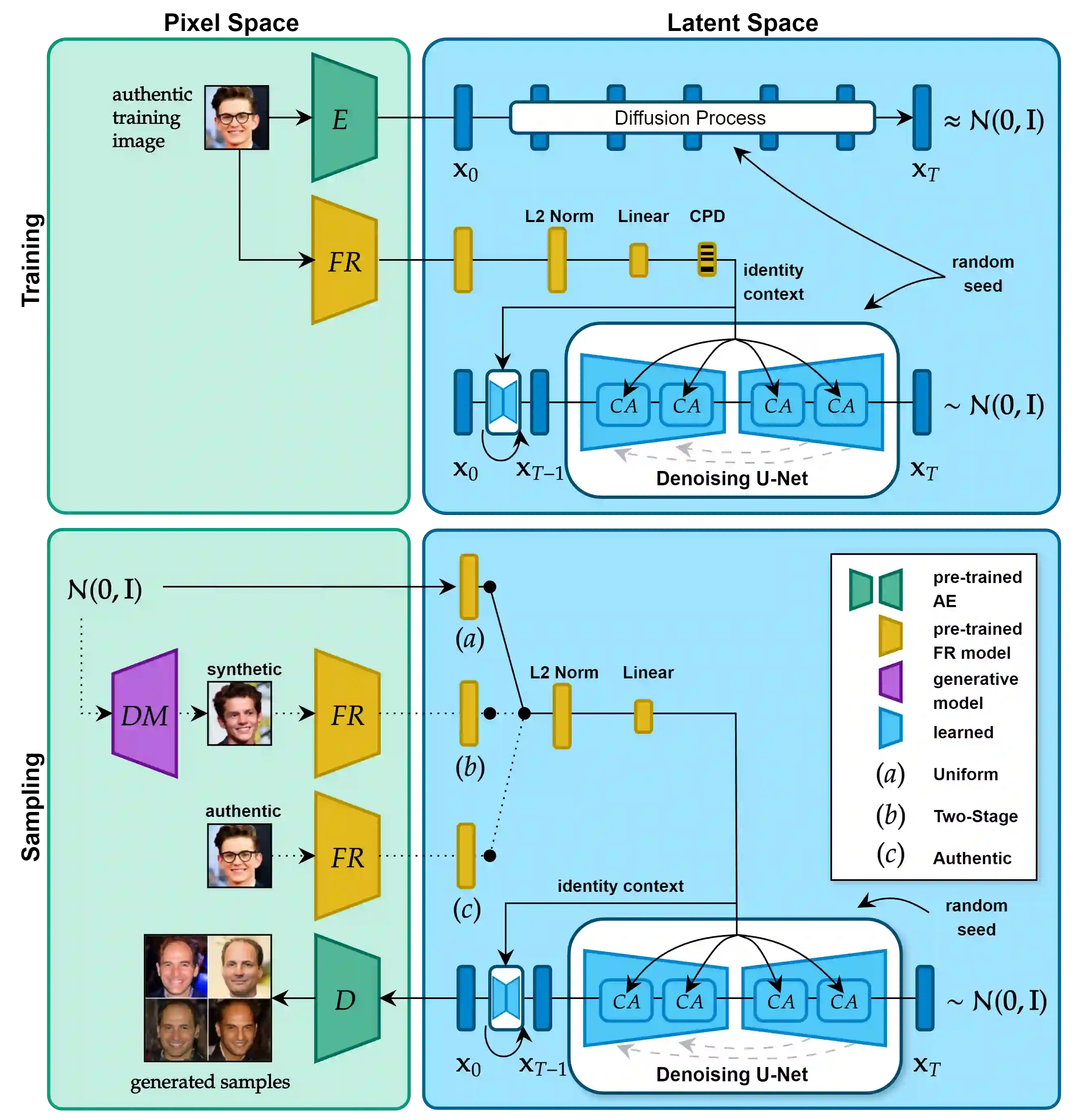
The availability of large-scale authentic face databases has been crucial to the significant advances made in face recognition research over the past decade. However, legal and ethical concerns led to the recent retraction of many of these databases by their creators, raising questions about the continuity of future face recognition research without one of its key resources. Synthetic datasets have emerged as a promising alternative to privacy-sensitive authentic data for face recognition development. However, recent synthetic datasets that are used to train face recognition models suffer either from limitations in intra-class diversity or cross-class (identity) discrimination, leading to less optimal accuracies, far away from the accuracies achieved by models trained on authentic data. This paper targets this issue by proposing IDiff-Face, a novel approach based on conditional latent diffusion models for synthetic identity generation with realistic identity variations for face recognition training. Through extensive evaluations, our proposed synthetic-based face recognition approach pushed the limits of state-of-the-art performances, achieving, for example, 98.00% accuracy on the Labeled Faces in the Wild (LFW) benchmark, far ahead from the recent synthetic-based face recognition solutions with 95.40% and bridging the gap to authentic-based face recognition with 99.82% accuracy.
翻译:过去十年中,大规模真实人脸数据库的可用性对推动人脸识别研究取得重大进展至关重要。然而,法律和伦理问题导致许多此类数据库近期被其创建者撤回,这引发了人们对未来人脸识别研究在缺少关键资源的情况下能否持续发展的质疑。合成数据集已成为开发人脸识别中隐私敏感真实数据的有前景替代方案。然而,近期用于训练人脸识别模型的合成数据集,要么存在类内多样性不足,要么存在跨类(身份)区分性差的问题,导致精度欠佳,远不及在真实数据上训练模型所达到的精度。本文针对此问题提出IDiff-Face,一种基于条件潜在扩散模型的新方法,用于生成具有逼真身份变化的合成身份以进行人脸识别训练。通过广泛评估,我们提出的基于合成数据的人脸识别方法将最新技术的性能推至新高,例如在人脸标注数据集(LFW)基准上达到98.00%的准确率,远超近期基于合成数据的人脸识别方案的95.40%,并缩小了与基于真实数据的人脸识别(准确率99.82%)之间的差距。