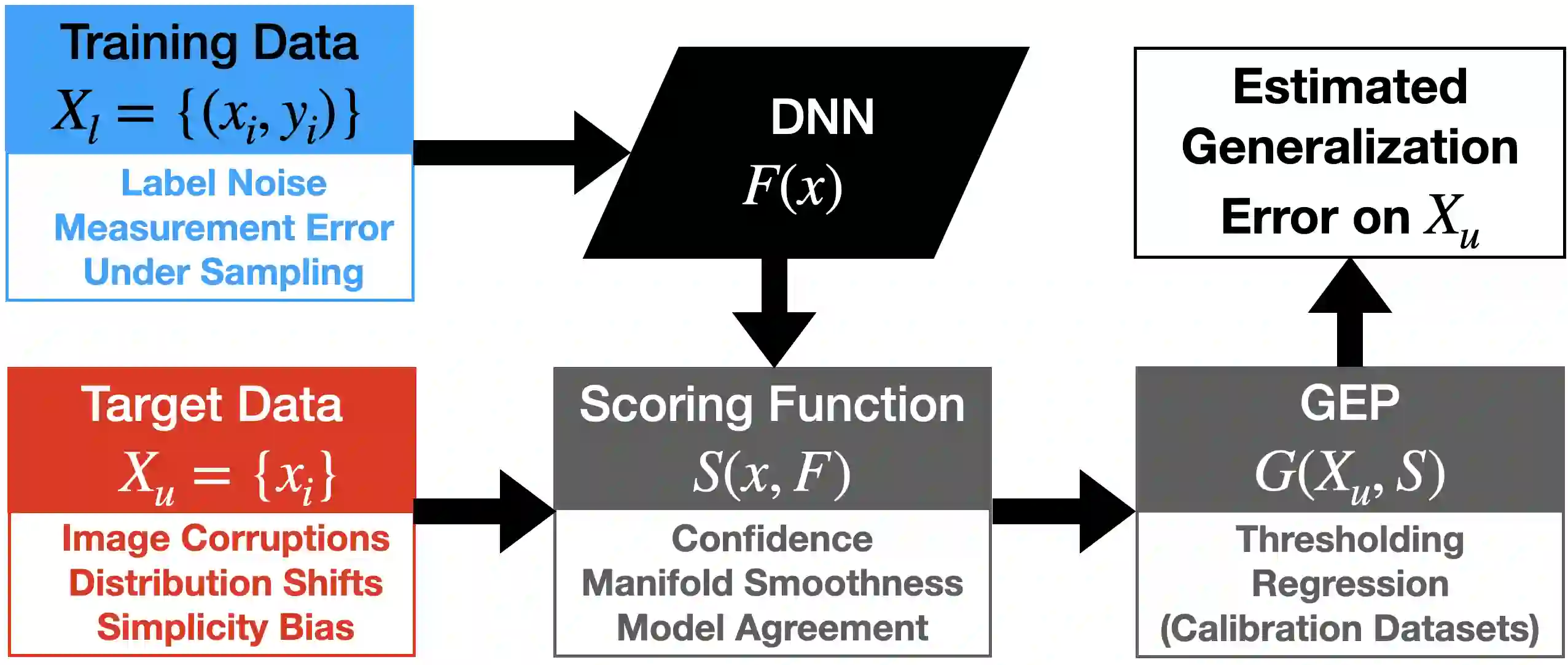
Generalization error predictors (GEPs) aim to predict model performance on unseen distributions by deriving dataset-level error estimates from sample-level scores. However, GEPs often utilize disparate mechanisms (e.g., regressors, thresholding functions, calibration datasets, etc), to derive such error estimates, which can obfuscate the benefits of a particular scoring function. Therefore, in this work, we rigorously study the effectiveness of popular scoring functions (confidence, local manifold smoothness, model agreement), independent of mechanism choice. We find, absent complex mechanisms, that state-of-the-art confidence- and smoothness- based scores fail to outperform simple model-agreement scores when estimating error under distribution shifts and corruptions. Furthermore, on realistic settings where the training data has been compromised (e.g., label noise, measurement noise, undersampling), we find that model-agreement scores continue to perform well and that ensemble diversity is important for improving its performance. Finally, to better understand the limitations of scoring functions, we demonstrate that simplicity bias, or the propensity of deep neural networks to rely upon simple but brittle features, can adversely affect GEP performance. Overall, our work carefully studies the effectiveness of popular scoring functions in realistic settings and helps to better understand their limitations.
翻译:泛化误差预测器(GEP)旨在通过从样本级评分推导数据集级误差估计,来预测模型在未见分布上的性能。然而,GEP通常采用不同机制(如回归器、阈值函数、校准数据集等)来推导此类误差估计,这可能掩盖特定评分函数的优势。因此,本研究严格考察了主流评分函数(置信度、局部流形平滑度、模型一致性)的有效性,且独立于机制选择。我们发现,在缺乏复杂机制的情况下,当估计分布迁移和污染下的误差时,基于置信度和平滑度的最新评分函数未能超越简单的模型一致性评分。此外,在训练数据存在缺陷(如标签噪声、测量噪声、欠采样)的现实场景中,模型一致性评分持续表现良好,且集成多样性对其性能提升至关重要。最后,为更深入理解评分函数的局限性,我们证明简单性偏差(即深度神经网络倾向于依赖简单但脆弱的特征)会对GEP性能产生不利影响。总体而言,本研究细致考察了主流评分函数在现实场景中的有效性,并有助于更深入地理解其局限性。