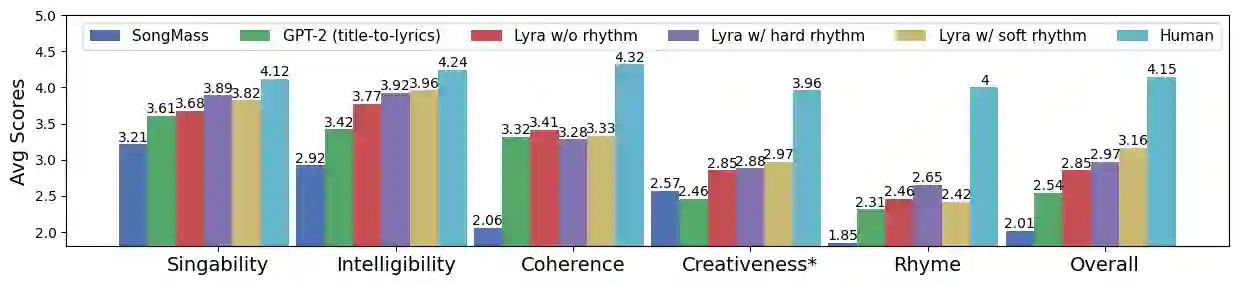
Automatic melody-to-lyric generation is a task in which song lyrics are generated to go with a given melody. It is of significant practical interest and more challenging than unconstrained lyric generation as the music imposes additional constraints onto the lyrics. The training data is limited as most songs are copyrighted, resulting in models that underfit the complicated cross-modal relationship between melody and lyrics. In this work, we propose a method for generating high-quality lyrics without training on any aligned melody-lyric data. Specifically, we design a hierarchical lyric generation framework that first generates a song outline and second the complete lyrics. The framework enables disentanglement of training (based purely on text) from inference (melody-guided text generation) to circumvent the shortage of parallel data. We leverage the segmentation and rhythm alignment between melody and lyrics to compile the given melody into decoding constraints as guidance during inference. The two-step hierarchical design also enables content control via the lyric outline, a much-desired feature for democratizing collaborative song creation. Experimental results show that our model can generate high-quality lyrics that are more on-topic, singable, intelligible, and coherent than strong baselines, for example SongMASS, a SOTA model trained on a parallel dataset, with a 24% relative overall quality improvement based on human ratings. O
翻译:自动旋律到歌词生成是一项任务,旨在为给定的旋律生成配套的歌词。该任务具有重要的实际意义,且比无约束的歌词生成更具挑战性,因为音乐对歌词施加了额外限制。由于大多数歌曲受版权保护,训练数据有限,导致模型难以充分拟合旋律与歌词之间复杂的跨模态关系。在这项工作中,我们提出了一种无需在任意对齐的旋律-歌词数据上训练即可生成高质量歌词的方法。具体而言,我们设计了一个分层歌词生成框架,该框架首先生成歌曲大纲,其次生成完整歌词。该框架实现了训练(完全基于文本)与推理(旋律引导的文本生成)的解耦,从而规避了平行数据短缺的问题。我们利用旋律与歌词之间的分段和节奏对齐,将给定旋律编译为推理过程中的解码约束作为引导。这种两步分层设计还通过歌词大纲实现了内容控制,这是民主化协作歌曲创作中非常受欢迎的功能。实验结果表明,与强基线模型(例如在平行数据集上训练的最先进模型SongMASS)相比,我们的模型能够生成更切题、易唱、易懂且连贯的高质量歌词,基于人类评分的总体质量相对提升24%。