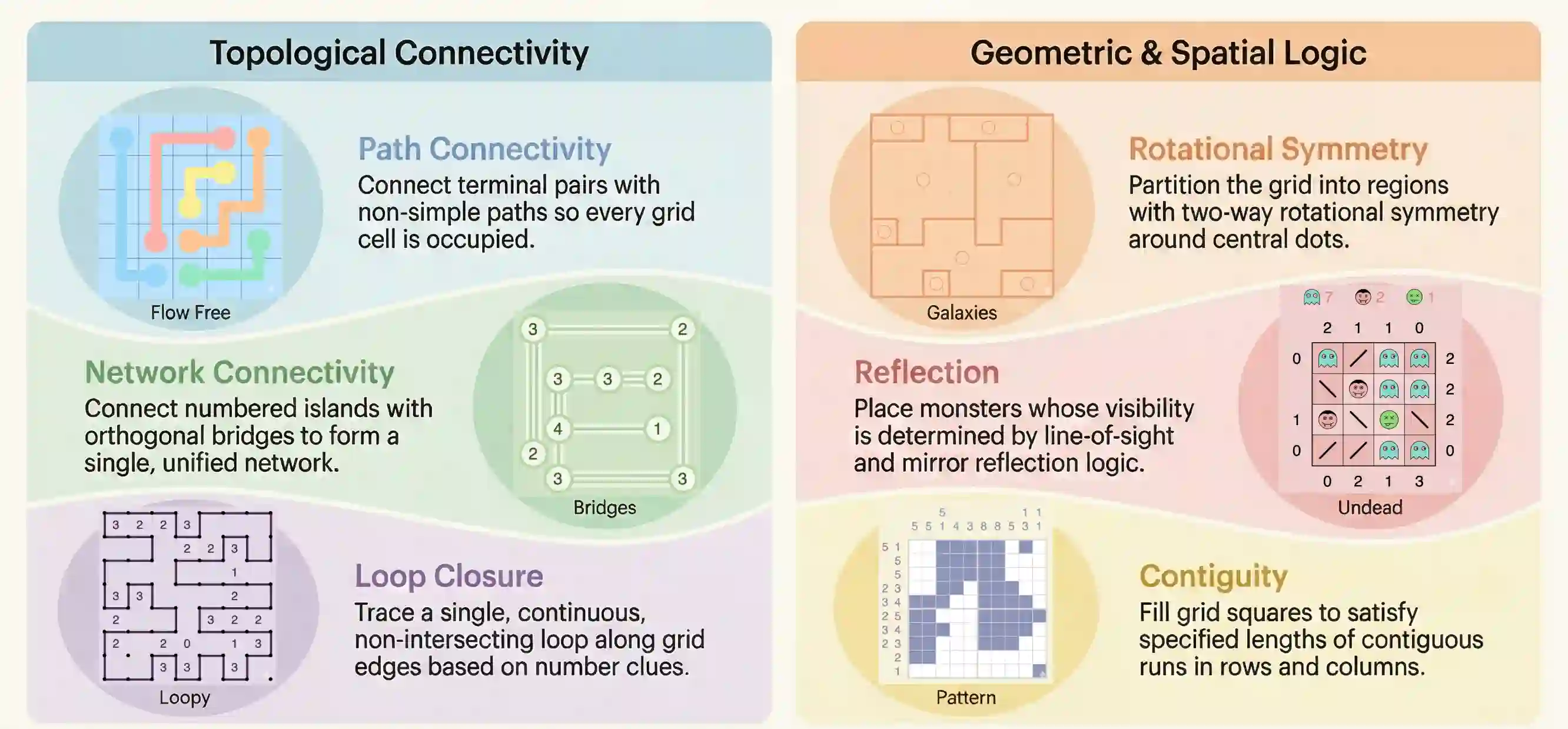
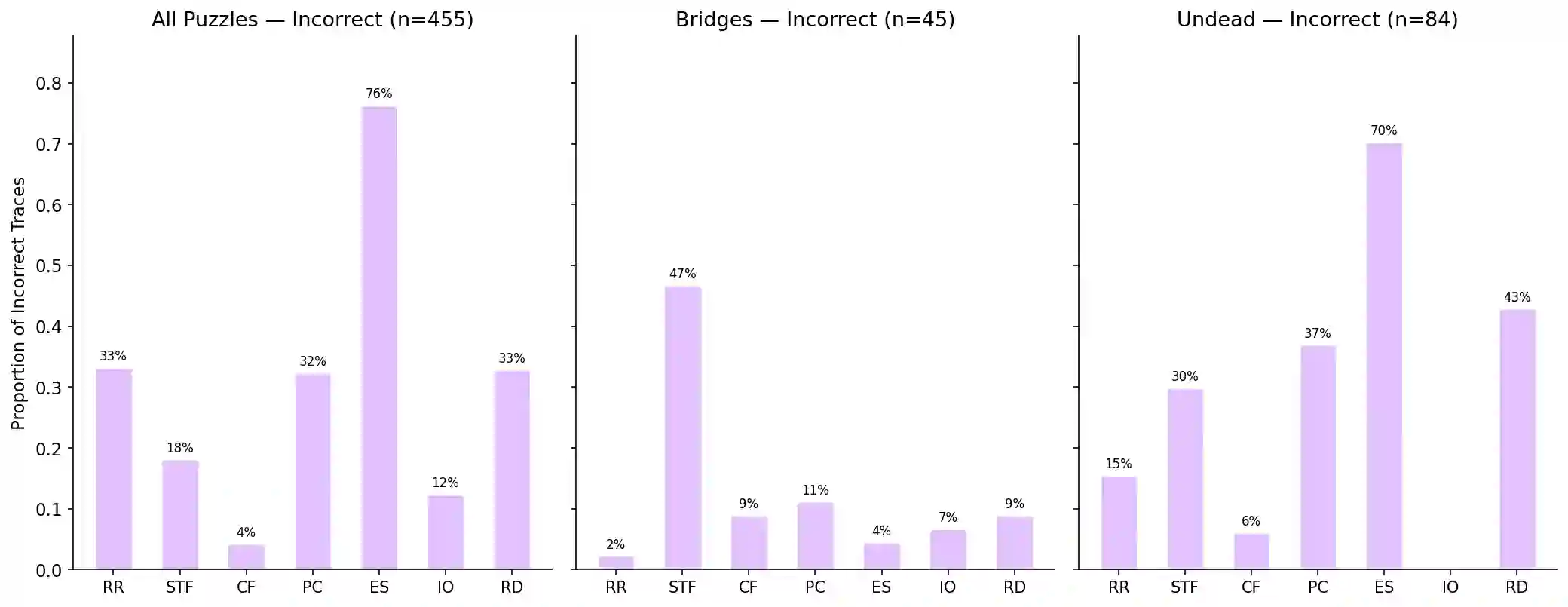
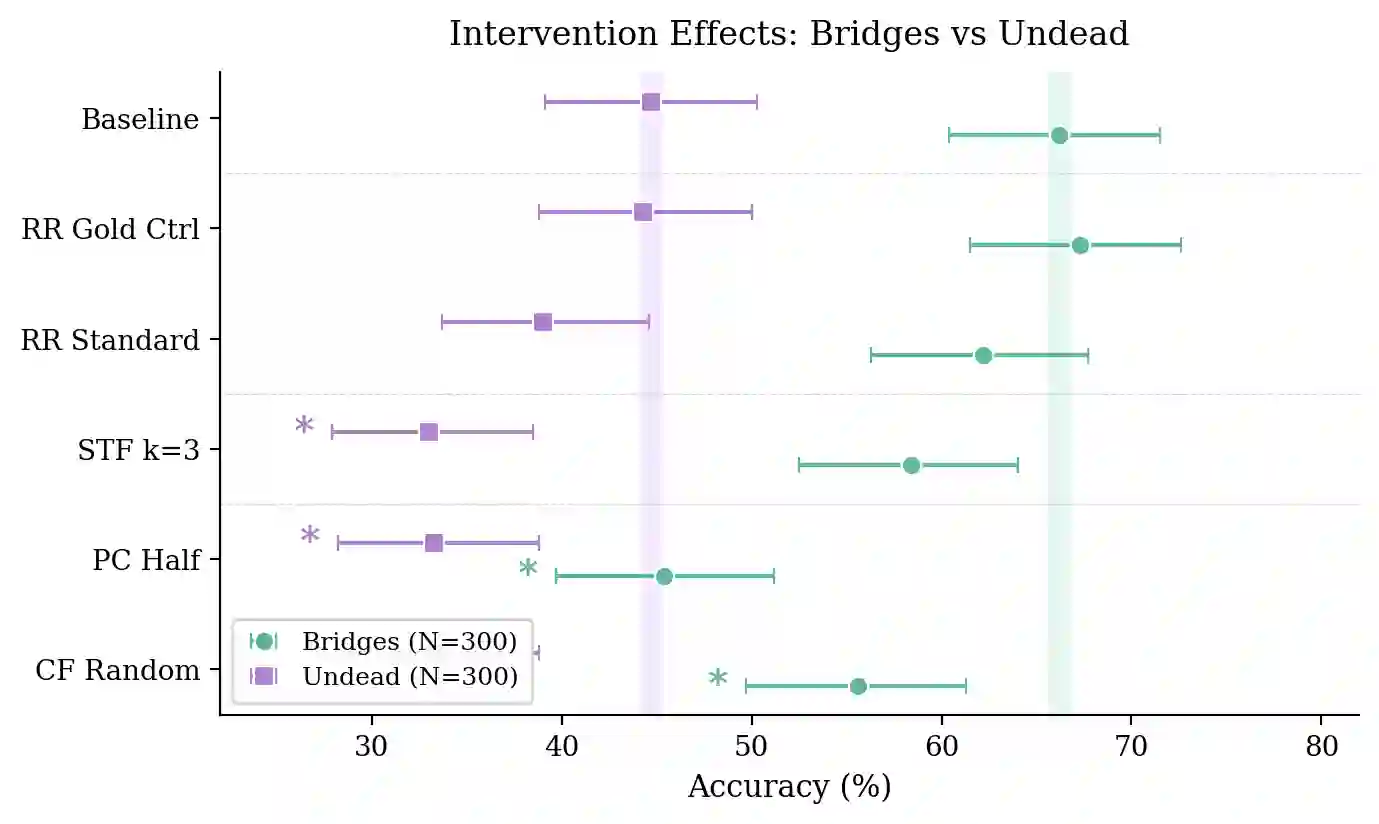
Solving topological grid puzzles requires reasoning over global spatial invariants such as connectivity, loop closure, and region symmetry and remains challenging for even the most powerful large language models (LLMs). To study these abilities under controlled settings, we introduce TopoBench, a benchmark of six puzzle families across three difficulty levels. We evaluate strong reasoning LLMs on TopoBench and find that even frontier models solve fewer than one quarter of hard instances, with two families nearly unsolved. To investigate whether these failures stem from reasoning limitations or from difficulty extracting and maintaining spatial constraints, we annotate 750 chain of thought traces with an error taxonomy that surfaces four candidate causal failure modes, then test them with targeted interventions simulating each error type. These interventions show that certain error patterns like premature commitment and constraint forgetting have a direct impact on the ability to solve the puzzle, while repeated reasoning is a benign effect of search. Finally we study mitigation strategies including prompt guidance, cell-aligned grid representations and tool-based constraint checking, finding that the bottleneck lies in extracting constraints from spatial representations and not in reasoning over them. Code and data are available at github.com/mayug/topobench-benchmark.
翻译:解决拓扑网格谜题需要对连通性、环路闭合和区域对称性等全局空间不变量进行推理,即使对于最强大的大语言模型(LLMs)而言仍具挑战性。为了在受控环境下研究这些能力,我们提出了TopoBench,这是一个包含三个难度级别、涵盖六个谜题系列的基准测试集。我们在TopoBench上评估了多个强大的推理型LLMs,发现即使是前沿模型也只能解决不到四分之一的困难实例,其中有两个系列几乎无法解决。为了探究这些失败源于推理局限还是源于提取与维持空间约束的困难,我们使用一个错误分类法标注了750条思维链轨迹,该分类法揭示了四种可能的因果失效模式,随后通过模拟每种错误类型的针对性干预进行测试。这些干预表明,某些错误模式(如过早承诺和约束遗忘)对解决谜题的能力有直接影响,而重复推理则是搜索过程中的良性效应。最后,我们研究了包括提示引导、单元格对齐的网格表示和基于工具的约束检查在内的缓解策略,发现瓶颈在于从空间表示中提取约束,而非对这些约束进行推理。代码与数据可在github.com/mayug/topobench-benchmark获取。