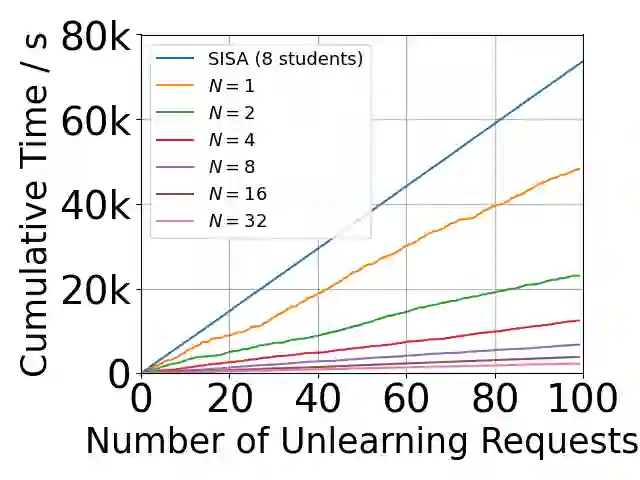
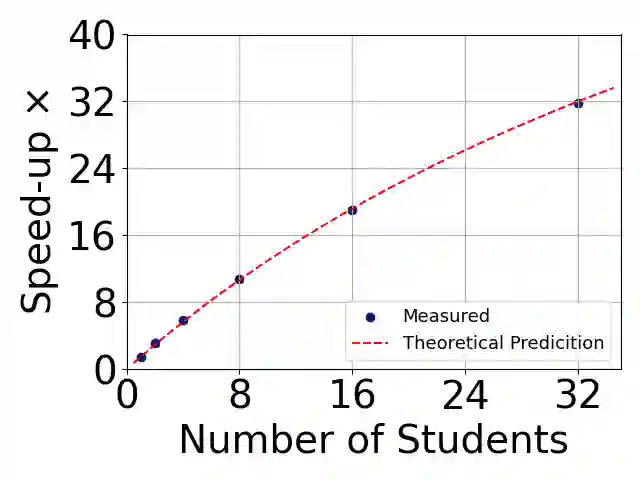
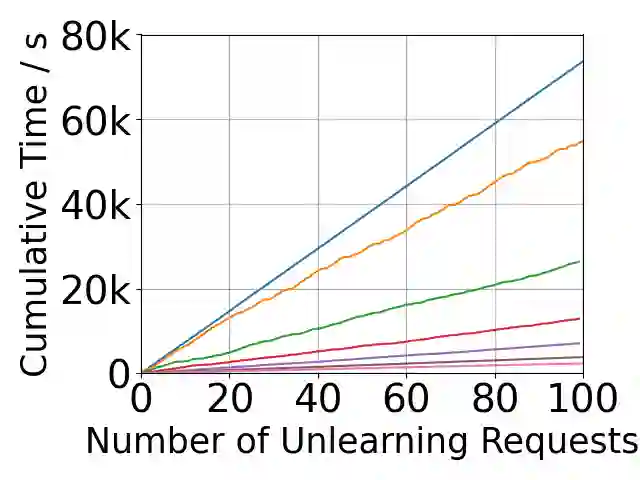
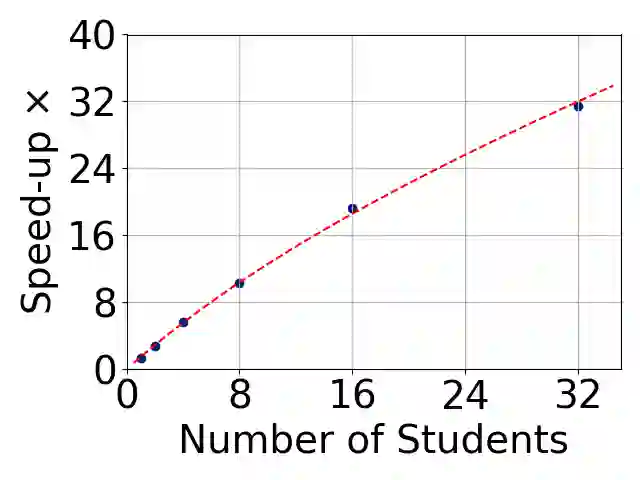
Growing data privacy demands, driven by regulations like GDPR and CCPA, require machine unlearning methods capable of swiftly removing the influence of specific training points. Although verified approaches like SISA, using data slicing and checkpointing, achieve efficient unlearning for single models by reverting to intermediate states, these methods struggle in teacher-student knowledge distillation settings. Unlearning in the teacher typically forces costly, complete student retraining due to pervasive information propagation during distillation. Our primary contribution is PURGE (Partitioned Unlearning with Retraining Guarantee for Ensembles), a novel framework integrating verified unlearning with distillation. We introduce constituent mapping and an incremental multi-teacher strategy that partitions the distillation process, confines each teacher constituent's impact to distinct student data subsets, and crucially maintains data isolation. The PURGE framework substantially reduces retraining overhead, requiring only partial student updates when teacher-side unlearning occurs. We provide both theoretical analysis, quantifying significant speed-ups in the unlearning process, and empirical validation on multiple datasets, demonstrating that PURGE achieves these efficiency gains while maintaining student accuracy comparable to standard baselines.
翻译:随着GDPR和CCPA等法规推动的数据隐私需求日益增长,亟需能够快速消除特定训练点影响的机器遗忘方法。尽管SISA等采用数据切片与检查点机制的可验证方法通过回滚至中间状态,在单一模型中实现了高效遗忘,但这些方法在师生知识蒸馏场景中存在局限。由于蒸馏过程中信息广泛传播,对教师的遗忘操作通常迫使代价高昂的完整学生模型重训练。本研究的主要贡献是提出了PURGE(分区式集成遗忘保障框架),这是一种将可验证遗忘与蒸馏相结合的新型框架。我们引入了成分映射与增量式多教师策略,通过对蒸馏过程进行分区,将各教师成分的影响限制在学生数据的不同子集中,并关键性地保持数据隔离。PURGE框架显著降低了重训练开销,当教师端发生遗忘时仅需对学生模型进行局部更新。我们提供了理论分析以量化遗忘过程的加速效果,并在多个数据集上进行实证验证,结果表明PURGE在保持学生模型精度与标准基线相当的同时,实现了显著的效率提升。