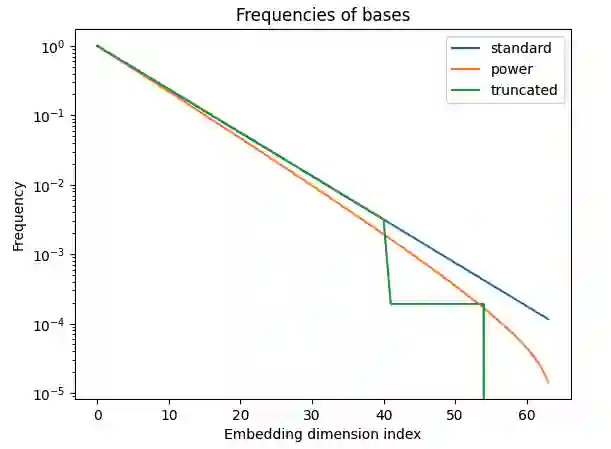
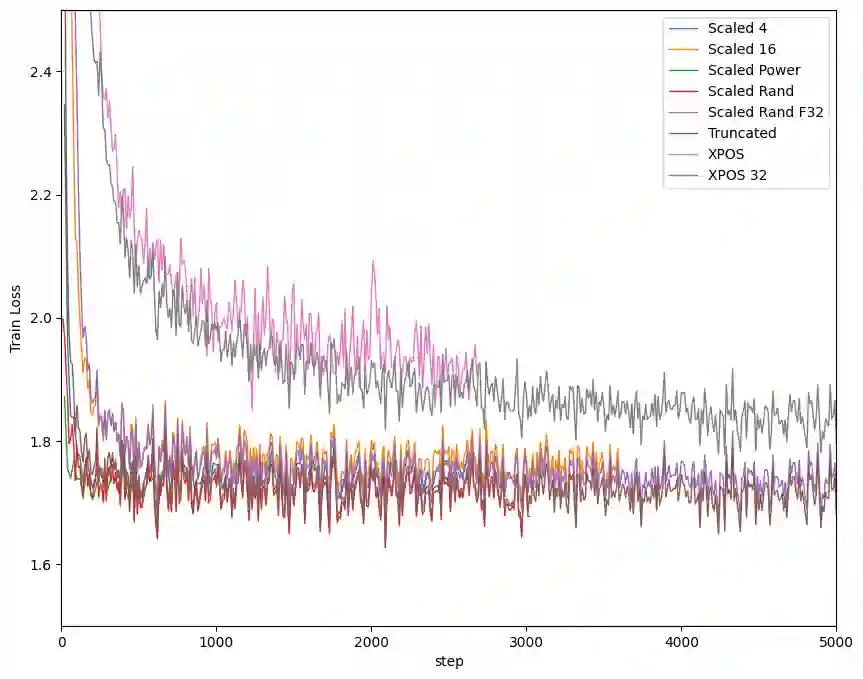
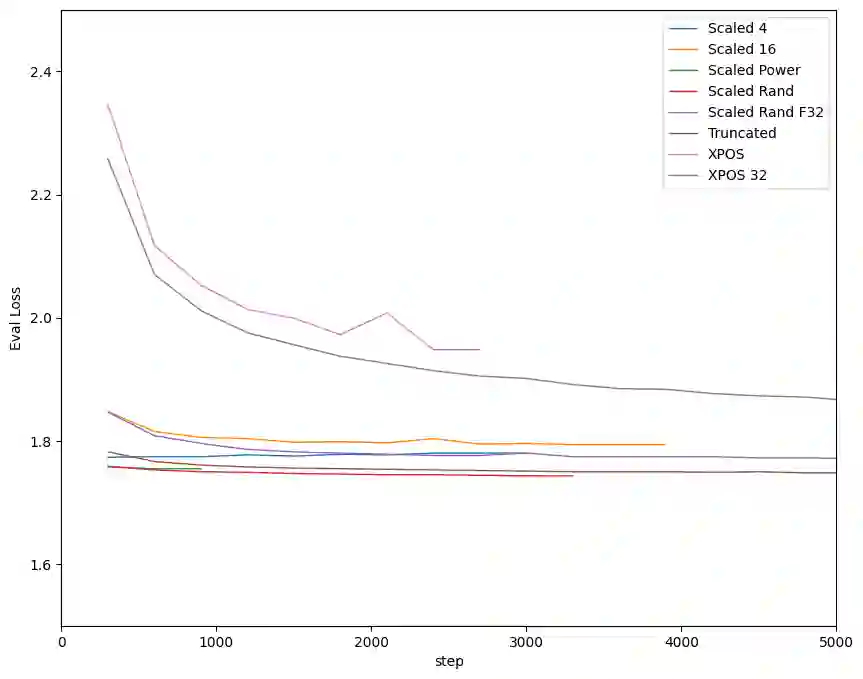
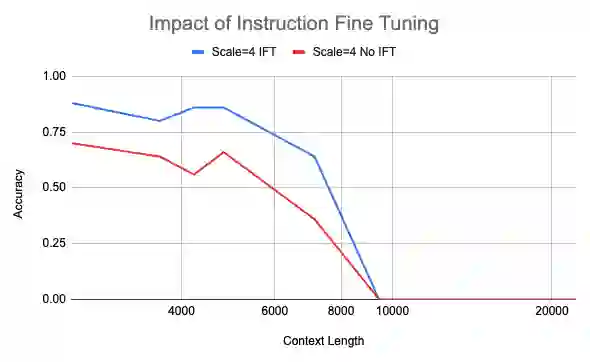
Modern large language models (LLMs) that rely on attention mechanisms are typically trained with fixed context lengths which enforce upper limits on the length of input sequences that they can handle at evaluation time. To use these models on sequences longer than the train-time context length, one might employ techniques from the growing family of context length extrapolation methods -- most of which focus on modifying the system of positional encodings used in the attention mechanism to indicate where tokens or activations are located in the input sequence. We conduct a wide survey of existing methods of context length extrapolation on a base LLaMA or LLaMA 2 model, and introduce some of our own design as well -- in particular, a new truncation strategy for modifying the basis for the position encoding. We test these methods using three new evaluation tasks (FreeFormQA, AlteredNumericQA, and LongChat-Lines) as well as perplexity, which we find to be less fine-grained as a measure of long context performance of LLMs. We release the three tasks publicly as datasets on HuggingFace. We discover that linear scaling is the best method for extending context length, and show that further gains can be achieved by using longer scales at evaluation time. We also discover promising extrapolation capabilities in the truncated basis. To support further research in this area, we release three new 13B parameter long-context models which we call Giraffe: 4k and 16k context models trained from base LLaMA-13B, and a 32k context model trained from base LLaMA2-13B. We also release the code to replicate our results.
翻译:现代依赖注意力机制的大型语言模型(LLMs)通常在固定上下文长度下训练,这限制了它们在评估时所能处理的输入序列长度上限。为在超过训练时上下文长度的序列上使用这些模型,人们可采用日益增长的上下文长度外推方法家族中的技术——这些方法大多聚焦于修改注意力机制中使用的**位置编码系统**,以指示输入序列中令牌或激活值的位置。我们对基于LLaMA或LLaMA 2基础模型的现有上下文长度外推方法进行了广泛调研,并引入了一些自主设计——特别是用于修改位置编码基底的**新截断策略**。我们使用三项新评估任务(FreeFormQA、AlteredNumericQA和LongChat-Lines)以及困惑度指标测试了这些方法,并发现困惑度作为衡量LLMs长上下文性能的指标不够精细。我们已在HuggingFace上公开发布了这三项任务的数据集。我们发现**线性缩放**是扩展上下文长度的最佳方法,并表明在评估时使用更长的缩放比例可进一步提升性能。此外,我们在截断基底中发现了有前景的外推能力。为支持该领域进一步研究,我们发布了三个新的13B参数长上下文模型,命名为Giraffe:基于LLaMA-13B训练的4k和16k上下文模型,以及基于LLaMA2-13B训练的32k上下文模型。我们还发布了可复现结果的代码。