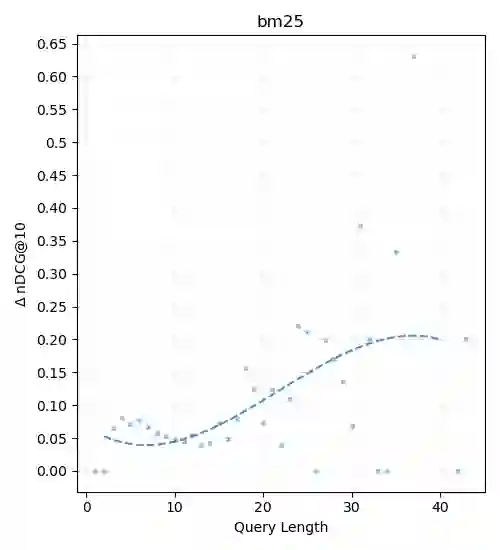
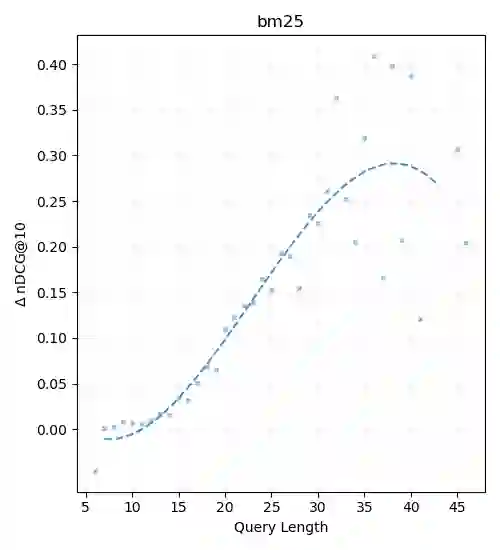
Recent progress in information retrieval finds that embedding query and document representation into multi-vector yields a robust bi-encoder retriever on out-of-distribution datasets. In this paper, we explore whether late interaction, the simplest form of multi-vector, is also helpful to neural rerankers that only use the [CLS] vector to compute the similarity score. Although intuitively, the attention mechanism of rerankers at the previous layers already gathers the token-level information, we find adding late interaction still brings an extra 5% improvement in average on out-of-distribution datasets, with little increase in latency and no degradation in in-domain effectiveness. Through extensive experiments and analysis, we show that the finding is consistent across different model sizes and first-stage retrievers of diverse natures and that the improvement is more prominent on longer queries.
翻译:近期信息检索领域的研究表明,将查询与文档表示嵌入到多向量中,能够构建稳健的双编码器检索器,在分布外数据集上表现优异。本文探讨了多向量最简形式——晚期交互——是否同样有助于仅使用[CLS]向量计算相似度得分的神经重排序器。尽管直觉上前置层级中重排序器的注意力机制已聚集了词元级信息,但我们发现引入晚期交互后,分布外数据集上的平均性能仍能额外提升5%,且延迟几乎无增加、领域内有效性未下降。通过大量实验与分析,我们证实该发现在不同模型规模及多种类型的第一阶段检索器中均具有一致性,且性能提升在长查询场景下更为显著。