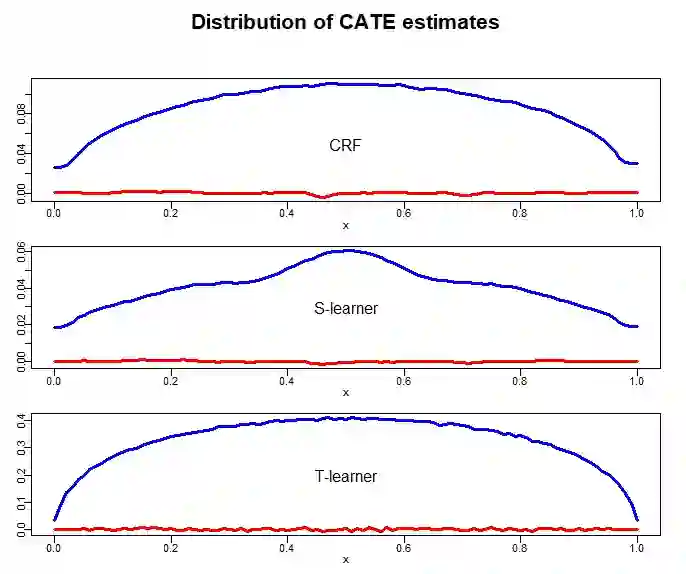
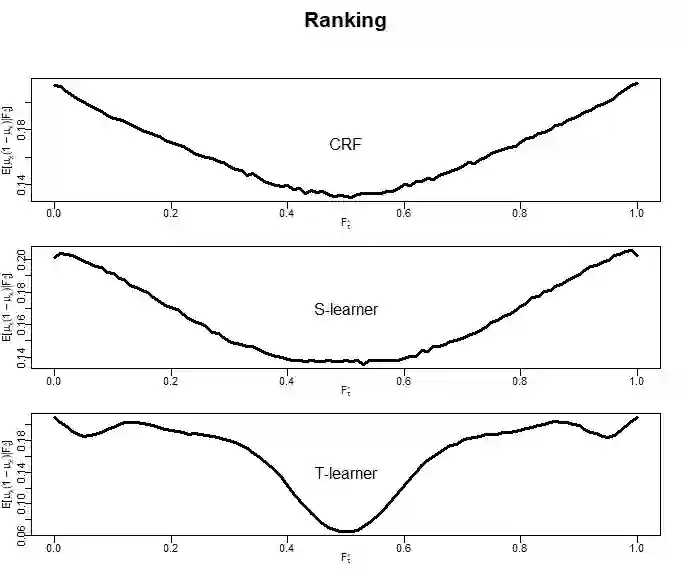
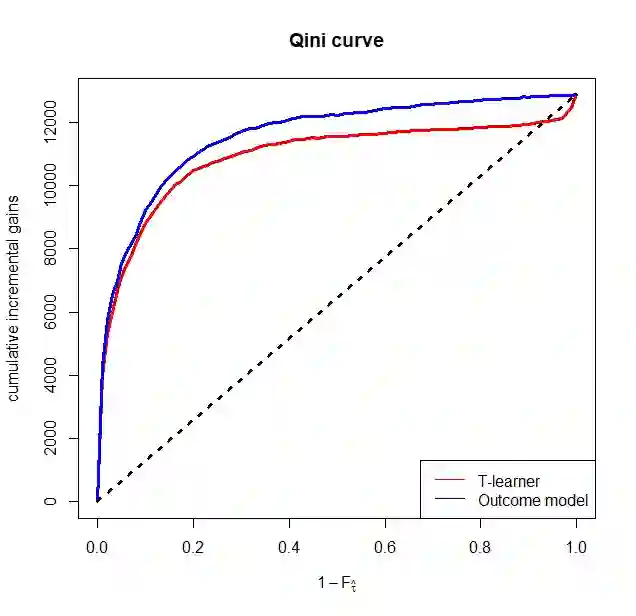
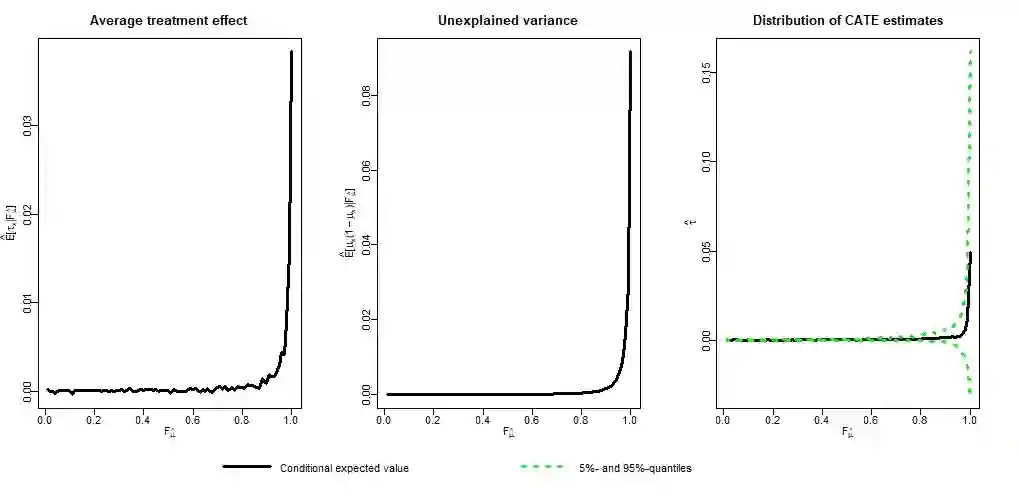
There are various applications, where companies need to decide to which individuals they should best allocate treatment. To support such decisions, uplift models are applied to predict treatment effects on an individual level. Based on the predicted treatment effects, individuals can be ranked and treatment allocation can be prioritized according to this ranking. An implicit assumption, which has not been doubted in the previous uplift modeling literature, is that this treatment prioritization approach tends to bring individuals with high treatment effects to the top and individuals with low treatment effects to the bottom of the ranking. In our research, we show that heteroskedastictity in the training data can cause a bias of the uplift model ranking: individuals with the highest treatment effects can get accumulated in large numbers at the bottom of the ranking. We explain theoretically how heteroskedasticity can bias the ranking of uplift models and show this process in a simulation and on real-world data. We argue that this problem of ranking bias due to heteroskedasticity might occur in many real-world applications and requires modification of the treatment prioritization to achieve an efficient treatment allocation.
翻译:在众多应用场景中,企业需要决定哪些个体最适合接受干预。为支持此类决策,提升模型被用于预测个体层面的干预效果。基于预测的干预效果,可对个体进行排序,并根据该排序确定干预分配的优先级。先前提升建模文献中一个未被质疑的隐含假设是:这种干预优先级排序方法倾向于将高干预效果的个体排在序列顶端,而低干预效果的个体则排在序列末端。本研究表明,训练数据中的异方差性可能导致提升模型排序出现偏差:最高干预效果的个体可能大量聚集在排序末端。我们从理论层面解释了异方差性如何导致提升模型排序偏差,并通过仿真实验和真实数据验证了这一过程。我们认为,异方差性引发的排序偏差问题可能出现在众多实际应用中,需要改进干预优先级排序策略以实现高效的干预分配。