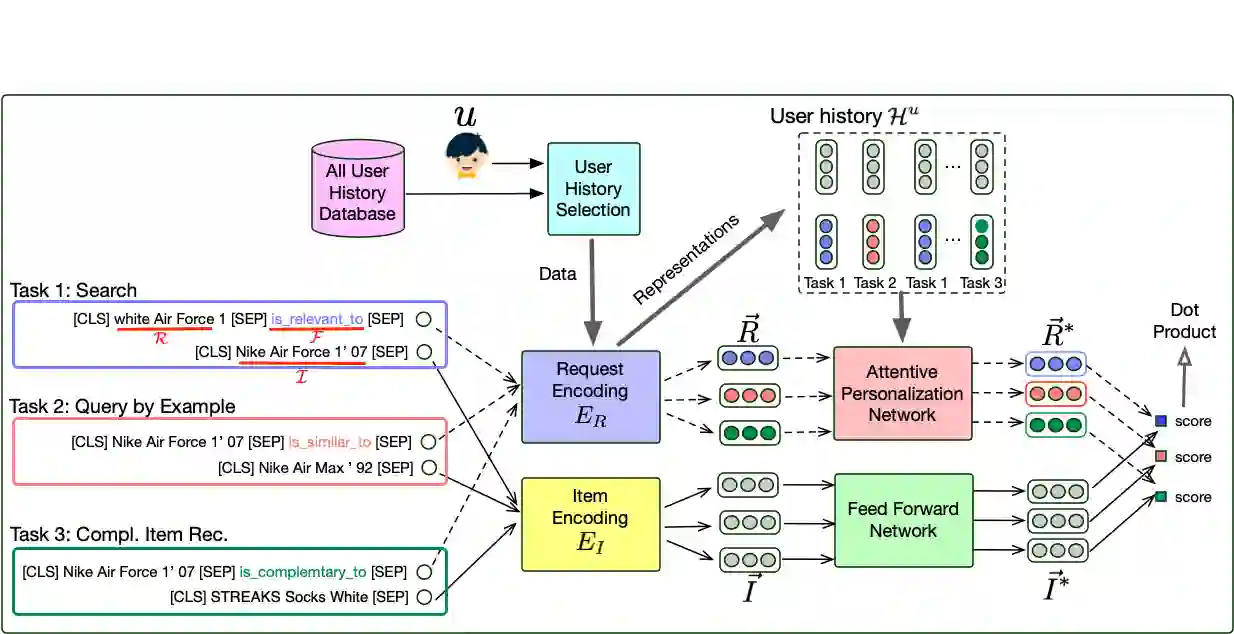
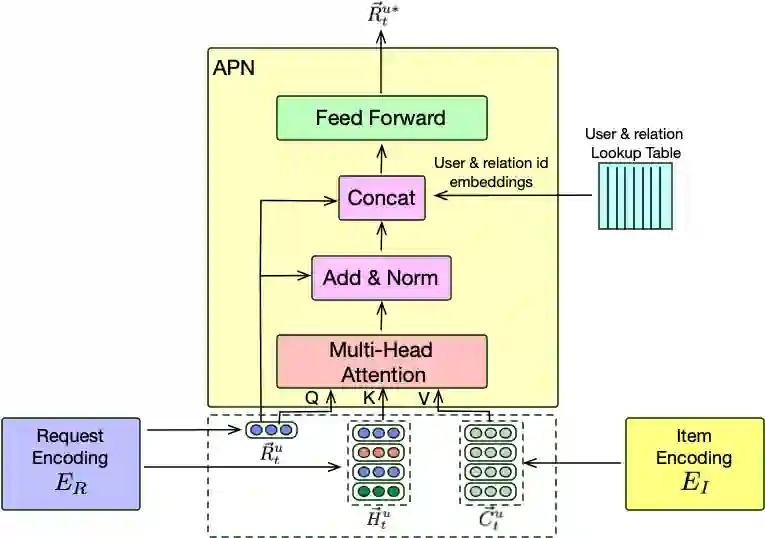
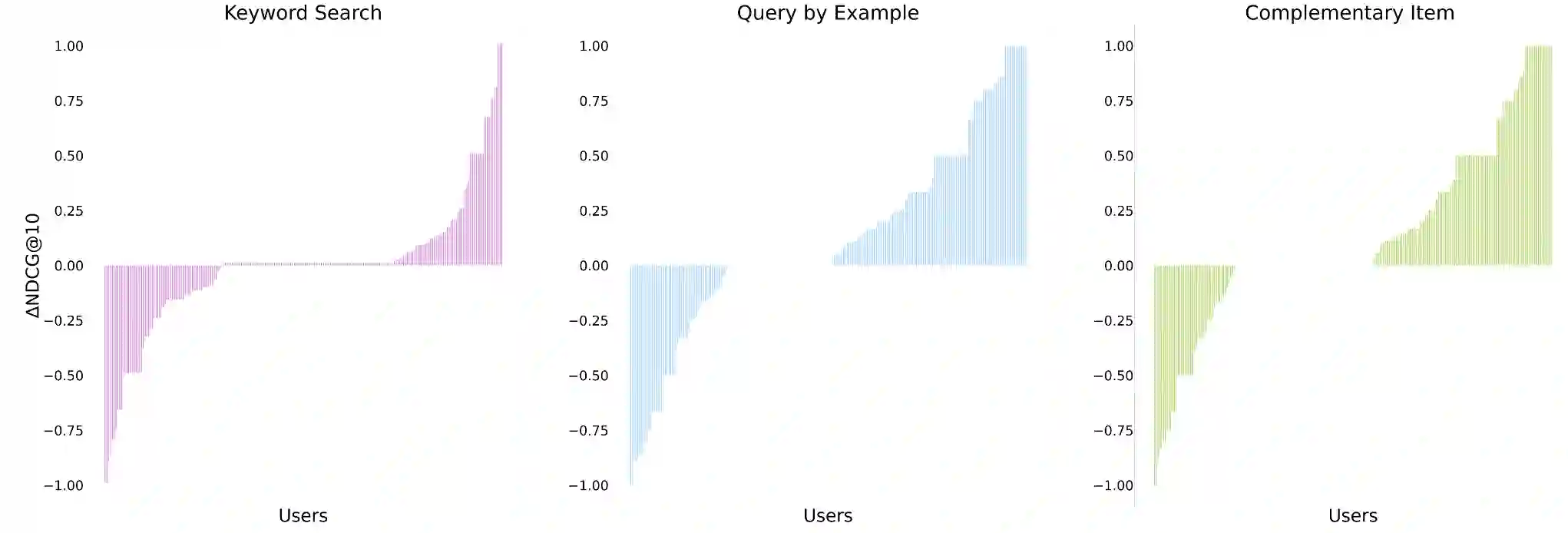
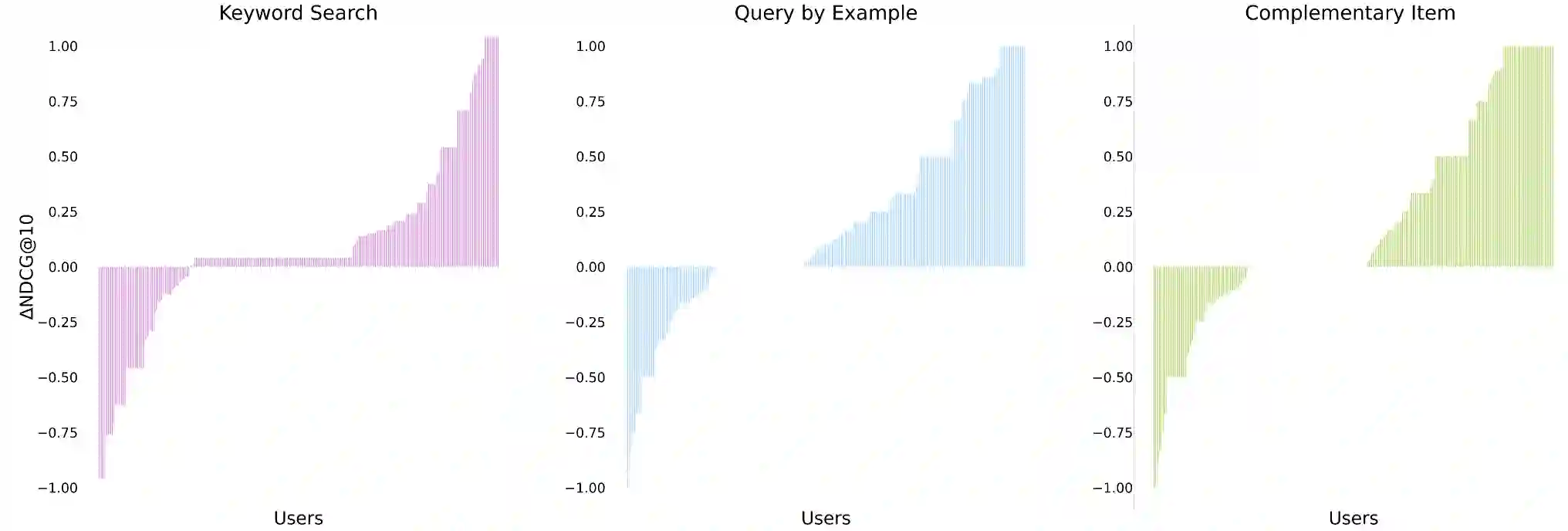
Developing a universal model that can efficiently and effectively respond to a wide range of information access requests -- from retrieval to recommendation to question answering -- has been a long-lasting goal in the information retrieval community. This paper argues that the flexibility, efficiency, and effectiveness brought by the recent development in dense retrieval and approximate nearest neighbor search have smoothed the path towards achieving this goal. We develop a generic and extensible dense retrieval framework, called \framework, that can handle a wide range of (personalized) information access requests, such as keyword search, query by example, and complementary item recommendation. Our proposed approach extends the capabilities of dense retrieval models for ad-hoc retrieval tasks by incorporating user-specific preferences through the development of a personalized attentive network. This allows for a more tailored and accurate personalized information access experience. Our experiments on real-world e-commerce data suggest the feasibility of developing universal information access models by demonstrating significant improvements even compared to competitive baselines specifically developed for each of these individual information access tasks. This work opens up a number of fundamental research directions for future exploration.
翻译:开发一个能够高效且有效地响应各种信息访问请求(从检索到推荐再到问答)的通用模型,一直是信息检索领域的长期目标。本文认为,近年来稠密检索和近似最近邻搜索的发展所带来的灵活性、效率和有效性,为实现这一目标铺平了道路。我们开发了一个名为\framework的通用可扩展稠密检索框架,能够处理广泛(个性化)的信息访问请求,例如关键词搜索、按例查询和互补商品推荐。我们提出的方法通过开发个性化注意力网络融入用户特定偏好,从而扩展了稠密检索模型在即席检索任务中的能力。这实现了更加定制化和精准的个性化信息访问体验。我们在真实电子商务数据上的实验表明,即使与针对这些信息访问任务各自专门开发的竞争性基线相比,我们的方法也展现出显著改进,从而证明了开发通用信息访问模型的可行性。这项工作为未来的探索开辟了许多基础研究方向。