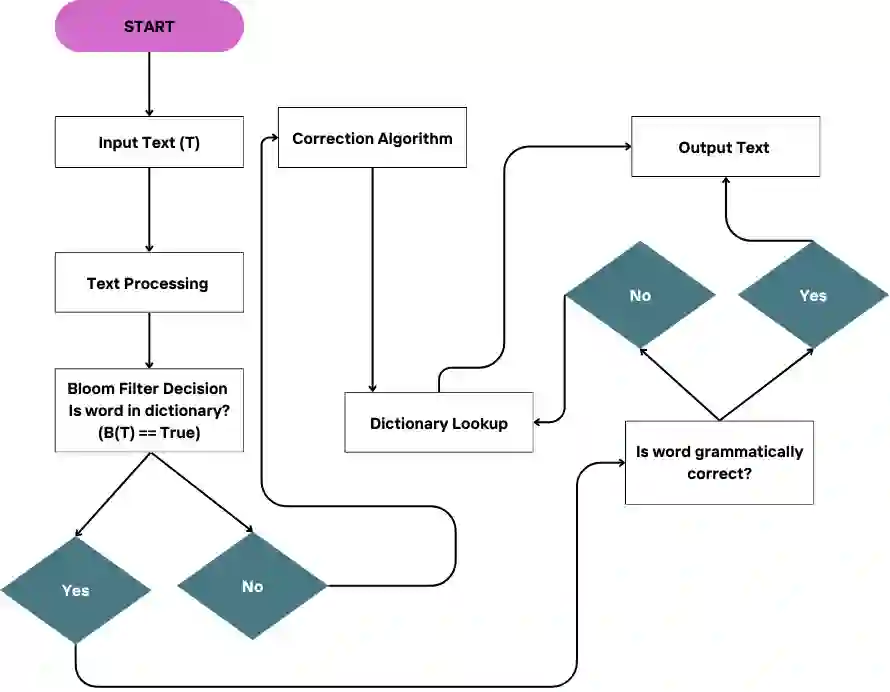
Grammatical error correction (GEC) aims to improve text quality and readability. Previous work on the task focused primarily on high-resource languages, while low-resource languages lack robust tools. To address this shortcoming, we present a study on GEC for Zarma, a language spoken by over five million people in West Africa. We compare three approaches: rule-based methods, machine translation (MT) models, and large language models (LLMs). We evaluated GEC models using a dataset of more than 250,000 examples, including synthetic and human-annotated data. Our results showed that the MT-based approach using M2M100 outperforms others, with a detection rate of 95.82% and a suggestion accuracy of 78.90% in automatic evaluations (AE) and an average score of 3.0 out of 5.0 in manual evaluation (ME) from native speakers for grammar and logical corrections. The rule-based method was effective for spelling errors but failed on complex context-level errors. LLMs -- Gemma 2b and MT5-small -- showed moderate performance. Our work supports use of MT models to enhance GEC in low-resource settings, and we validated these results with Bambara, another West African language.
翻译:语法纠错旨在提升文本质量与可读性。以往研究主要集中于高资源语言,而低资源语言则缺乏稳健的工具。为弥补这一不足,本研究针对西非地区超过五百万人使用的扎尔马语开展语法纠错研究。我们比较了三种方法:基于规则的方法、机器翻译模型以及大语言模型。我们使用包含超过25万条样本的数据集(涵盖合成数据与人工标注数据)对语法纠错模型进行评估。结果显示,基于M2M100的机器翻译方法在自动评估中表现最优,其错误检测率达95.82%,纠错建议准确率为78.90;在母语者对语法及逻辑修正的人工评估中,该方法平均得分达3.0(满分5.0)。基于规则的方法能有效处理拼写错误,但难以应对复杂的语境层面错误。大语言模型——Gemma 2b与MT5-small——表现出中等性能。本研究证实了机器翻译模型在低资源场景下增强语法纠错的可行性,并通过对另一西非语言班巴拉语的实验验证了该结论。