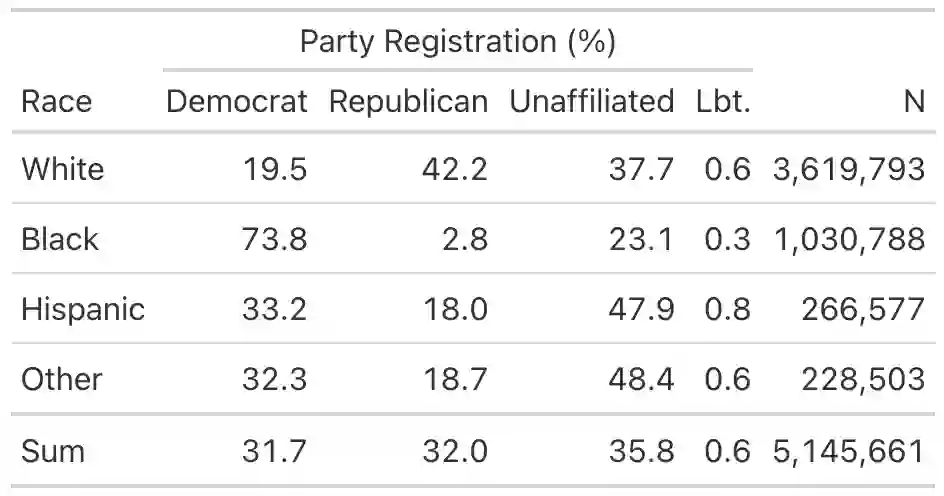
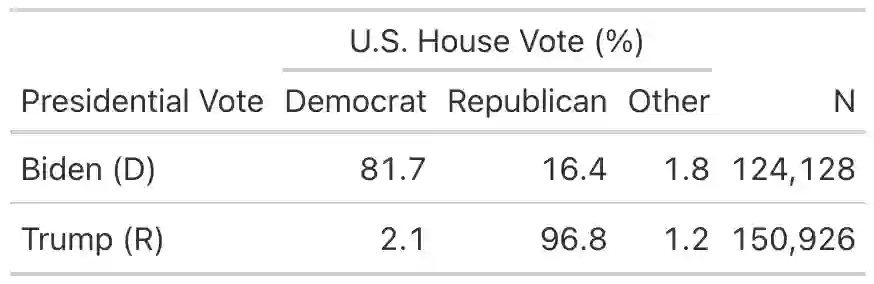
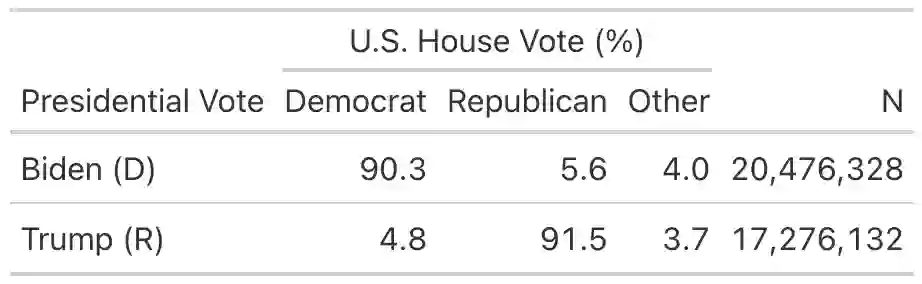
Estimating conditional means using only the marginal means available from aggregate data is commonly known as the ecological inference problem (EI). We provide a reassessment of EI, including a new formalization of identification conditions and a demonstration of how these conditions fail to hold in common cases. The identification conditions reveal that, similar to causal inference, credible ecological inference requires controlling for confounders. The aggregation process itself creates additional structure to assist in estimation by restricting the conditional expectation function to be linear in the predictor variable. A linear model perspective also clarifies the differences between the EI methods commonly used in the literature, and when they lead to ecological fallacies. We provide an overview of new methodology which builds on both the identification and linearity results to flexibly control for confounders and yield improved ecological inferences. Finally, using datasets for common EI problems in which the ground truth is fortuitously observed, we show that, while covariates can help, all methods are prone to overestimating both racial polarization and nationalized partisan voting.
翻译:仅利用聚合数据中可得的边际均值来估计条件均值的问题,通常被称为生态推断问题(EI)。本文对生态推断进行了重新评估,包括对识别条件的新形式化,并论证了这些条件在常见情况下如何无法成立。识别条件表明,与因果推断类似,可靠的生态推断需要控制混杂因素。聚合过程本身通过限制条件期望函数在预测变量上为线性,创造了额外的结构以辅助估计。线性模型的视角也澄清了文献中常用生态推断方法之间的差异,以及它们何时会导致生态谬误。我们概述了基于识别条件和线性结果的新方法,该方法能够灵活控制混杂因素并产生改进的生态推断。最后,利用在常见生态推断问题中幸运地观测到真实情况的数据集,我们表明,尽管协变量可能有所帮助,但所有方法都倾向于高估种族两极分化和全国性党派投票的程度。