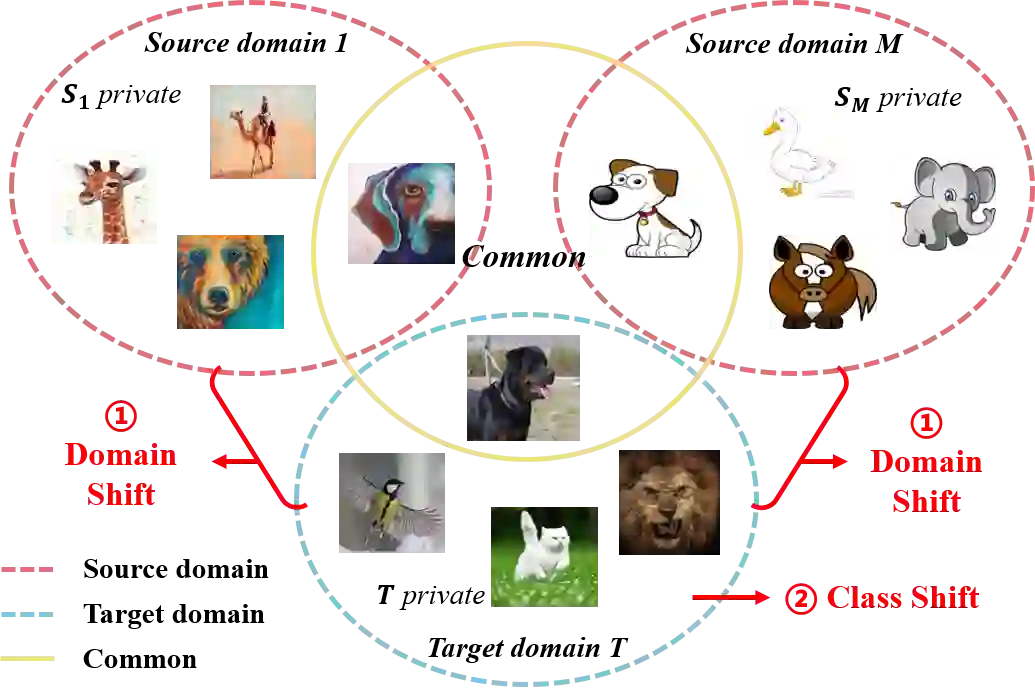
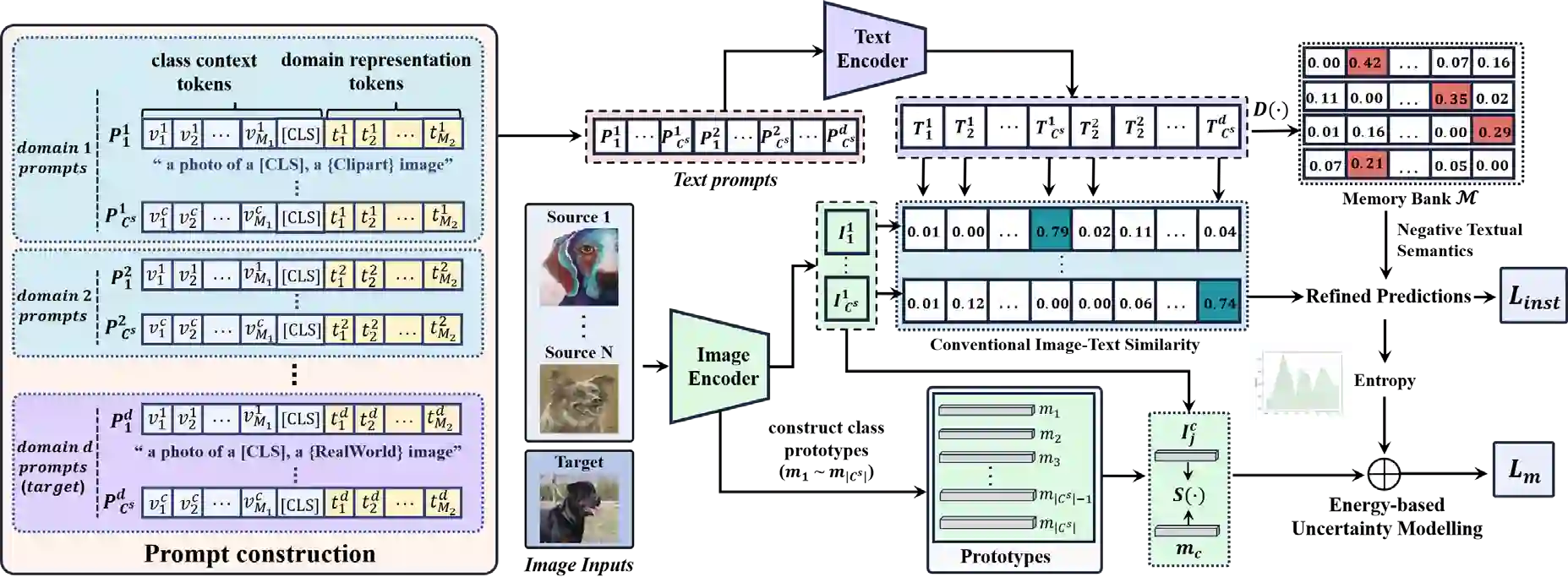
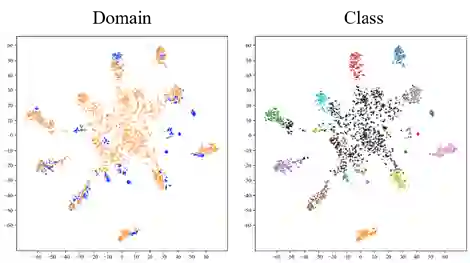
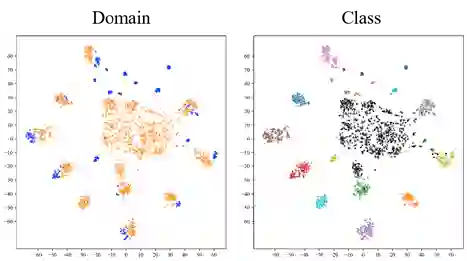
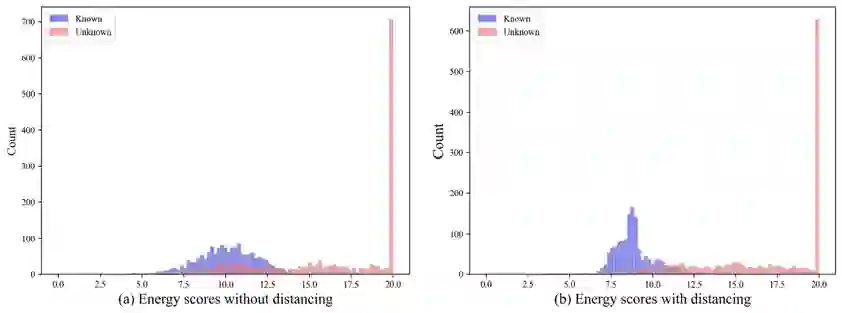
Universal Multi-source Domain Adaptation (UniMDA) transfers knowledge from multiple labeled source domains to an unlabeled target domain under domain shifts (different data distribution) and class shifts (unknown target classes). Existing solutions focus on excavating image features to detect unknown samples, ignoring abundant information contained in textual semantics. In this paper, we propose an Adaptive Prompt learning with Negative textual semantics and uncErtainty modeling method based on Contrastive Language-Image Pre-training (APNE-CLIP) for UniMDA classification tasks. Concretely, we utilize the CLIP with adaptive prompts to leverage textual information of class semantics and domain representations, helping the model identify unknown samples and address domain shifts. Additionally, we design a novel global instance-level alignment objective by utilizing negative textual semantics to achieve more precise image-text pair alignment. Furthermore, we propose an energy-based uncertainty modeling strategy to enlarge the margin distance between known and unknown samples. Extensive experiments demonstrate the superiority of our proposed method.
翻译:通用多源域适应(UniMDA)旨在将多个带标签源域的知识迁移至无标签目标域,同时应对域偏移(不同数据分布)与类别偏移(未知目标类别)。现有方法主要关注挖掘图像特征以检测未知样本,却忽略了文本语义中包含的丰富信息。本文提出一种基于对比语言-图像预训练(CLIP)的自适应提示学习与负文本语义及不确定性建模方法(APNE-CLIP),用于UniMDA分类任务。具体而言,我们利用带有自适应提示的CLIP模型,通过类别语义与域表示的文本信息辅助模型识别未知样本并处理域偏移问题。同时,设计一种新颖的全局实例级对齐目标,利用负文本语义实现更精准的图像-文本对对齐。此外,提出一种基于能量的不确定性建模策略,以增大已知样本与未知样本间的间隔距离。大量实验验证了所提方法的优越性。