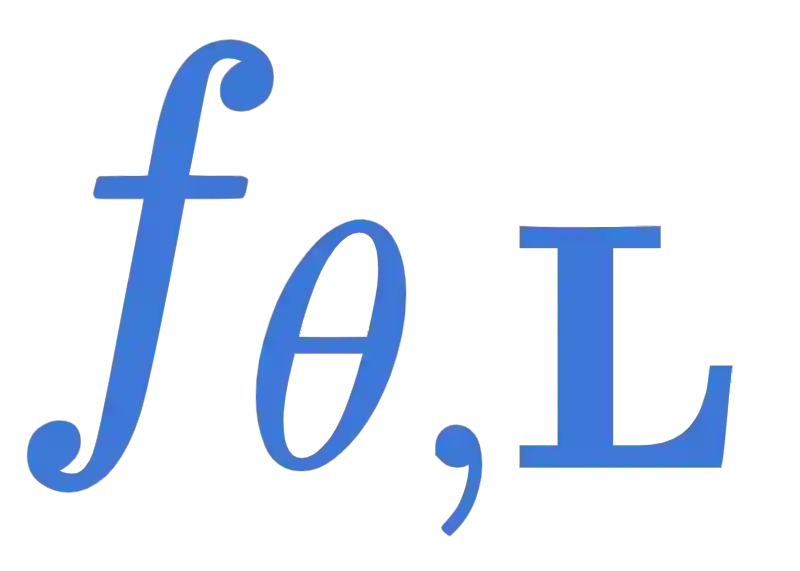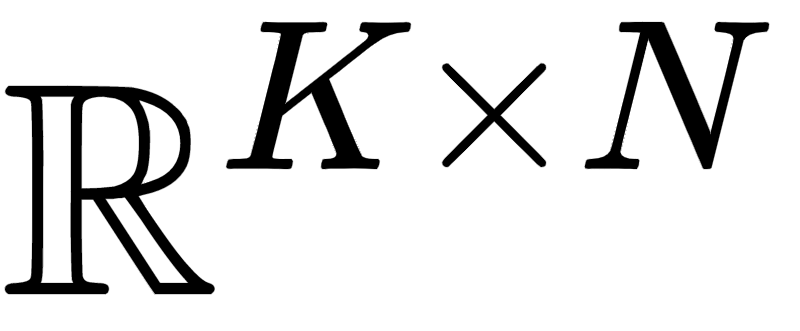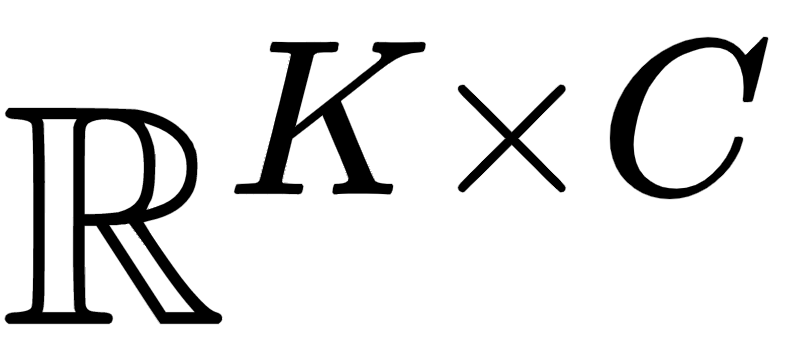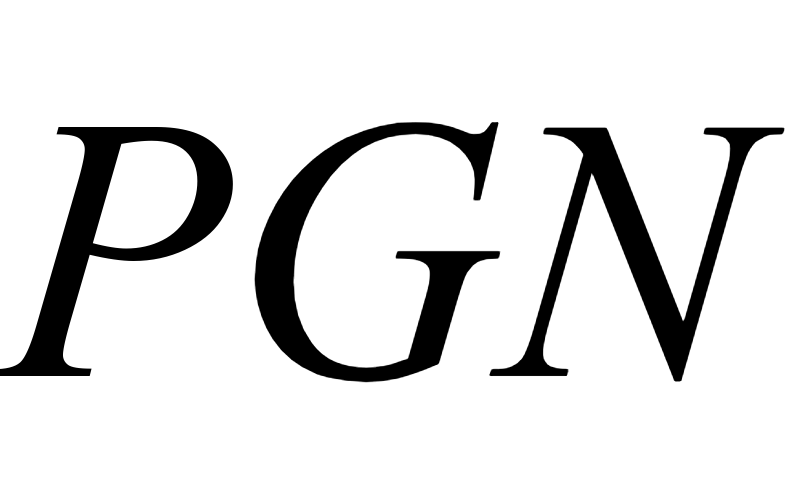With the introduction of the transformer architecture in computer vision, increasing model scale has been demonstrated as a clear path to achieving performance and robustness gains. However, with model parameter counts reaching the billions, classical finetuning approaches are becoming increasingly limiting and even unfeasible when models become hosted as inference APIs, as in NLP. To this end, visual prompt learning, whereby a model is adapted by learning additional inputs, has emerged as a potential solution for adapting frozen and cloud-hosted models: During inference, this neither requires access to the internals of models' forward pass function, nor requires any post-processing. In this work, we propose the Prompt Generation Network (PGN) that generates high performing, input-dependent prompts by sampling from an end-to-end learned library of tokens. We further introduce the "prompt inversion" trick, with which PGNs can be efficiently trained in a latent space but deployed as strictly input-only prompts for inference. We show the PGN is effective in adapting pre-trained models to various new datasets: It surpasses previous methods by a large margin on 12/12 datasets and even outperforms full-finetuning on 5/12, while requiring 100x less parameters.
翻译:随着Transformer架构在计算机视觉领域的引入,增大模型规模已被证明是提升性能与鲁棒性的明确路径。然而,当模型参数量达到数十亿级别时,传统的微调方法逐渐显现局限性,甚至在模型以推理API形式托管(如自然语言处理领域)时变得不可行。为此,视觉提示学习——通过学习额外输入来适配模型——已成为适配冻结或云端托管模型的潜在解决方案:在推理过程中,该方法既无需访问模型前向传播函数内部,也无需任何后处理。本文提出提示生成网络(Prompt Generation Network, PGN),通过从端到端学习的词元库中采样,生成高性能且依赖输入的提示。我们进一步引入“提示反转”技巧,使PGN能够在潜在空间中高效训练,但推理时仅以纯输入提示的形式部署。实验表明,PGN能有效将预训练模型适配到多种新数据集:在12/12个数据集上大幅超越先前方法,甚至在5/12个数据集上超越全参数微调,同时所需参数量减少100倍。