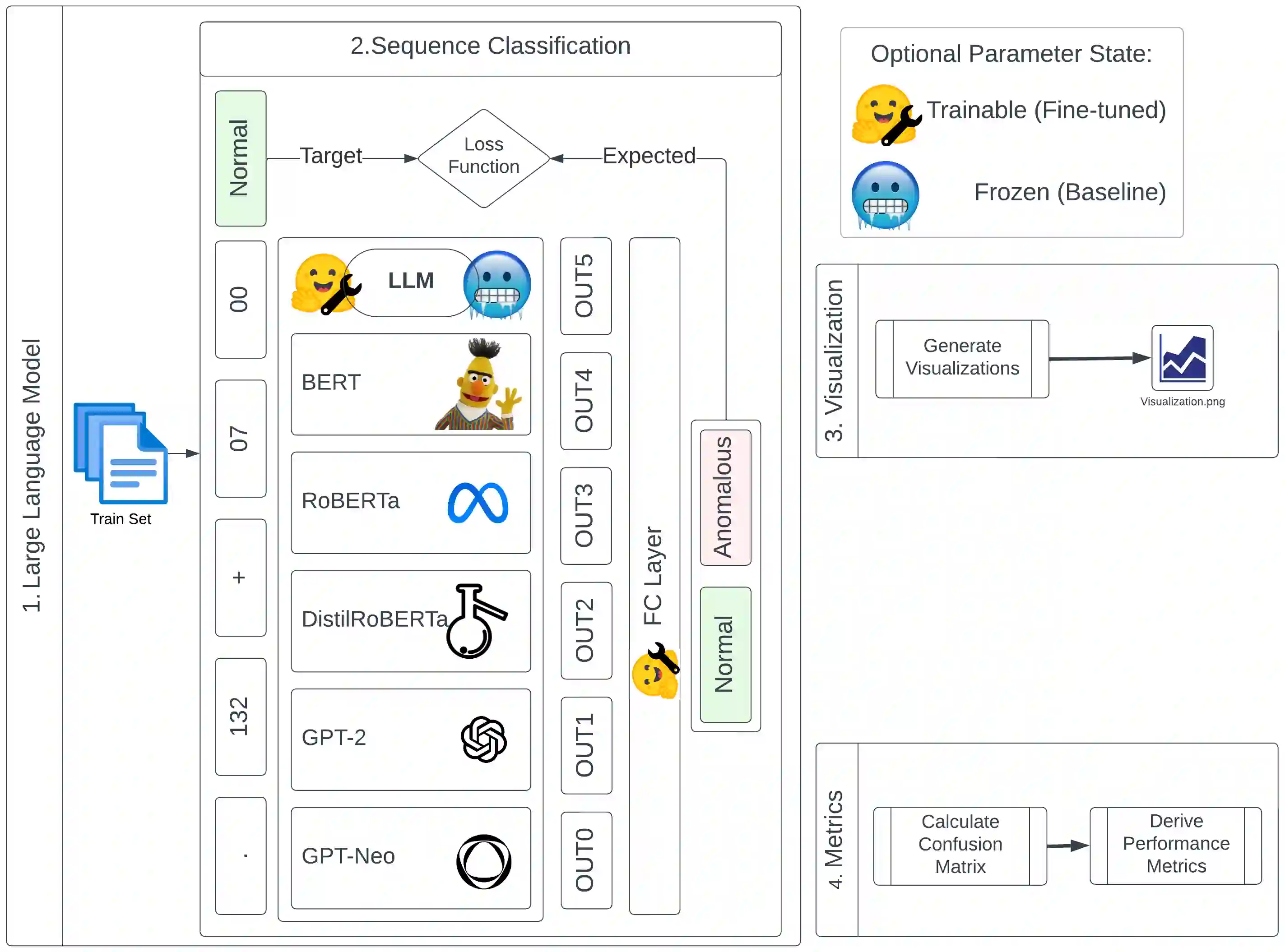
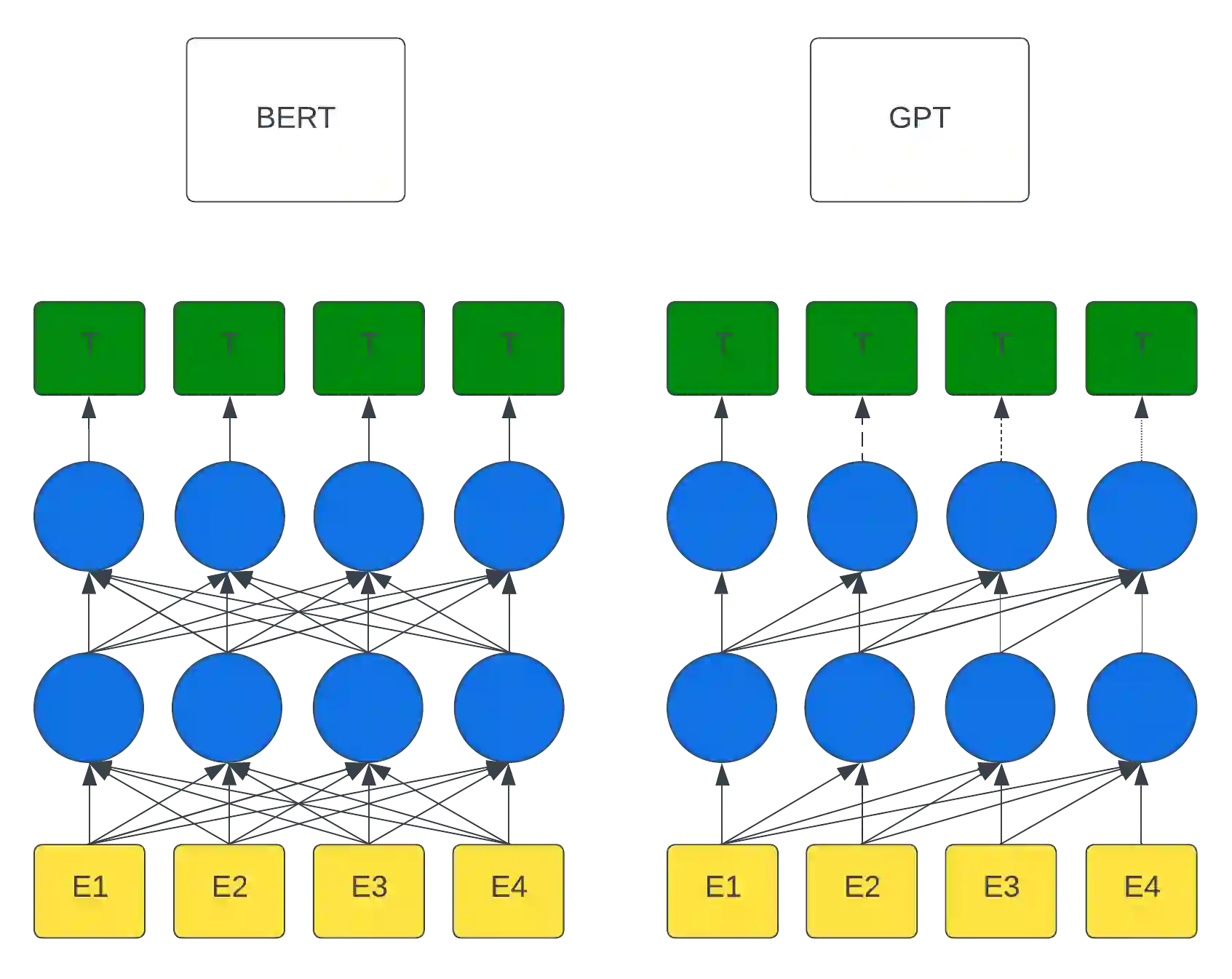
Large Language Models (LLM) continue to demonstrate their utility in a variety of emergent capabilities in different fields. An area that could benefit from effective language understanding in cybersecurity is the analysis of log files. This work explores LLMs with different architectures (BERT, RoBERTa, DistilRoBERTa, GPT-2, and GPT-Neo) that are benchmarked for their capacity to better analyze application and system log files for security. Specifically, 60 fine-tuned language models for log analysis are deployed and benchmarked. The resulting models demonstrate that they can be used to perform log analysis effectively with fine-tuning being particularly important for appropriate domain adaptation to specific log types. The best-performing fine-tuned sequence classification model (DistilRoBERTa) outperforms the current state-of-the-art; with an average F1-Score of 0.998 across six datasets from both web application and system log sources. To achieve this, we propose and implement a new experimentation pipeline (LLM4Sec) which leverages LLMs for log analysis experimentation, evaluation, and analysis.
翻译:大型语言模型(LLM)持续在多个领域展现出多样化的新兴能力。在网络安全领域,日志文件分析可受益于高效的语言理解能力。本研究探索了不同架构的大型语言模型(包括BERT、RoBERTa、DistilRoBERTa、GPT-2和GPT-Neo),并对其分析应用程序和系统日志文件以保障安全的能力进行了基准测试。具体而言,我们部署并测试了60个针对日志分析进行微调的语言模型。结果表明,这些模型可有效执行日志分析,其中微调对于特定日志类型的领域适配尤为关键。表现最佳的微调序列分类模型(DistilRoBERTa)超越了当前最先进水平:在来自Web应用与系统日志源的六个数据集上,其平均F1分数达到0.998。为实现此目标,我们提出并实现了一个新型实验管道(LLM4Sec),利用LLM进行日志分析的实验、评估与分析。