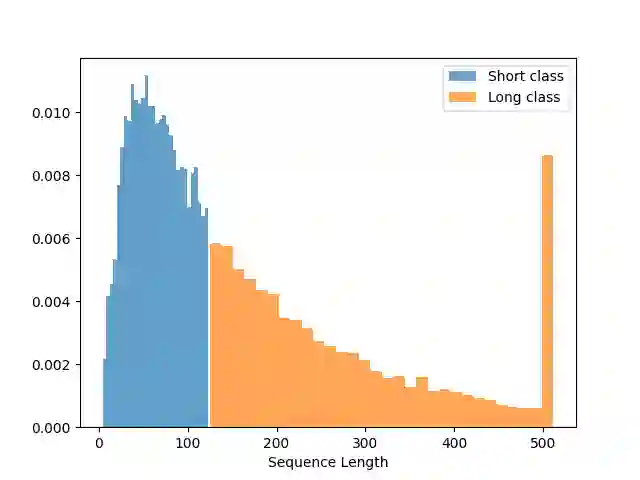
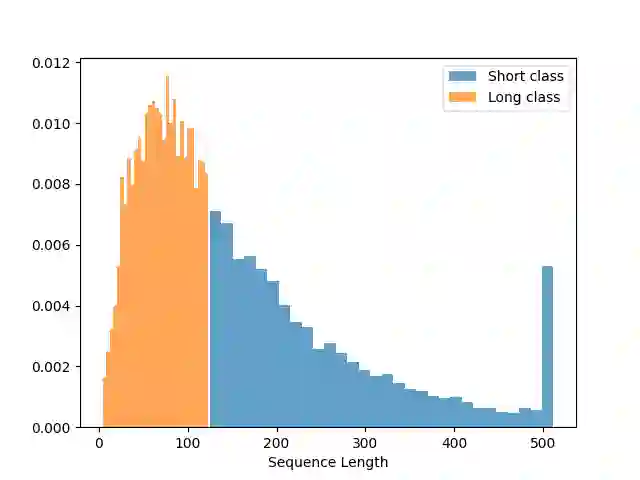
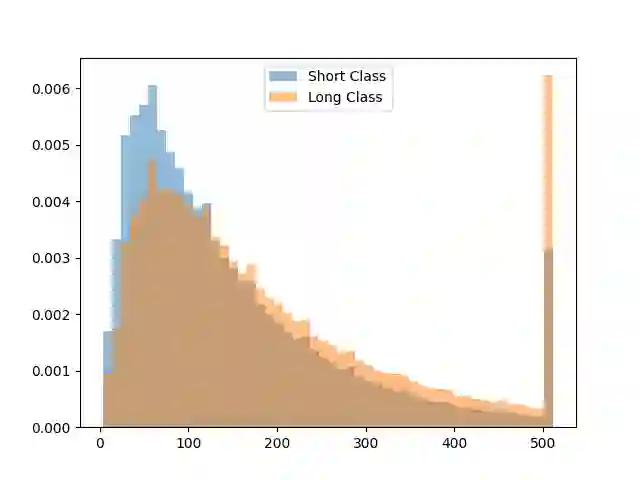
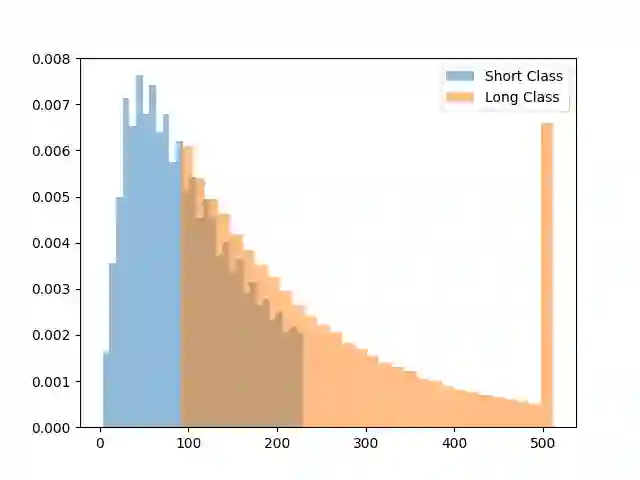
Classification algorithms using Transformer architectures can be affected by the sequence length learning problem whenever observations from different classes have a different length distribution. This problem causes models to use sequence length as a predictive feature instead of relying on important textual information. Although most public datasets are not affected by this problem, privately owned corpora for fields such as medicine and insurance may carry this data bias. The exploitation of this sequence length feature poses challenges throughout the value chain as these machine learning models can be used in critical applications. In this paper, we empirically expose this problem and present approaches to minimize its impacts.
翻译:采用Transformer架构的分类算法,当不同类别的观测样本具有不同长度分布时,会受到序列长度学习问题的影响。该问题导致模型将序列长度作为预测特征,而非依赖重要的文本信息。尽管多数公开数据集不受此问题影响,但在医学和保险等领域的私有语料库中可能存在此类数据偏差。对序列长度特征的利用会引发价值链中的挑战,因为这些机器学习模型可能应用于关键场景。本文通过实验揭示该问题,并提出降低其影响的方法。